

cassandra数据库性能特点及Cassandra数据库设计与维护
编程语言及工具
描述
Cassandra概况
Cassandra是一套开源分布式NoSQL数据库系统。它最初由Facebook开发,用于储存收件箱等简单格式数据,集GoogleBigTable的数据模型与AmazonDynamo的完全分布式的架构于一身。Cassandra的名称来源于希腊神话,是特洛伊的一位悲剧性的女先知的名字,因此项目的Logo是一只放光的眼睛。Facebook于2008将Cassandra开源,此后,由于Cassandra良好的可扩放性,被Digg、Twitter等知名Web2.0网站所采纳,成为了一种流行的分布式结构化数据存储方案。Cassandra在2009年成为了Apache软件基金会的Incubator项目,并在2010年2月走出孵化器,成为正式的基金会项目。
Cassandra功能介绍
Cassandra的主要特点就是它不是一个数据库,而是由一堆数据库节点共同构成的一个分布式网络服务,对Cassandra的一个写操作,会被复制到其他节点上去,对Cassandra的读操作,也会被路由到某个节点上面去读取。对于一个Cassandra群集来说,扩展性能是比较简单的事情,只管在群集里面添加节点就可以了。
这里有很多理由来选择Cassandra用于您的网站。和其他数据库比较,有三个突出特点:
模式灵活
使用Cassandra,像文档存储,你不必提前解决记录中的字段。你可以在系统运行时随意的添加或移除字段。这是一个惊人的效率提升,特别是在大型部署上。
真正的(高)可扩展性
Cassandra是纯粹意义上的水平扩展。为给集群添加更多容量,可以指向另一台电脑。你不必重启任何进程,改变应用查询,或手动迁移任何数据。()可以帮助您可随时添加更多硬件,以便根据需求附加更多客户和更多数据。
多数据中心识别
你可以调整你的节点布局来避免某一个数据中心起火,一个备用的数据中心将至少有每条记录的完全复制。
刚性结构
Cassandra没有一个单一的故障点,它可用于无法承受故障的关键业务应用程序。
快速线性规模的性能
Cassandra线性可扩展。它可以提高吞吐量,因为它可以帮助您增加群集中的节点数量。 因此,它保持快速的响应时间。
容错
Cassandra是容错的。 假设集群中有4个节点,这里每个节点都有相同数据的副本。 如果一个节点不再服务,则其他三个节点可以按照请求进行服务。
灵活的数据存储
Cassandra支持所有可能的数据格式,如结构化,半结构化和非结构化。 它可以帮助您根据需要更改数据结构。
简单的数据分发
Cassandra中的数据分发非常简单,因为它可以灵活地通过在多个数据中心复制数据来分发所需的数据。
事务支持
Cassandra支持事务,诸如原子性,一致性,隔离和持久性(ACID)等属性。
快速写入
Cassandra的设计是在便宜的商品硬件上运行。 它执行快速写入,可以存储数百TB的数据,而不会牺牲读取效率。
一些使Cassandra提高竞争力的其他功能:
范围查询
如果你不喜欢全部的键值查询,则可以设置键的范围来查询。
列表数据结构
在混合模式可以将超级列添加到5维。对于每个用户的索引,这是非常方便的。
分布式写操作
有可以在任何地方任何时间集中读或写任何数据。并且不会有任何单点失败。
应用客户facebook
主要特性
●分布式
●基于column的结构化
●高伸展性
基本架构
Cassandra没有像BigTable或Hbase那样选择中心控制节点,而选择了无中心的P2P架构,网络中的所有节点都是对等的,它们构成了一个环,节点之间通过P2P协议每秒钟交换一次数据,这样每个节点都拥有其它所有节点的信息,包括位置、状态等。
Cassandra的核心组件包括:
Gossip:点对点的通讯协议,用来相互交换节点的位置和状态信息。当一个节点启动时就立即本地存储Gossip信息,但当节点信息发生变化时需要清洗历史信息,比如IP改变了。通过Gossip协议,每个节点定期每秒交换它自己和它已经交换过信息的节点的数据,每个被交换的信息都有一个版本号,这样当有新数据时可以覆盖老数据,为了保证数据交换的准确性,所有的节点必须使用同一份集群列表,这样的节点又被称作seed。
Partitioner:负责在集群中分配数据,由它来决定由哪些节点放置第一份的copy,一般情况会使用Hash来做主键,将每行数据分布到不同的节点上,以确保集群的可扩展性。
Replica placement strategy:复制策略,确定哪个节点放置复制数据,以及复制的份数。
Snitch:定义一个网络拓扑图,用来确定如何放置复制数据,高效地路由请求。
cassandra.yaml:主配置文件,设置集群的初始化配置、表的缓存参数、调优参数和资源使用、超时设定、客户端连接、备份和安全。
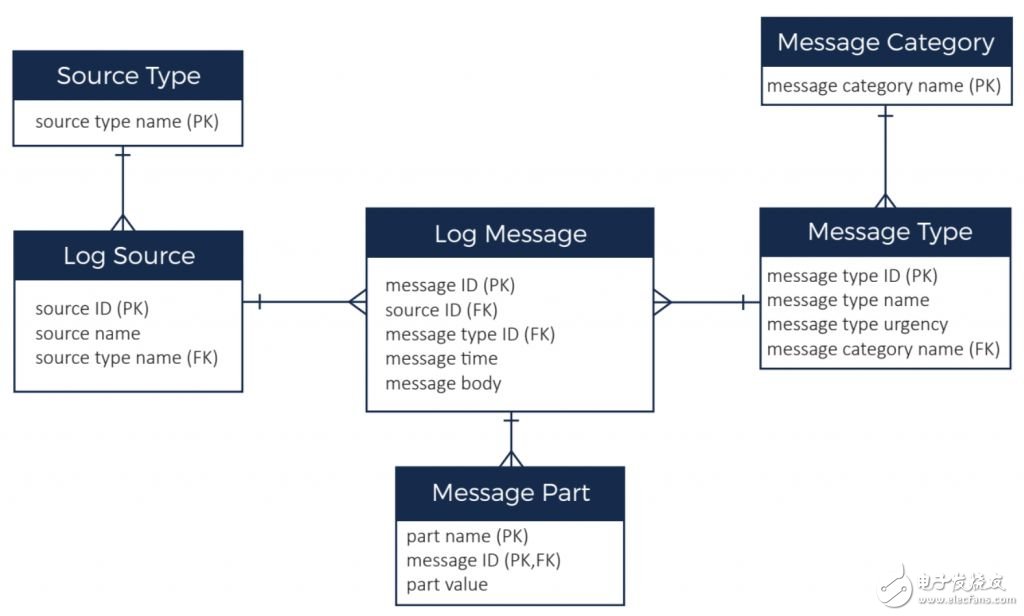
Cassandra数据库设计与维护总结
1.分区字段设计时选用timeuuid/timestamp(比如每日或者每小时0点时间戳)+任意bucket字段(类型等固定的字段)
2.cluster字段可以根据需求设计
3.使用索引时的查询条件中务必带上分区字段的查询条件,否则cassandra会去所有分区字段的索引中查询,效率低下而且一旦查询结果中超过10万个墓碑,就会抛出异常
4.高基数字段比如true/false这类的一般不要上索引,否则会极大的降低查询效率
5.由于cassandra的read repair机制,执行大量删除操作之后如果出现了大量read timeout需要在每台cassandra的bin目录下执行
./nodetool flush
./nodetool $ keyspace $table
强制合并sstable
6.如果cassandra出现不同节点间的数据一致性错误,需要执行。/nodetool repair $keyspace $table
7.如果repair还是不能解决问题,需要执行 。/sstablescrub $keyspace $table清洗掉损坏的数据,注意此操作如果中断容易造成数据损坏,最好执行前先做快照
8.cassandra默认开启了安全模式,执行drop、truncate等敏感字段时会对数据做一次快照,过多快照会导致cassandra在启动时遍历目录环节花费过长时间,最终可能需要几个小时才能启动,
这个时候需要执行。/nodetool clearsnapshot $keyspace
- 相关推荐
- 热点推荐
- Cassandra
-
云数据库是哪种数据库类型?2025-01-07 1389
-
SQLite数据库的特点 SQLite数据库简单介绍2023-08-28 7160
-
云数据库和普通数据库区别?|PetaExpress云端数据库2023-08-01 2277
-
华为云数据库GaussDB(for Cassandra)揭秘:内存异常增长的排查经2022-12-02 1384
-
华为云数据库GaussDB (for Cassandra) 数据库治理 -- 大key与热key问题的检测与解决2022-12-01 1360
-
在数据代理引擎中使用Xilinx FPGA加速Cassandra NoSQL数据库2018-11-29 3161
-
数据库学习教程之数据库的发展状况如何数据库有什么新发展2018-10-25 1358
-
数据库教程之如何进行数据库设计2018-10-19 2220
-
cassandra数据库存储结构_ cassandra数据库数据的写入,读取和删除2018-01-02 12992
全部0条评论

快来发表一下你的评论吧 !
