

mapreduce编程实例
编程语言及工具
描述
Mapreduce初析
Mapreduce是一个计算框架,既然是做计算的框架,那么表现形式就是有个输入(input),mapreduce操作这个输入(input),通过本身定义好的计算模型,得到一个输出(output),这个输出就是我们所需要的结果。
我们要学习的就是这个计算模型的运行规则。在运行一个mapreduce计算任务时候,任务过程被分为两个阶段:map阶段和reduce阶段,每个阶段都是用键值对(key/value)作为输入(input)和输出(output)。而程序员要做的就是定义好这两个阶段的函数:map函数和reduce函数。
mapreduce编程实例
1、数据去重
“数据去重”主要是为了掌握和利用并行化思想来对数据进行有意义的筛选。统计大数据集上的数据种类个数、从网站日志中计算访问地等这些看似庞杂的任务都会涉及数据去重。下面就进入这个实例的MapReduce程序设计。
1.1 实例描述
对数据文件中的数据进行去重。数据文件中的每行都是一个数据。
样例输入如下所示:
1)file1:
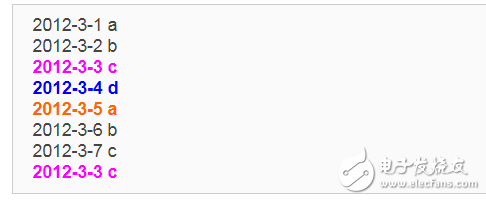
2)file2:

样例输出如下所示:

1.2 设计思路
数据去重的最终目标是让原始数据中出现次数超过一次的数据在输出文件中只出现一次。我们自然而然会想到将同一个数据的所有记录都交给一台reduce机器,无论这个数据出现多少次,只要在最终结果中输出一次就可以了。具体就是reduce的输入应该以数据作为key,而对value-list则没有要求。当reduce接收到一个《key,value-list》时就直接将key复制到输出的key中,并将value设置成空值。
在MapReduce流程中,map的输出《key,value》经过shuffle过程聚集成《key,value- list》后会交给reduce。所以从设计好的reduce输入可以反推出map的输出key应为数据,value任意。继续反推,map输出数 据的key为数据,而在这个实例中每个数据代表输入文件中的一行内容,所以map阶段要完成的任务就是在采用Hadoop默认的作业输入方式之后,将 value设置为key,并直接输出(输出中的value任意)。map中的结果经过shuffle过程之后交给reduce。reduce阶段不会管每 个key有多少个value,它直接将输入的key复制为输出的key,并输出就可以了(输出中的value被设置成空了)。
1.3 程序代码
程序代码如下所示:
package com.hebut.mr;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Dedup {
//map将输入中的value复制到输出数据的key上,并直接输出
public static class Map extends Mapper《Object,Text,Text,Text》{
private static Text line=new Text();//每行数据
//实现map函数
public void map(Object key,Text value,Context context)
throws IOException,InterruptedException{
line=value;
context.write(line, new Text(“”));
}
}
//reduce将输入中的key复制到输出数据的key上,并直接输出
public static class Reduce extends Reducer《Text,Text,Text,Text》{
//实现reduce函数
public void reduce(Text key,Iterable《Text》 values,Context context)
throws IOException,InterruptedException{
context.write(key, new Text(“”));
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
//这句话很关键
conf.set(“mapred.job.tracker”, “192.168.1.2:9001”);
String[] ioArgs=new String[]{“dedup_in”,“dedup_out”};
String[] otherArgs = new GenericOptionsParser(conf, ioArgs).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println(“Usage: Data Deduplication 《in》 《out》”);
System.exit(2);
}
Job job = new Job(conf, “Data Deduplication”);
job.setJarByClass(Dedup.class);
//设置Map、Combine和Reduce处理类
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
//设置输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//设置输入和输出目录
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
} }
1.4 代码结果
1)准备测试数据
通过Eclipse下面的“DFS Locations”在“/user/hadoop”目录下创建输入文件“dedup_in”文件夹(备注:“dedup_out”不需要创建。)如图1.4-1所示,已经成功创建。
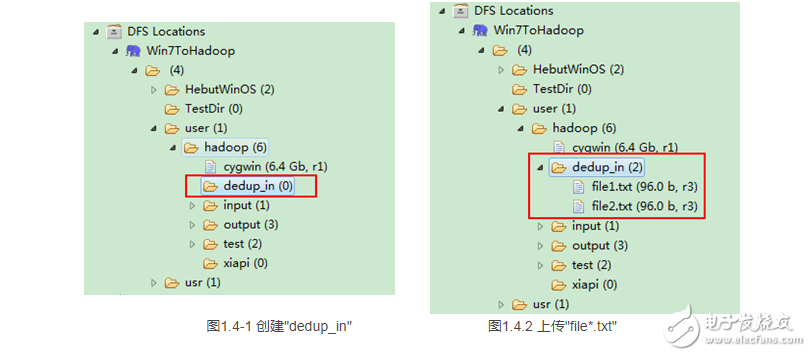
然后在本地建立两个txt文件,通过Eclipse上传到“/user/hadoop/dedup_in”文件夹中,两个txt文件的内容如“实例描述”那两个文件一样。如图1.4-2所示,成功上传之后。
从SecureCRT远处查看“Master.Hadoop”的也能证实我们上传的两个文件。

查看两个文件的内容如图1.4-3所示:
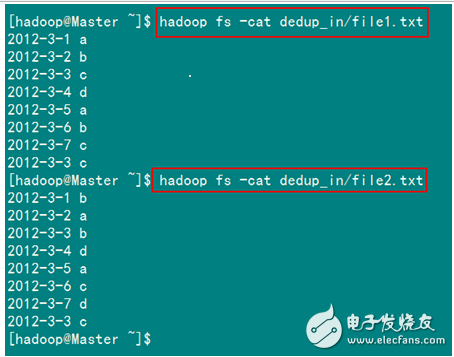
2)查看运行结果
这时我们右击Eclipse 的“DFS Locations”中“/user/hadoop”文件夹进行刷新,这时会发现多出一个“dedup_out”文件夹,且里面有3个文件,然后打开双 其“part-r-00000”文件,会在Eclipse中间把内容显示出来。如图1.4-4所示。
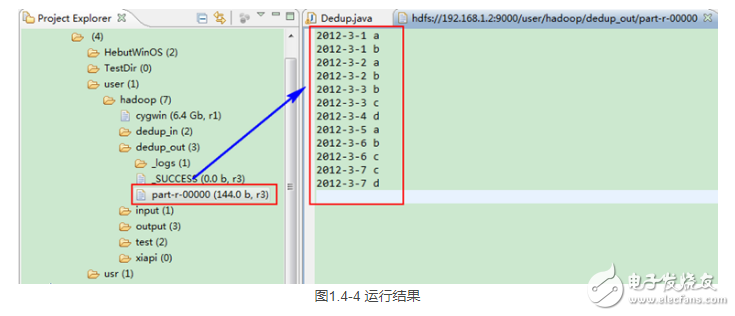
此时,你可以对比一下和我们之前预期的结果是否一致。
#p##e#
2、数据排序
“数据排序”是许多实际任务执行时要完成的第一项工作,比如学生成绩评比、数据建立索引等。这个实例和数据去重类似,都是先对原始数据进行初步处理,为进一步的数据操作打好基础。下面进入这个示例。
2.1 实例描述
对输入文件中数据进行排序。输入文件中的每行内容均为一个数字,即一个数据。要求在输出中每行有两个间隔的数字,其中,第一个代表原始数据在原始数据集中的位次,第二个代表原始数据。
样例输入:
1)file1:
2
32
654
32
15
756
65223
2)file2:
5956
22
650
92
3)file3:
26
54
6
样例输出:
1 2
2 6
3 15
4 22
5 26
6 32
7 32
8 54
9 92
10 650
11 654
12 756
13 5956
14 65223
2.2 设计思路
这个实例仅仅要求对输入数据进行排序,熟悉MapReduce过程的读者会很快想到在MapReduce过程中就有排序,是否可以利用这个默认的排序,而不需要自己再实现具体的排序呢?答案是肯定的。
但是在使用之前首先需要了解它的默认排序规则。它是按照key值进行排序的,如果key为封装int的IntWritable类型,那么MapReduce按照数字大小对key排序,如果key为封装为String的Text类型,那么MapReduce按照字典顺序对字符串排序。
了解了这个细节,我们就知道应该使用封装int的IntWritable型数据结构了。也就是在map中将读入的数据转化成 IntWritable型,然后作为key值输出(value任意)。reduce拿到《key,value-list》之后,将输入的 key作为value输出,并根据value-list中元素的个数决定输出的次数。输出的key(即代码中的linenum)是一个全局变量,它统计当前key的位次。需要注意的是这个程序中没有配置Combiner,也就是在MapReduce过程中不使用Combiner。这主要是因为使用map和reduce就已经能够完成任务了。
2.3 程序代码
程序代码如下所示:
package com.hebut.mr;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Sort {
//map将输入中的value化成IntWritable类型,作为输出的key
public static class Map extends
Mapper《Object,Text,IntWritable,IntWritable》{
private static IntWritable data=new IntWritable();
//实现map函数
public void map(Object key,Text value,Context context)
throws IOException,InterruptedException{
String line=value.toString();
data.set(Integer.parseInt(line));
context.write(data, new IntWritable(1));
}
}
//reduce将输入中的key复制到输出数据的key上,
//然后根据输入的value-list中元素的个数决定key的输出次数
//用全局linenum来代表key的位次
public static class Reduce extends
Reducer《IntWritable,IntWritable,IntWritable,IntWritable》{
private static IntWritable linenum = new IntWritable(1);
//实现reduce函数
public void reduce(IntWritable key,Iterable《IntWritable》 values,Context context)
throws IOException,InterruptedException{
for(IntWritable val:values){
context.write(linenum, key);
linenum = new IntWritable(linenum.get()+1);
}
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
//这句话很关键
conf.set(“mapred.job.tracker”, “192.168.1.2:9001”);
String[] ioArgs=new String[]{“sort_in”,“sort_out”};
String[] otherArgs = new GenericOptionsParser(conf, ioArgs).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println(“Usage: Data Sort 《in》 《out》”);
System.exit(2);
}
Job job = new Job(conf, “Data Sort”);
job.setJarByClass(Sort.class);
//设置Map和Reduce处理类
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
//设置输出类型
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
//设置输入和输出目录
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
2.4 代码结果
1)准备测试数据
通过Eclipse下面的“DFS Locations”在“/user/hadoop”目录下创建输入文件“sort_in”文件夹(备注:“sort_out”不需要创建。)如图2.4-1所示,已经成功创建。
然后在本地建立三个txt文件,通过Eclipse上传到“/user/hadoop/sort_in”文件夹中,三个txt文件的内容如“实例描述”那三个文件一样。如图2.4-2所示,成功上传之后。
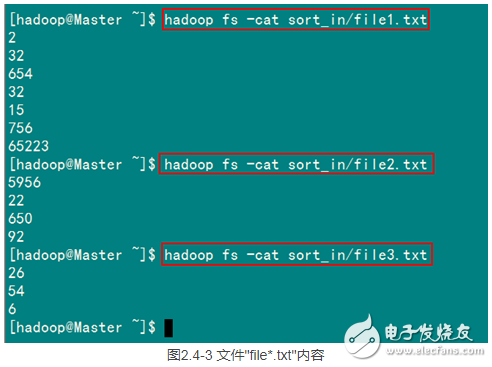
从SecureCRT远处查看“Master.Hadoop”的也能证实我们上传的三个文件。

查看两个文件的内容如图2.4-3所示:
2)查看运行结果
这时我们右击Eclipse 的“DFS Locations”中“/user/hadoop”文件夹进行刷新,这时会发现多出一个“sort_out”文件夹,且里面有3个文件,然后打开双 其“part-r-00000”文件,会在Eclipse中间把内容显示出来。如图2.4-4所示。
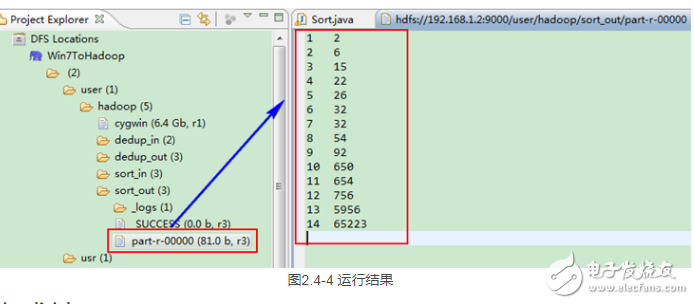
#p##e#
3、平均成绩
“平均成绩”主要目的还是在重温经典“WordCount”例子,可以说是在基础上的微变化版,该实例主要就是实现一个计算学生平均成绩的例子。
3.1 实例描述
对输入文件中数据进行就算学生平均成绩。输入文件中的每行内容均为一个学生的姓名和他相应的成绩,如果有多门学科,则每门学科为一个文件。要求在输出中每行有两个间隔的数据,其中,第一个代表学生的姓名,第二个代表其平均成绩。
样本输入:
1)math:
张三 88
李四 99
王五 66
赵六 77
2)china:
张三 78
李四 89
王五 96
赵六 67
3)english:
张三 80
李四 82
王五 84
赵六 86
样本输出:
张三 82
李四 90
王五 82
赵六 76
3.2 设计思路
计算学生平均成绩是一个仿“WordCount”例子,用来重温一下开发MapReduce程序的流程。程序包括两部分的内容:Map部分和Reduce部分,分别实现了map和reduce的功能。
Map处理的是一个纯文本文件, 文件中存放的数据时每一行表示一个学生的姓名和他相应一科成绩。Mapper处理的数据是由InputFormat分解过的数据集,其中 InputFormat的作用是将数据集切割成小数据集InputSplit,每一个InputSlit将由一个Mapper负责处理。此 外,InputFormat中还提供了一个RecordReader的实现,并将一个InputSplit解析成《key,value》对提 供给了map函数。InputFormat的默认值是TextInputFormat,它针对文本文件,按行将文本切割成InputSlit,并用 LineRecordReader将InputSplit解析成《key,value》对,key是行在文本中的位置,value是文件中的 一行。
Map的结果会通过partion分发到Reducer,Reducer做完Reduce操作后,将通过以格式OutputFormat输出。
Mapper最终处理的结果对《key,value》,会送到Reducer中进行合并,合并的时候,有相同key的键/值对则送到同一个 Reducer上。Reducer是所有用户定制Reducer类地基础,它的输入是key和这个key对应的所有value的一个迭代器,同时还有 Reducer的上下文。Reduce的结果由Reducer.Context的write方法输出到文件中。
3.3 程序代码
程序代码如下所示:
package com.hebut.mr;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Score {
public static class Map extends
Mapper《LongWritable, Text, Text, IntWritable》 {
// 实现map函数
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 将输入的纯文本文件的数据转化成String
String line = value.toString();
// 将输入的数据首先按行进行分割
StringTokenizer tokenizerArticle = new StringTokenizer(line, “\n”);
// 分别对每一行进行处理
while (tokenizerArticle.hasMoreElements()) {
// 每行按空格划分
StringTokenizer tokenizerLine = newStringTokenizer(tokenizerArticle.nextToken());
String strName = tokenizerLine.nextToken();// 学生姓名部分
String strScore = tokenizerLine.nextToken();// 成绩部分
Text name = new Text(strName);
int scoreInt = Integer.parseInt(strScore);
// 输出姓名和成绩
context.write(name, new IntWritable(scoreInt));
}
}
}
public static class Reduce extends
Reducer《Text, IntWritable, Text, IntWritable》 {
// 实现reduce函数
public void reduce(Text key, Iterable《IntWritable》 values,
Context context) throws IOException, InterruptedException {
int sum = 0;
int count = 0;
Iterator《IntWritable》 iterator = values.iterator();
while (iterator.hasNext()) {
sum += iterator.next().get();// 计算总分
count++;// 统计总的科目数
}
int average = (int) sum / count;// 计算平均成绩
context.write(key, new IntWritable(average));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// 这句话很关键
conf.set(“mapred.job.tracker”, “192.168.1.2:9001”);
String[] ioArgs = new String[] { “score_in”, “score_out” };
String[] otherArgs = new GenericOptionsParser(conf, ioArgs).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println(“Usage: Score Average 《in》 《out》”);
System.exit(2);
}
Job job = new Job(conf, “Score Average”);
job.setJarByClass(Score.class);
// 设置Map、Combine和Reduce处理类
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
// 设置输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 将输入的数据集分割成小数据块splites,提供一个RecordReder的实现
job.setInputFormatClass(TextInputFormat.class);
// 提供一个RecordWriter的实现,负责数据输出
job.setOutputFormatClass(TextOutputFormat.class);
// 设置输入和输出目录
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
3.4 代码结果
1)准备测试数据
通过Eclipse下面的“DFS Locations”在“/user/hadoop”目录下创建输入文件“score_in”文件夹(备注:“score_out”不需要创建。)如图3.4-1所示,已经成功创建。
然后在本地建立三个txt文件,通过Eclipse上传到“/user/hadoop/score_in”文件夹中,三个txt文件的内容如“实例描述”那三个文件一样。如图3.4-2所示,成功上传之后。
备注:文本文件的编码为“UTF-8”,默认为“ANSI”,可以另存为时选择,不然中文会出现乱码。
从SecureCRT远处查看“Master.Hadoop”的也能证实我们上传的三个文件。

查看三个文件的内容如图3.4-3所示:
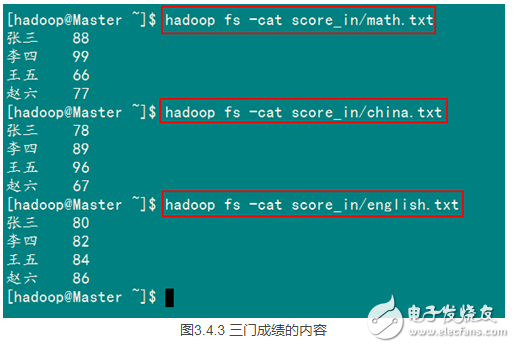
2)查看运行结果
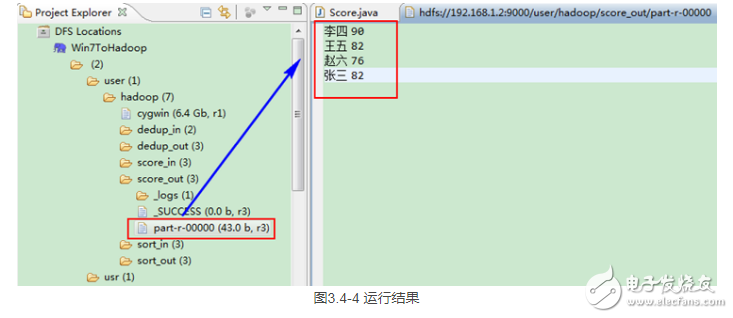
这时我们右击Eclipse 的“DFS Locations”中“/user/hadoop”文件夹进行刷新,这时会发现多出一个“score_out”文件夹,且里面有3个文件,然后打开双 其“part-r-00000”文件,会在Eclipse中间把内容显示出来。如图3.4-4所示。
#p##e#
4、单表关联
前面的实例都是在数据上进行一些简单的处理,为进一步的操作打基础。“单表关联”这个实例要求从给出的数据中寻找所关心的数据,它是对原始数据所包含信息的挖掘。下面进入这个实例。
4.1 实例描述
实例中给出child-parent(孩子——父母)表,要求输出grandchild-grandparent(孙子——爷奶)表。
样例输入如下所示。
file:
child parent
Tom Lucy
Tom Jack
Jone Lucy
Jone Jack
Lucy Mary
Lucy Ben
Jack Alice
Jack Jesse
Terry Alice
Terry Jesse
Philip Terry
Philip Alma
Mark Terry
Mark Alma
家族树状关系谱:
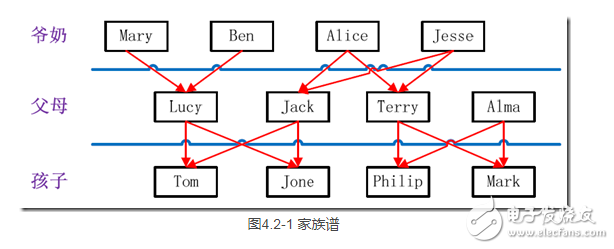
样例输出如下所示。
file:
grandchild grandparent
Tom Alice
Tom Jesse
Jone Alice
Jone Jesse
Tom Mary
Tom Ben
Jone Mary
Jone Ben
Philip Alice
Philip Jesse
Mark Alice
Mark Jesse
4.2 设计思路
分析这个实例,显然需要进行单表连接,连接的是左表的parent列和右表的child列,且左表和右表是同一个表。
连接结果中除去连接的两列就是所需要的结果——“grandchild--grandparent”表。要用MapReduce解决这个实例,首先应该考虑如何实现表的自连接;其次就是连接列的设置;最后是结果的整理。
考虑到MapReduce的shuffle过程会将相同的key会连接在一起,所以可以将map结果的key设置成待连接的列,然后列中相同的值就自然会连接在一起了。再与最开始的分析联系起来:
要连接的是左表的parent列和右表的child列,且左表和右表是同一个表,所以在map阶段将读入数据分割成child和parent之后,会将parent设置成key,child设置成value进行输出,并作为左表;再将同一对child和parent中的child设置成key,parent设置成value进行输出,作为右表。为了区分输出中的左右表,需要在输出的value中再加上左右表的信息,比如在value的String最开始处加上字符1表示左表,加上字符2表示右表。这样在map的结果中就形成了左表和右表,然后在shuffle过程中完成连接。reduce接收到连接的结果,其中每个key的value-list就包含了“grandchild--grandparent”关系。取出每个key的value-list进行解析,将左表中的child放入一个数组,右表中的parent放入一个数组,然后对两个数组求笛卡尔积就是最后的结果了。
4.3 程序代码
程序代码如下所示。
package com.hebut.mr;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class STjoin {
public static int time = 0;
/*
* map将输出分割child和parent,然后正序输出一次作为右表,
* 反序输出一次作为左表,需要注意的是在输出的value中必须
* 加上左右表的区别标识。
*/
public static class Map extends Mapper《Object, Text, Text, Text》 {
// 实现map函数
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String childname = new String();// 孩子名称
String parentname = new String();// 父母名称
String relationtype = new String();// 左右表标识
// 输入的一行预处理文本
StringTokenizer itr=new StringTokenizer(value.toString());
String[] values=new String[2];
int i=0;
while(itr.hasMoreTokens()){
values[i]=itr.nextToken();
i++;
}
if (values[0].compareTo(“child”) != 0) {
childname = values[0];
parentname = values[1];
// 输出左表
relationtype = “1”;
context.write(new Text(values[1]), new Text(relationtype +
“+”+ childname + “+” + parentname));
// 输出右表
relationtype = “2”;
context.write(new Text(values[0]), new Text(relationtype +
“+”+ childname + “+” + parentname));
}
}
}
public static class Reduce extends Reducer《Text, Text, Text, Text》 {
// 实现reduce函数
public void reduce(Text key, Iterable《Text》 values, Context context)
throws IOException, InterruptedException {
// 输出表头
if (0 == time) {
context.write(new Text(“grandchild”), new Text(“grandparent”));
time++;
}
int grandchildnum = 0;
String[] grandchild = new String[10];
int grandparentnum = 0;
String[] grandparent = new String[10];
Iterator ite = values.iterator();
while (ite.hasNext()) {
String record = ite.next().toString();
int len = record.length();
int i = 2;
if (0 == len) {
continue;
}
// 取得左右表标识
char relationtype = record.charAt(0);
// 定义孩子和父母变量
String childname = new String();
String parentname = new String();
// 获取value-list中value的child
while (record.charAt(i) != ‘+’) {
childname += record.charAt(i);
i++;
}
i = i + 1;
// 获取value-list中value的parent
while (i 《 len) {
parentname += record.charAt(i);
i++;
}
// 左表,取出child放入grandchildren
if (‘1’ == relationtype) {
grandchild[grandchildnum] = childname;
grandchildnum++;
}
// 右表,取出parent放入grandparent
if (‘2’ == relationtype) {
grandparent[grandparentnum] = parentname;
grandparentnum++;
}
}
// grandchild和grandparent数组求笛卡尔儿积
if (0 != grandchildnum && 0 != grandparentnum) {
for (int m = 0; m 《 grandchildnum; m++) {
for (int n = 0; n 《 grandparentnum; n++) {
// 输出结果
context.write(new Text(grandchild[m]), newText(grandparent[n]));
}
}
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// 这句话很关键
conf.set(“mapred.job.tracker”, “192.168.1.2:9001”);
String[] ioArgs = new String[] { “STjoin_in”, “STjoin_out” };
String[] otherArgs = new GenericOptionsParser(conf, ioArgs).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println(“Usage: Single Table Join 《in》 《out》”);
System.exit(2);
}
Job job = new Job(conf, “Single Table Join”);
job.setJarByClass(STjoin.class);
// 设置Map和Reduce处理类
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
// 设置输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 设置输入和输出目录
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
4.4 代码结果
1)准备测试数据
通过Eclipse下面的“DFS Locations”在“/user/hadoop”目录下创建输入文件“STjoin_in”文件夹(备注:“STjoin_out”不需要创建。)如图4.4-1所示,已经成功创建。

然后在本地建立一个txt文件,通过Eclipse上传到“/user/hadoop/STjoin_in”文件夹中,一个txt文件的内容如“实例描述”那个文件一样。如图4.4-2所示,成功上传之后。
从SecureCRT远处查看“Master.Hadoop”的也能证实我们上传的文件,显示其内容如图4.4-3所示:
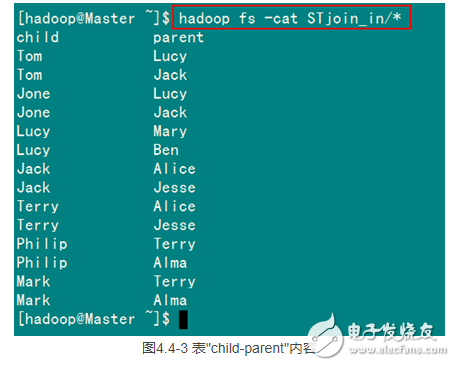
2)运行详解
(1)Map处理:
(2)Shuffle处理
在shuffle过程中完成连接。
(3)Reduce处理
首先由语句“0 != grandchildnum && 0 != grandparentnum”得知,只要在“value-list”中没有左表或者右表,则不会做处理,可以根据这条规则去除无效的shuffle连接。
然后根据下面语句进一步对有效的shuffle连接做处理。
// 左表,取出child放入grandchildren
if (‘1’ == relationtype) {
grandchild[grandchildnum] = childname;
grandchildnum++;
}
// 右表,取出parent放入grandparent
if (‘2’ == relationtype) {
grandparent[grandparentnum] = parentname;
grandparentnum++;
}
针对一条数据进行分析:
《Jack,1+Tom+Jack,
1+Jone+Jack,
2+Jack+Alice,
2+Jack+Jesse 》
分析结果:左表用“字符1”表示,右表用“字符2”表示,上面的《key,value-list》中的“key”表示左表与右表的连接键。而“value-list”表示以“key”连接的左表与右表的相关数据。
根据上面针对左表与右表不同的处理规则,取得两个数组的数据。
然后根据下面语句进行处理。
for (int m = 0; m 《 grandchildnum; m++) {
for (int n = 0; n 《 grandparentnum; n++) {
context.write(new Text(grandchild[m]), new Text(grandparent[n]));
}
}
处理结果如下面所示:
Tom Jesse
Tom Alice
Jone Jesse
Jone Alice
其他的有效shuffle连接处理都是如此。
3)查看运行结果
这时我们右击Eclipse 的“DFS Locations”中“/user/hadoop”文件夹进行刷新,这时会发现多出一个“STjoin_out”文件夹,且里面有3个文件,然后打开双 其“part-r-00000”文件,会在Eclipse中间把内容显示出来。如图4.4-4所示。
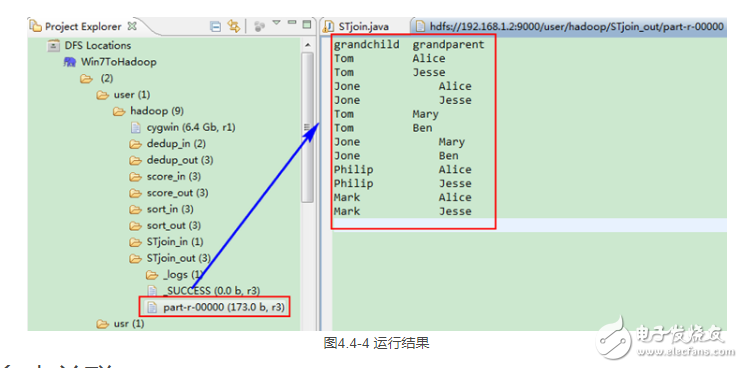
#p##e#
5、多表关联
多表关联和单表关联类似,它也是通过对原始数据进行一定的处理,从其中挖掘出关心的信息。下面进入这个实例。
5.1 实例描述
输入是两个文件,一个代表工厂表,包含工厂名列和地址编号列;另一个代表地址表,包含地址名列和地址编号列。要求从输入数据中找出工厂名和地址名的对应关系,输出“工厂名——地址名”表。
样例输入如下所示。
1)factory:
factoryname addressed
Beijing Red Star 1
Shenzhen Thunder 3
Guangzhou Honda 2
Beijing Rising 1
Guangzhou Development Bank 2
Tencent 3
Back of Beijing 1
2)address:
addressID addressname
1 Beijing
2 Guangzhou
3 Shenzhen
4 Xian
样例输出如下所示。
factoryname addressname
Back of Beijing Beijing
Beijing Red Star Beijing
Beijing Rising Beijing
Guangzhou Development Bank Guangzhou
Guangzhou Honda Guangzhou
Shenzhen Thunder Shenzhen
Tencent Shenzhen
5.2 设计思路
多表关联和单表关联相似,都类似于数据库中的自然连接。相比单表关联,多表关联的左右表和连接列更加清楚。所以可以采用和单表关联的相同的处理方式,map识别出输入的行属于哪个表之后,对其进行分割,将连接的列值保存在key中,另一列和左右表标识保存在value中,然后输出。reduce拿到连接结果之后,解析value内容,根据标志将左右表内容分开存放,然后求笛卡尔积,最后直接输出。
这个实例的具体分析参考单表关联实例。下面给出代码。
5.3 程序代码
程序代码如下所示:
package com.hebut.mr;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class MTjoin {
public static int time = 0;
/*
* 在map中先区分输入行属于左表还是右表,然后对两列值进行分割,
* 保存连接列在key值,剩余列和左右表标志在value中,最后输出
*/
public static class Map extends Mapper《Object, Text, Text, Text》 {
// 实现map函数
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();// 每行文件
String relationtype = new String();// 左右表标识
// 输入文件首行,不处理
if (line.contains(“factoryname”) == true
|| line.contains(“addressed”) == true) {
return;
}
// 输入的一行预处理文本
StringTokenizer itr = new StringTokenizer(line);
String mapkey = new String();
String mapvalue = new String();
int i = 0;
while (itr.hasMoreTokens()) {
// 先读取一个单词
String token = itr.nextToken();
// 判断该地址ID就把存到“values[0]”
if (token.charAt(0) 》= ‘0’ && token.charAt(0) 《= ‘9’) {
mapkey = token;
if (i 》 0) {
relationtype = “1”;
} else {
relationtype = “2”;
}
continue;
}
// 存工厂名
mapvalue += token + “ ”;
i++;
}
// 输出左右表
context.write(new Text(mapkey), new Text(relationtype + “+”+ mapvalue));
}
}
/*
* reduce解析map输出,将value中数据按照左右表分别保存,
* 然后求出笛卡尔积,并输出。
*/
public static class Reduce extends Reducer《Text, Text, Text, Text》 {
// 实现reduce函数
public void reduce(Text key, Iterable《Text》 values, Context context)
throws IOException, InterruptedException {
// 输出表头
if (0 == time) {
context.write(new Text(“factoryname”), new Text(“addressname”));
time++;
}
int factorynum = 0;
String[] factory = new String[10];
int addressnum = 0;
String[] address = new String[10];
Iterator ite = values.iterator();
while (ite.hasNext()) {
String record = ite.next().toString();
int len = record.length();
int i = 2;
if (0 == len) {
continue;
}
// 取得左右表标识
char relationtype = record.charAt(0);
// 左表
if (‘1’ == relationtype) {
factory[factorynum] = record.substring(i);
factorynum++;
}
// 右表
if (‘2’ == relationtype) {
address[addressnum] = record.substring(i);
addressnum++;
}
}
// 求笛卡尔积
if (0 != factorynum && 0 != addressnum) {
for (int m = 0; m 《 factorynum; m++) {
for (int n = 0; n 《 addressnum; n++) {
// 输出结果
context.write(new Text(factory[m]),
new Text(address[n]));
}
}
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// 这句话很关键
conf.set(“mapred.job.tracker”, “192.168.1.2:9001”);
String[] ioArgs = new String[] { “MTjoin_in”, “MTjoin_out” };
String[] otherArgs = new GenericOptionsParser(conf, ioArgs).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println(“Usage: Multiple Table Join 《in》 《out》”);
System.exit(2);
}
Job job = new Job(conf, “Multiple Table Join”);
job.setJarByClass(MTjoin.class);
// 设置Map和Reduce处理类
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
// 设置输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 设置输入和输出目录
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
5.4 代码结果
1)准备测试数据
通过Eclipse下面的“DFS Locations”在“/user/hadoop”目录下创建输入文件“MTjoin_in”文件夹(备注:“MTjoin_out”不需要创建。)如图5.4-1所示,已经成功创建。

然后在本地建立两个txt文件,通过Eclipse上传到“/user/hadoop/MTjoin_in”文件夹中,两个txt文件的内容如“实例描述”那两个文件一样。 成功上传之后,从SecureCRT远处查看“Master.Hadoop”的也能证实我们上传的两个文件。
2)查看运行结果
这时我们右击Eclipse 的“DFS Locations”中“/user/hadoop”文件夹进行刷新,这时会发现多出一个“MTjoin_out”文件夹,且里面有3个文件,然后打开双 其“part-r-00000”文件,会在Eclipse中间把内容显示出来。
6、倒排索引
“倒排索引”是文档检索系统中最常用的数据结构,被广泛地应用于全文搜索引擎。它主要是用来存储某个单词(或词组)在一个文档或一组文档中的存储位置的映射,即提供了一种根据内容来查找文档的方式。由于不是根据文档来确定文档所包含的内容,而是进行相反的操作,因而称为倒排索引(Inverted Index)。
- 相关推荐
- 热点推荐
- MapReduce
-
spark为什么比mapreduce快?2024-09-06 1016
-
MapReduce和Spark概要介绍2023-03-20 2429
-
MapReduce实例开发指南2019-10-08 1254
-
值得一看的MapReduce编程实例2019-03-05 1420
-
MapReduce连接查询的IO代价研究2018-01-31 1459
-
MapReduce的数据放置策略2018-01-26 1122
-
什么是mapreduce_mapreduce工作原理_mapreduce_mapreduce逻辑模型图2018-01-02 26029
-
多阶段划分的MapReduce模型2017-12-27 659
-
Python编程实例2017-01-08 1265
-
C#编程实例与技巧2017-01-02 618
-
FX编程实例2016-11-07 428
-
abb_plc_500编程软件使用实例2015-11-12 1326
-
MapReduce综述2010-09-18 2527
全部0条评论

快来发表一下你的评论吧 !
