

什么叫结构化的算法_算法和结构化数据初识
编程语言及工具
描述
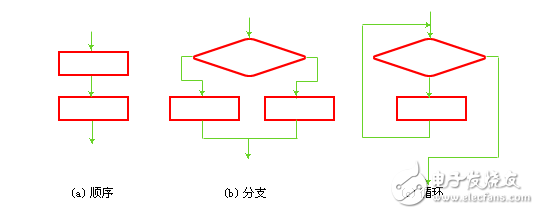
结构化的算法概况
结构化算法是由一些基本结构顺序组成的,就是把一个大的功能的实现分隔为许多个小功能的实现。在基本结构之间不存在向前或向后的跳转,流程的转移只存在于一个基本的结构范围内。一个非结构化的算法可以用一个等价的结构化算法代替,其功能不变。这样的好处是可以将复杂问题简单化,让编程更容易,提高代码维护和可读性。
跟结构化算法比较起来,非结构化算法有以下缺点。
流程不受限制的随意转来转去,使流程图豪无规律。使人在阅读的时候难以理解算法的逻辑。难以阅读,也难以修改。从而使算法的可靠性和可维护性难以保证。

算法和结构化数据初识
数据结构定义:
我们如何把现实中大量而复杂的问题以特定的数据类型和特定的存储结构保存到主存储器(内存)中,以及在此基础上为实现某个功能(如元素的CURD、排序等)而执行的相应操作,这个相应的操作也叫算法。
数据结构 = 元素 + 元素的关系 ;算法 = 对数据结构的操作;
算法:算法就是:解决问题的方法和步骤;
如计算机内存中栈和堆的区别,不懂数据结构的人可能会认为内存就是分两大部分,一块叫栈,一块叫堆,显然这是非常肤浅且不正确的结论。
实际上如果一块内存是以压栈出栈的方式分配的内存,那么这块内存就叫栈内存,如果是以堆排序的方式分配的内存,那么这块内存就叫堆内存,其最根本的区别还是其内存分配算法的不同。
例如,函数的调用方式也是通过压栈出栈的方式来调用的,或者操作系统中多线程操作有队列的概念,队列用于保证多线程的操作顺序,这也是数据结构里面的内容、或者计算机编译原理里面有语法树的概念,这实际上就是数据结构里面的树,比如软件工程、数据库之类都有数据结构的影子。
在计算机系统中,CPU 可以直接操作内存,关于 CPU 对内存的操作与控制原理可以简单理解如下图:
地址线 : 确定操作哪个地址单元
控制线 : 控制该数据单元的读写属性
数据线 : 传输 CPU 和内存之间的数据
什么叫结构体:结构体是用户根据实际需要,自己定义的复合数据类型
指针:
指针就是地址,地址就是指针。
指针变量是存放内存单元地址的变量,它内部保存的值是对应的地址,地址就是内存单元的编号(如内存地址值:0xffc0)。
指针的本质是一个操作受限的非负整数
引用Quora上的回答:
I see it time and again in Google interviews or new-grad hires: The way data structures and algorithms—among the most important subjects in a proper computer science curriculum—are learnt is often insufficient. That‘s not to say students read the wrong books (see my recommendation below) or professors teach the wrong material, but how students ultimately come to understand the subject is lacking.(我多次在google面试或者毕业招聘的时候看到这样的情形:学习数据结构和算法--CS课程里面几乎最重要的课程--的方式很不科学!!到不是说大家用的书或者老师用的材料不对,而是说学生们对于这些课程本身的理解非常缺乏。)
The key to a solid foundation in data structures and algorithms is not an exhaustive survey of every conceivable data structure and its subforms, with memorization of each’s Big-O value and amortized cost. Such knowledge is great and impressive if you‘ve got it, but you will rarely need it. For better or worse, your career will likely never require you to implement a red-black tree node removal algorithm. But you ought be able—with complete ease!—to identify when a binary search tree is a useful solution to a problem, because you will often need that skill.(打好数据结构和算法基础的关键并不在于对于所有数据结构的细致的了解,不是记住每一个大O值或者摊余成本。. )。
如果这些知识你都掌握了,当然很棒并且可以给人留下很深的印象,但是你基本上用不着啊!
你的职业生涯中或许永远都不会要求你实现一个红黑树删除节点的算法。但是!你必须有能力而且手起刀落轻轻松松的识别出什么时候使用二叉树更简单更有效, 因为你十分需要这样的技巧。)
So stop trying to memorize everything. Instead, start with the basics and learn to do two things:
Visualize the data structure. Intuitively understand what the data structurelooks like, what it feels like to use it, and how it is structured both in the abstract and physically in your computer’s memory. This is the single most important thing you can do, and it is useful from the simplest queues and stacks up through the most complicated self-balancing tree. Draw it, visualize it in your head, whatever you need to do: Understand the structure intuitively.
Learn when and how to use different data structures and their algorithms in your own code. This is harder as a student, as the problem assignments you‘ll work through just won’t impart this knowledge. That‘s fine. Realize you won’t master data structures until you are working on a real-world problem and discover that a hash is the solution to your performance woes. But even as a student you should focus on learning not the minutia details but the practicalities: When do you want a hash? When do you want a tree? When is a min-heap the right solution?
(所以,不要试图记住所有的东西。而是从基础开始,做两件事:
第一件事。 把数据结构图形化,视觉化。(突然想起来我高中竞赛老师说的一句话:数形结合千般好,一旦不做万事休啊! 就是要画图! )在直觉上感受一个数据结构是什么样子的。使用它是什么感觉,抽象上和具体实现上是什么样子的。这就是最重要的事情。并且无论是对于简单的队列,栈还是天杀的平衡树都很重要而且有效。把数据结构画出来,在你的脑袋瓜里面就能想象出来,总之,你需要做的就是,直观的去了解这些数据结构。
第二件事。学习什么时候用什么样的数据结构和算法。对于学生来说这很难,而且你要做作业的时候老师也没告诉你们这该怎么办。不过没关系。 你要认识到当你真正处理到现实问题的时候或许你才能掌握某些数据结构,比如哈希表。但是即使是个学生,你也应该知道数据结构的实用性:什么时候你需要个哈希表,什么时候你需要个树,什么时候你需要个堆? 而不是一开始就陷入到追求细节中去。)
One of the questions I ask in Google engineering interviews has a binary search tree as a potential solution (among others)。 Good candidates can arrive at the binary search tree as the right path in a few minutes, and then take 10-15 minutes working through the rest of the problem and the other roadblocks I toss out. But occasionally I get a candidate who intuitively understands trees and can visualize the problem I‘m presenting. They might stumble on the exact algorithmic complexity of some operation, but they can respond to roadblocks without pause because they can visualize the tree. They get it.
(我在google面试的时候,我经常会问一个可以由二叉树搜索解决的问题。 好的应聘者可以几分钟内就可以想到用二叉树来解决,而且对于我的其他问题也差不多10-15分钟就可以解决。当然,偶尔会有一个应聘者,他能直观的认识树这种结构,而且可以把我的问题形象化,图形化的描述出来。当然他或许对于某些操作的时间复杂度不甚了解,但是对于问题他却可以立马回应,因为他们脑袋里就有这样的树结构啊,所以他也能拿到工作啊。)
As for a book, there is but one: Introduction to Algorithms by Cormen, Leiserson, Rivest, and Stein, otherwise known as CLRS.
至于书,只推荐一本--- 《算法导论》
If you want another text, perhaps one with more examples in a specific language, I recommend Robert Sedgewick’s Algorithms in C++ orAlgorithms in Java, as appropriate. I prefer CLRS as a text, but you might find these a better teaching aid.
对于某个数据结构,几步:
1、理解该数据结构的基本概念(定义、实现)
2、尝试理解这个数据结构的意义(为什么它会被发明)
3、用这种数据结构解决一些对应的例题(书本上的习题、Online Judge上的水题)
4、尝试用这个数据结构解决一些以往你用别的数据结构解决的问题,能否解决,为什么。
5、再次尝试理解这个数据结构的意义
6、尝试改变这个数据结构以应对各种现实的问题(Online Judge的好题)
7、学好数学,别数都不会数。
初级篇
记住都有哪些算法,解决什么问题
去试图解决实际的问题,自然会碰到之前算法解决的问题,使用这些算法
中极篇
先完成初级篇
记住算法的具体解决办法
实际的问题 如果有与标准算法相似但是不完全一样的,仔细分析差别,修改原有算法
高级篇
先完成中极篇
分析一下算法的解决办法是如何才能想到,最核心和最精妙的地方在哪儿
实际的问题如果与标准算法都不太象,仔细想想这个问题的本质,借鉴经典算法精妙之处,自己设计自己要用的算法
骨灰篇
先完成高级篇
忘掉所有算法
解决实际问题
- 相关推荐
- 热点推荐
-
什么是结构化网络布线?结构化网络布线有哪些好处?2024-04-11 1436
-
什么是网络系统中的结构化布线?2024-04-07 1282
-
CFD 设计利器:结构化和非结构化网格的组合使用2023-12-23 4657
-
一种结构化道路环境中的视觉导航系统详解2023-09-25 575
-
结构化设计分为哪几部分?结构化设计的要求有哪些2021-12-23 2027
-
结构化汇编语言的监控程序设计思想2021-09-10 1095
-
怎么实现基于结构化方法的无线传感器网络设计?2021-05-31 1246
-
基于深度神经网络的结构化剪枝算法2021-03-10 1157
-
Deeplearningai结构化机器学习项目2020-05-18 2248
-
安防监控视频结构化那些事儿2020-03-20 4215
-
TrustZone结构化消息是什么?2019-03-20 2119
-
结构化布线系统的四点注意事项2018-10-16 1594
-
结构化布线系统有哪些难题2016-05-19 3187
-
结构化布线的综合说明2010-04-14 901
全部0条评论

快来发表一下你的评论吧 !
