

8 种进行简单线性回归的方法分析与讨论
人工智能
描述
本文中,作者讨论了 8 种在 Python 环境下进行简单线性回归计算的算法,不过没有讨论其性能的好坏,而是对比了其相对计算复杂度的度量。
对于大多数数据科学家而言,线性回归方法是他们进行统计学建模和预测分析任务的起点。但我们不可夸大线性模型(快速且准确地)拟合大型数据集的重要性。如本文所示,在线性回归模型中,「线性」一词指的是回归系数,而不是特征的 degree。
特征(或称独立变量)可以是任何的 degree,甚至是超越函数(transcendental function),比如指数函数、对数函数、正弦函数。因此,很多自然现象可以通过这些变换和线性模型来近似模拟,即使当输出与特征的函数关系是高度非线性的也没问题。
另一方面,由于 Python 正在快速发展为数据科学家的首选编程语言,所以能够意识到存在很多方法用线性模型拟合大型数据集,就显得尤为重要。同样重要的一点是,数据科学家需要从模型得到的结果中来评估与每个特征相关的重要性。
然而,在 Python 中是否只有一种方法来执行线性回归分析呢?如果有多种方法,那我们应该如何选择最有效的那个呢?
由于在机器学习中,Scikit-learn 是一个十分流行的 Python 库,因此,人们经常会从这个库调用线性模型来拟合数据。除此之外,我们还可以使用该库的 pipeline 与 FeatureUnion 功能(如:数据归一化、模型回归系数正则化、将线性模型传递给下游模型),但是一般来看,如果一个数据分析师仅需要一个又快又简单的方法来确定回归系数(或是一些相关的统计学基本结果),那么这并不是最快或最简洁的方法。
虽然还存在其他更快更简洁的方法,但是它们都不能提供同样的信息量与模型灵活性。
请继续阅读。
有关各种线性回归方法的代码可以参阅笔者的 GitHub。其中大部分都基于 SciPy 包
SciPy 基于 Numpy 建立,集合了数学算法与方便易用的函数。通过为用户提供高级命令,以及用于操作和可视化数据的类,SciPy 显著增强了 Python 的交互式会话。
以下对各种方法进行简要讨论。
方法 1:Scipy.polyfit( ) 或 numpy.polyfit( )

这是一个非常一般的最小二乘多项式拟合函数,它适用于任何 degree 的数据集与多项式函数(具体由用户来指定),其返回值是一个(最小化方差)回归系数的数组。
对于简单的线性回归而言,你可以把 degree 设为 1。如果你想拟合一个 degree 更高的模型,你也可以通过从线性特征数据中建立多项式特征来完成。
详细描述参考:https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.polyfit.html。
方法 2:stats.linregress( )

这是 Scipy 中的统计模块中的一个高度专门化的线性回归函数。其灵活性相当受限,因为它只对计算两组测量值的最小二乘回归进行优化。因此,你不能用它拟合一般的线性模型,或者是用它来进行多变量回归分析。但是,由于该函数的目的是为了执行专门的任务,所以当我们遇到简单的线性回归分析时,这是最快速的方法之一。除了已拟合的系数和截距项(intercept term)外,它还会返回基本的统计学值如 R² 系数与标准差。
详细描述参考:
方法 3:optimize.curve_fit( )

这个方法与 Polyfit 方法类似,但是从根本来讲更为普遍。通过进行最小二乘极小化,这个来自 scipy.optimize 模块的强大函数可以通过最小二乘方法将用户定义的任何函数拟合到数据集上。
对于简单的线性回归任务,我们可以写一个线性函数:mx+c,我们将它称为估计器。它也适用于多变量回归。它会返回一个由函数参数组成的数列,这些参数是使最小二乘值最小化的参数,以及相关协方差矩阵的参数。
详细描述参考:https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.curve_fit.html
方法 4:numpy.linalg.lstsq

这是用矩阵因式分解来计算线性方程组的最小二乘解的根本方法。它来自 numpy 包中的线性代数模块。通过求解一个 x 向量(它将|| b—a x ||²的欧几里得 2-范数最小化),它可以解方程 ax=b。
该方程可能会欠定、确定或超定(即,a 中线性独立的行少于、等于或大于其线性独立的列数)。如果 a 是既是一个方阵也是一个满秩矩阵,那么向量 x(如果没有舍入误差)正是方程的解。
借助这个方法,你既可以进行简单变量回归又可以进行多变量回归。你可以返回计算的系数与残差。一个小窍门是,在调用这个函数之前,你必须要在 x 数据上附加一列 1,才能计算截距项。结果显示,这是处理线性回归问题最快速的方法之一。
详细描述参考:https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.linalg.lstsq.html#numpy.linalg.lstsq
方法 5: Statsmodels.OLS ( )
statsmodel 是一个很不错的 Python 包,它为人们提供了各种类与函数,用于进行很多不同统计模型的估计、统计试验,以及统计数据研究。每个估计器会有一个收集了大量统计数据结果的列表。其中会对结果用已有的统计包进行对比试验,以保证准确性。
对于线性回归,人们可以从这个包调用 OLS 或者是 Ordinary least squares 函数来得出估计过程的最终统计数据。
需要记住的一个小窍门是,你必须要手动为数据 x 添加一个常数,以用于计算截距。否则,只会默认输出回归系数。下方表格汇总了 OLS 模型全部的结果。它和任何函数统计语言(如 R 和 Julia)一样丰富。
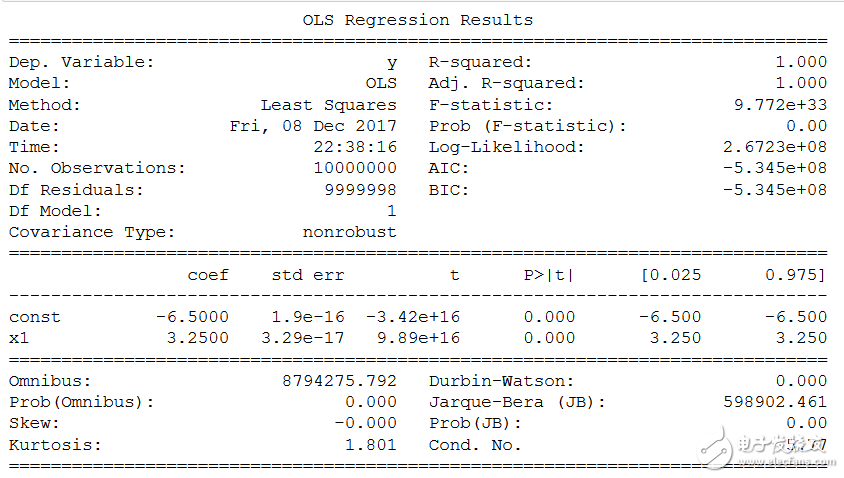
详细描述参考:
方法 6、7:使用矩阵求逆方法的解析解
对于一个良态(well-conditioned)线性回归问题(至少是对于数据点、特征),回归系数的计算存在一个封闭型的矩阵解(它保证了最小二乘的最小化)。它由下面方程给出:
在这里,我们有两个选择:
方法 6:使用简单矩阵求逆乘法。
方法 7:首先计算数据 x 的广义 Moore-Penrose 伪逆矩阵,然后将结果与 y 进行点积。由于这里第二个步骤涉及到奇异值分解(SVD),所以它在处理非良态数据集的时候虽然速度慢,但是结果不错。(参考:开发者必读:计算机科学中的线性代数)
详细描述参考:https://en.wikipedia.org/wiki/Linear_least_squares_%28mathematics%29
方法 8: sklearn.linear_model.LinearRegression( )
这个方法经常被大部分机器学习工程师与数据科学家使用。然而,对于真实世界的问题,它的使用范围可能没那么广,我们可以用交叉验证与正则化算法比如 Lasso 回归和 Ridge 回归来代替它。但是要知道,那些高级函数的本质核心还是从属于这个模型。
详细描述参考:
以上方法的速度与时间复杂度测量
作为一个数据科学家,他的工作经常要求他又快又精确地完成数据建模。如果使用的方法本来就很慢,那么在面对大型数据集的时候便会出现执行的瓶颈问题。
一个判断算法能力可扩展性的好办法,是用不断扩大的数据集来测试数据,然后提取所有试验的执行时间,画出趋势图。
可以在 GitHub 查看这个方法的代码。下方给出了最终的结果。由于模型的简单性,stats.linregress 和简单矩阵求逆乘法的速度最快,甚至达到了 1 千万个数据点。
总结
作为一个数据科学家,你必须要经常进行研究,去发现多种处理相同的分析或建模任务的方法,然后针对不同问题对症下药。
在本文中,我们讨论了 8 种进行简单线性回归的方法。其中大部分方法都可以延伸到更一般的多变量和多项式回归问题上。我们没有列出这些方法的 R² 系数拟合,因为它们都非常接近 1。
对于(有百万人工生成的数据点的)单变量回归,回归系数的估计结果非常不错。
这篇文章首要目标是讨论上述 8 种方法相关的速度/计算复杂度。我们通过在一个合成的规模逐渐增大的数据集(最大到 1 千万个样本)上进行实验,我们测出了每种方法的计算复杂度。令人惊讶的是,简单矩阵求逆乘法的解析解竟然比常用的 scikit-learn 线性模型要快得多。
- 相关推荐
- 热点推荐
- python
-
线性回归的类型和应用2026-03-13 335
-
多元线性回归的特点是什么2023-10-31 2657
-
使用KNN进行分类和回归2022-10-28 3719
-
使用PyMC3包实现贝叶斯线性回归2022-10-08 2807
-
如何用C语言实现一个简单的一元线性回归算法2021-07-20 1666
-
TensorFlow实现简单线性回归2020-08-11 2002
-
回归算法有哪些,常用回归算法(3种)详解2020-07-28 2716
-
python数据分析基础之使用statasmodels进行线性回归2020-06-19 2481
-
简单线性回归代码实现细节分析2020-05-22 1787
-
生产应用中使用线性回归进行实际操练2020-05-08 1129
-
机器学习的线性回归分析2020-01-23 3977
-
讨论8种在Python环境下进行简单线性回归计算的算法2019-02-13 3456
-
8种用Python实现线性回归的方法对比分析_哪个方法更好?2018-06-28 5159
-
一类线性时变系统线性化稳定性分析方法的讨论2016-01-07 640
全部0条评论

快来发表一下你的评论吧 !
