

OpenVINO 2024.4持续提升GPU上LLM性能
描述
作者:
Yury Gorbachev 英特尔院士 OpenVINO 产品架构师
Whiteny Foster OpenVINO 产品专家
翻译:
武卓 博士 英特尔 OpenVINO 布道师
本次新版本在整个 OpenVINO 产品系列中引入了重要的功能和性能变化,使大语言模型 (LLM) 的优化和部署在所有支持的场景中更容易、性能更高,包括边缘和数据中心环境的部署。
在客户端,在之前的版本中我们一直在努力工作,而这个版本则支持我们全新的 Intel Xe2 GPU 架构,该架构在最近推出的 Intel Core Ultra 处理器(第二代)中搭载。Xe2 架构由 Intel Xe Matrix Extensions (Intel XMX) 加速技术提供支持,我们与 oneDNN 和驱动程序团队的合作伙伴合作启用了该技术,以在矩阵乘法等计算密集型运算上实现最佳性能。由于矩阵乘法是 LLM 中的一个关键热点,因此在部署 LLM 时,使用 Xe2 架构的性能优势会立即显现出来。
我们不仅直接通过英特尔 XMX 优化了矩阵乘法,还创建了高度优化的 GPU 基元,如 缩放点积注意力(Scaled Dot Product Attention) 和旋转位置编码( Rotary Positional Embeddings),以减少这些复杂操作的执行流水线开销。我们致力于改善内存消耗并更有效地支持具有压缩权重的模型,从而使大型语言模型(LLM)的部署更适合笔记本电脑/边缘设备,并允许 LLM 适应最小的内存占用,这对于资源有限的环境至关重要。
我们所做的一些更改是通用的,并且会对其它平台产生显著影响,包括平台上的集成显卡(例如 Intel Core Ultra(第一代))和独立显卡(Intel Arc 系列)。
通过横跨数十个大语言模型的性能和准确性验证,我们衡量了整个模型集的这些改进。使用神经网络压缩框架 (NNCF) 优化框架中的权重压缩算法可以严格控制对模型准确性的影响。
对内置 显卡的性能进行比较,英特尔酷睿 Ultra 处理器(第二代)的 第2 个Token延迟性能比第一代 高出 1.3 倍,适用于 Llama3-8B 和 Phi-3-Mini-4k-Instruct 等 LLM,详情请参见下图。
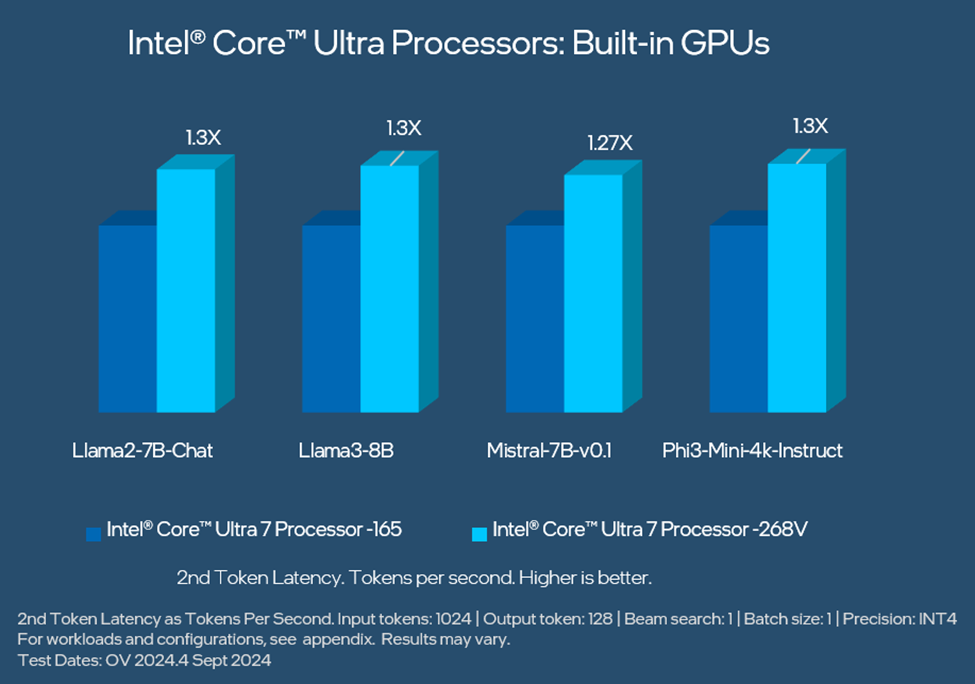
使用 OpenVINO 工具套件 2024.4 在最新的英特尔酷睿超级处理器(第二代)内置 GPU 上最大限度地提高 LLM 性能。有关工作负载和配置,请参阅附录。结果可能会有所不同。
除了 GPU,Intel Core Ultra 处理器(第二代)还引入了更强大的 NPU,具有 40 TOPS 的峰值推理吞吐量,这是对上一代产品的重大升级。OpenVINO 现在通过 OpenVINO GenAI 软件包为经典深度学习模型(例如计算机视觉、语音识别和生成)和 LLM 提供对这种加速技术的访问。我们一直在与 NPU 团队合作,以提高性能、减少内存消耗并加快过去版本的模型编译速度,并将在未来的版本中继续增强。
使用 LLM 的另一种常用场景是通过模型服务,这意味着模型可以通过 REST API 被访问,并通过 vLLM 或 OpenVINO 模型服务器 (OVMS) 等框架来进行服务。对于此使用场景,我们还引入了新功能以增强解决方案特性。
OpenVINO 模型服务器(OVMS) 现在通过 OpenAI API 为 LLM 提供服务,并提供了启用前缀缓存功能的能力,该功能通过缓存提示词常见部分的计算来提高服务吞吐量。当提示词以相同的文本开头(例如“您是一个有用的 AI 助手”)或在聊天场景中使用 LLM 时,这尤其有用。我们还为 OVMS 中的 CPU 启用了 KV 缓存压缩,从而减少了内存消耗并改进了第二个Token延迟等指标。
从 OpenVINO 2024.4 版本开始,GPU 将支持分页注意力( PagedAttention) 操作和连续批处理,这使我们能够在 LLM 服务场景中使用 GPU。我们最初在对 vLLM 的贡献中启用此功能,并在此版本中将其扩展到 OpenVINO 模型服务器。这允许 Intel ARC GPU 在您的环境中以优化的服务特性提供 LLM 模型服务。查看适用于 CPU 和 GPU 的 LLM 服务演示,其中展示了如何利用这些功能。
LLM 服务演示
https://docs.openvino.ai/2024/ovms_demos_continuous_batching.html
为了继续数据中心场景,OpenVINO 现在在英特尔至强处理器上运行时提供对 mxfp4 的支持,如开放计算项目规范中所定义。对于 LLM,与 BF16 精度相比,它允许在第二个令牌延迟上提高性能,同时减少内存消耗。神经网络压缩框架 (NNCF) 模型优化功能支持此功能,该功能允许将 LLM 权重压缩为这种格式。
定义
https://www.opencompute.org/documents/ocp-microscaling-formats-mx-v1-0-spec-final-pdf
从模型支持的角度来看,我们一直在与 Hugging Face 的合作伙伴一起更新 Optimum -Intel 解决方案。该方案允许在使用 OpenVINO 运行时时使用 Hugging Face API 运行模型,并高效导出和压缩模型以用于 OpenVINO GenAI 软件包 API。在此版本中,我们专注于支持 Florence 2、MiniCPM2、Phi-3-Vision、Flux.1 等模型。OpenVINO Notebooks 已经可用,用于演示如何在您选择的平台上将这些模型与 OpenVINO 一起使用。
OpenVINO Notebooks
https://github.com/openvinotoolkit/openvino_notebooks
使用 Flux.1 和 OpenVINO 生成文本到图像,并带有输入提示: 一只小小的约克夏梗宇航员从月球上的蛋中孵化。https://github.com/openvinotoolkit/openvino_notebooks/tree/latest/notebooks/flux.1-image-generation
整个夏天,我们一直在与 Google Summer of Code 的优秀贡献者合作,结果令人鼓舞。我们一直在努力改进
ARM 平台上的生成式 AI
https://medium.com/openvino-toolkit/improve-openvino-performance-on-generative-ai-workload-on-arm-devices-with-5aee5808e23a,
支持 RISC-V
https://medium.com/openvino-toolkit/my-journey-with-google-summer-of-code-2024-enhancing-openvino-for-risc-v-devices-b69568426aff
并探索许多其他令人兴奋的发展,我们很快将更详细地介绍这些发展。
谢谢您,我们期待在即将发布的版本中为您带来更多性能改进和新功能。有关此版本的更多详细信息,请参阅 发行说明。
发行说明
https://docs.openvino.ai/2024/about-openvino/release-notes-openvino.html
Appendix
附录
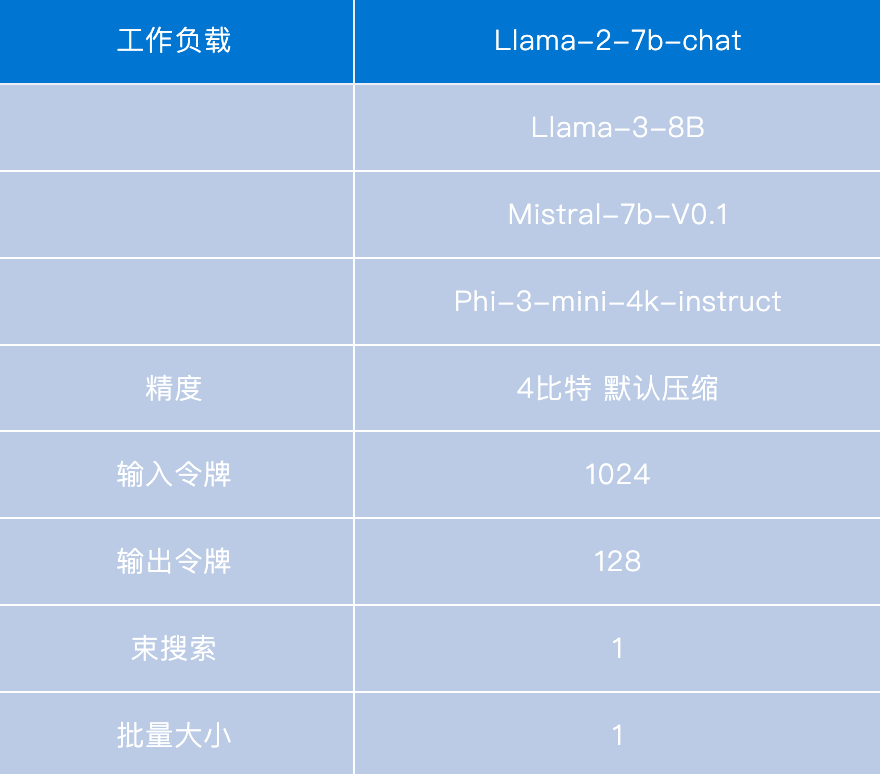
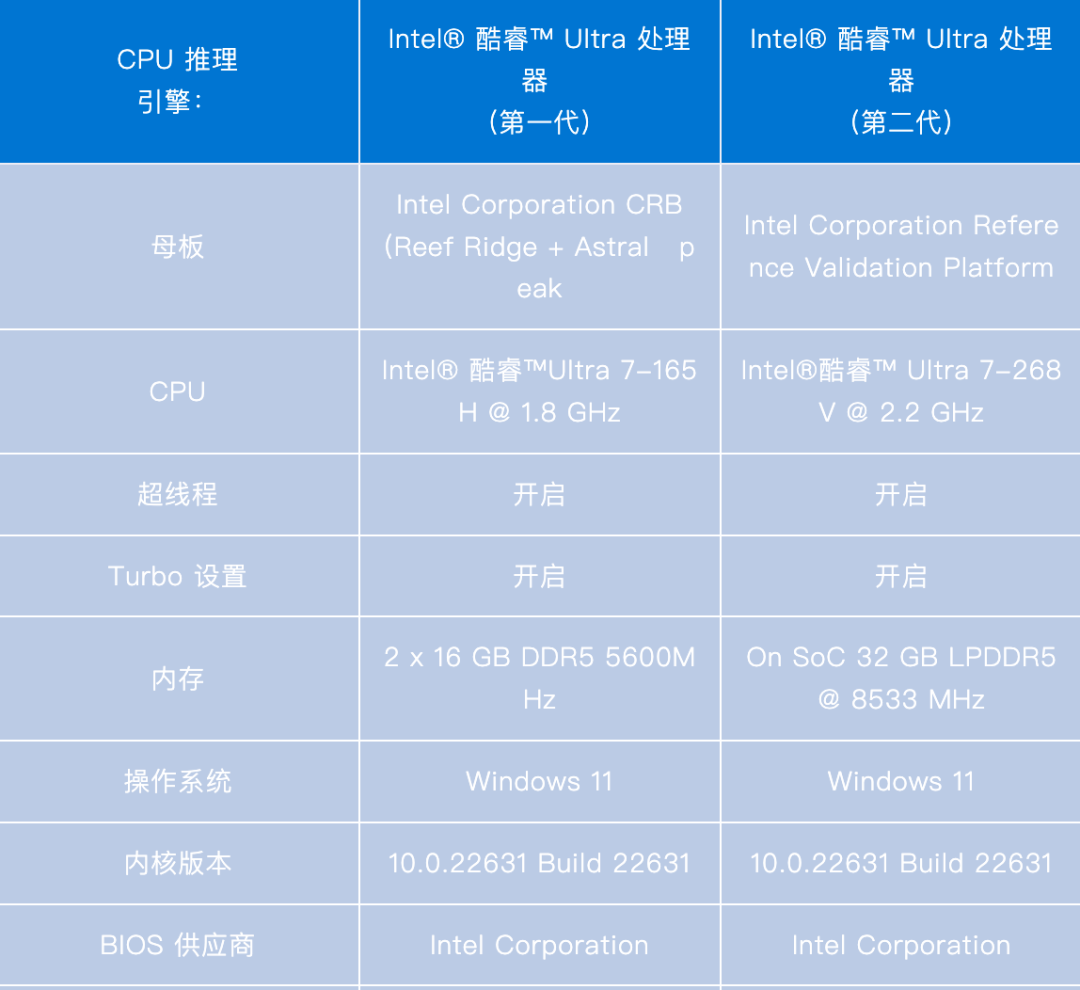

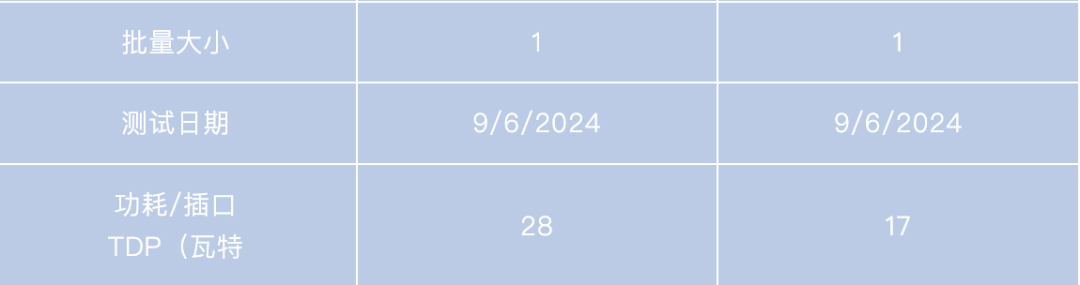
-
无法使用OpenVINO™在 GPU 设备上运行稳定扩散文本到图像的原因?2025-06-25 565
-
使用 llm-agent-rag-llamaindex 笔记本时收到的 NPU 错误怎么解决?2025-06-23 521
-
如何在Ollama中使用OpenVINO后端2025-04-14 2208
-
无法在GPU上运行ONNX模型的Benchmark_app怎么解决?2025-03-06 577
-
OpenVINO™检测到GPU,但网络无法加载到GPU插件,为什么?2025-03-05 556
-
解锁NVIDIA TensorRT-LLM的卓越性能2024-12-17 2174
-
Arm KleidiAI助力提升PyTorch上LLM推理性能2024-12-03 2437
-
解锁LLM新高度—OpenVINO™ 2024.1赋能生成式AI高效运行2024-05-10 1482
-
低比特量化技术如何帮助LLM提升性能2023-12-08 2559
-
Nvidia 通过开源库提升 LLM 推理性能2023-10-23 1760
-
GPU上OpenVINO基准测试的推断模型的默认参数与CPU上的参数不同是为什么?2023-08-15 816
-
LLM性能的主要因素2023-05-22 2974
-
ARM新架构很给力,GPU性能提升了20%,但麒麟990无缘用上2019-08-21 9764
全部0条评论

快来发表一下你的评论吧 !
