

英特尔和阿里云开发DDR5内存故障预测和预防解决方案
描述
背 景
在阿里云数据中心,内存故障是服务器稳定运行面临的主要挑战之一。大规模数据中心中的内存故障,不仅会降低服务器的可靠性,还可能中断数据中心的服务并影响服务器的性能。因此,内存可靠性成为数据中心中服务器可靠性、可用性和可维护性(Reliability, Availability, Serviceability–RAS)的关键要素。
新一代内存标准DDR5具有更高的带宽、更低的功耗和更高的密度。然而,它也为内存可靠性带来了新的挑战,其中包括:
DDR5引入了新的架构和信号传输方式,需要更复杂的电路设计和优化;
DDR5内存模块容量更大,但也增加了故障的风险;
In-DRAM纠错码(ECC)虽然可以纠正内存中单比特的错误,但它也导致主机错误观察不够明确。
为了应对这些挑战,阿里云与英特尔合作改进了DDR5内存的可靠性。具体措施包括:
1.主板管理控制器(BMC)的统一带外(OOB)内存错误数据收集:通过BMC实现内存错误数据的统一收集,为后续分析提供数据基础。
2.内置人工智能辅助(AI辅助)的故障分析:BMC中集成AI辅助,实时预测和分析内存故障。
3.英特尔 Memory Resilience Technology(英特尔 MRT):英特尔 MRT已在阿里云数据中心部署,用于提前预警和预防潜在的内存故障。
4.与阿里云巡洋舰系统(Alibaba Cruiser System)集成:将内存健康评估和预测警报与阿里云的服务器监控系统集成,以确保业务的稳定性。
这些举措共同为阿里云数据中心提供了快速且全面的硬件监控服务,帮助确保了服务器的可靠性和业务的正常运行。
内存可靠性面临的挑战
内存故障可能由多种不同类型内存底层错误产生,例如单比特错误(SBE)、行类型错误、列类型错误、多阵列错误、存储器模块(DIMM)错误等。每种内存错误都有其特定的频率和受影响模式。例如,某些错误类型会零星出现或间歇性发生,难以有效追踪,而有些错误类型则可能持续报错。有些错误类型存在更高的不可纠正错误(Uncorrectable Errors–UE)风险,需要立即采取RAS(可靠性、可用性和可维护性)措施,而其他一些错误类型触发UE的风险相对较低,但在短时间内可能导致大量可纠正错误 (Correctable Errors–CE),从而影响系统性能。没有一种通用的解决方案可以解决所有内存错误。
传统的解决方案之一是在观察到不可纠正错误(UE)后更换故障的DIMM。然而,此举无法避免系统崩溃的成本。另一种方法是基于计数的可纠正错误(CE)评级策略来预测内存故障这种策略在预测复杂内存故障方面效果较差,因为CE和UE的发生不仅取决于硬件的内存故障状态,还取决于隐性的运行时上下文、ECC纠正能力和内存特定的故障模式。因此,内存错误具有高度的不确定性,预测UE非常困难。
虽然没有通用的解决方案,但我们可以探索更智能的方法来处理内存故障。例如,结合机器学习和实时监测,以更精确地预测UE和CE的发生。内存错误是一个复杂且关键的问题,需要综合考虑多种因素来优化系统的可靠性和性能。
基于BMC的人工智能辅助故障分析助力提升DDR5内存的可靠性
阿里云和英特尔联合研究和开发了面向DDR5的内存故障预测和预防解决方案。该方案通过BMC实现内存错误数据的统一收集,为后续分析提供数据基础。在BMC中集成英特尔 MRT技术提供AI辅助的实时预测和分析内存故障,用于提前预警和预防潜在的内存故障。数据收集、故障分析和预警与阿里云的服务器监控系统集成(阿里云巡洋舰系统),为阿里云的数据中心提供快速而全面的硬件监控服务,以确保业务的稳定性。
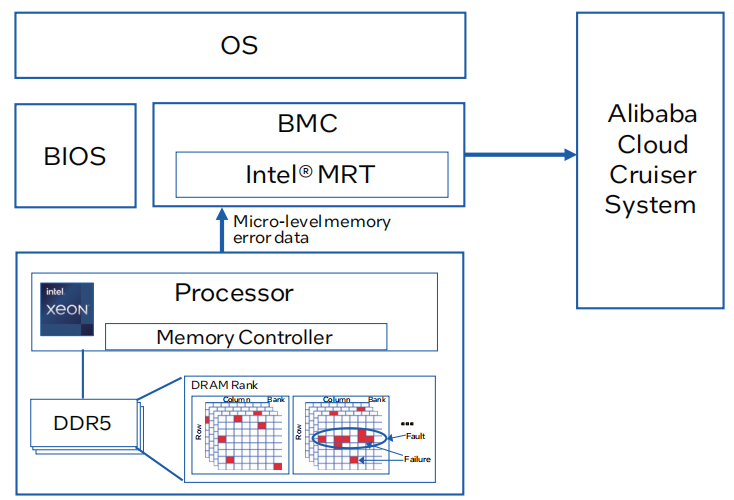
图1. 解决方案架构图
这一解决方案的关键特点包括:
基于BMC的细粒度内存故障采集
通过BMC收集细粒度的可纠正错误(CE)和不可纠正错误(UE)信息,包括详细的位级错误数据。相比使用带内(in-band)方式收集内存错误数据,例如错误检测和纠正(EDAC)驱动程序或基于BIOS SMI中断触发,基于BMC的带外内存收集更可靠且统一,具有细粒度的数据粒度和丰富的错误信息。
基于微观内存故障类型的错误分析
通过历史可纠正错误(CE)信息的详细数据,检测底层内存故障类型。与仅关注CE计数不同,该解决方案从多个因素检查内存错误数据,包括空间分布(例如channel、rank、sub-channel、 bank、row、column等)、时间模式(例如瞬态、间歇、永久)、错误位(error bit)位置、内存特定故障模式、CPU错误纠错码(ECC)设计以及系统RAS配置等综合评估故障风险。
AI辅助故障分析
利用机器学习方法训练了一个AI模型,通过对海量DDR5内存日志进行比较,预测内存故障。预先训练的内存故障预测AI模型集成到主板管理控制器(BMC)中,通过BMC为服务器提供内存故障的实时预测与分析,从而减少大规模数据中心中的服务器停机时间。
集成阿里云巡洋舰硬件故障检测系统
实时内存健康评估和预测警报已与阿里云巡洋舰系统集成,为阿里云数据中心的物理服务器提供快速而全面的硬件监控服务。
英特尔 Memory Resilience Technology
英特尔 Memory Resilience Technology(英特尔 MRT)是一项旨在提高数据中心内存可靠性的技术,它使数据中心运营商能够主动预测潜在的内存故障风险,确保数据中心的运行和工作负载的连续性。以下是该技术的关键功能:
1.基于带外的细粒度内存故障数据收集:实现细粒度内存错误数据的统一收集,为后续分析提供数据基础。
2.分析定位内存故障点:提供底层内存故障定位及分析。
3.预测性故障警报:提前发现可能出现的内存故障。
4.基于预测的内存页面离线:根据预测,将内存页面离线,以防止潜在故障影响。
5.基于预测的内存故障区域隔离:根据预测及系统相应RAS配置,隔离内存故障区域,以避免潜在内存错误发生。
英特尔 Memory Resilience Technology利用多维模型和人工智能算法,在微观层面检测内存故障。它为每个DIMM分配健康分数,并实时检测潜在的故障。通过人工智能分析海量的内存错误日志优化内存故障预测模型,该技术可以准确地定位潜在问题,并在故障发生之前识别和防止内存故障。
虽然没有通用的解决方案可以解决所有内存错误,但英特尔 Memory Resilience Technology为数据中心提供了一种智能且综合的方法,以优化系统的可靠性和性能。
利用BDAT数据诊断硬件故障
英特尔BIOS参考代码实现了系统验证功能,可以生成包括内存余量数据在内的全面系统数据。这些数据从标准的BIOS数据ACPI表 (BDAT)中暴露出来,该表在ACPI表中定义。BDAT数据是系统BIOS的基本支持,它在整个BIOS引导流程中生成,并集成到ACPI RSDT表中。通过分析BDAT数据,可以有效提升生产系统的诊断和问题调试的效率。
结果与分析
阿里云已在不同工作负载下的阿里云数据中心的数千台采用第四代英特尔 至强 可扩展处理器的平台上部署了英特尔 Memory Resilience Technology,并正在将平台升级至第五代英特尔 至强 可扩展处理器。
新一代处理器拥有更可靠的性能,更出色的能效。它在运行各种工作负载时均可实现显著的每瓦性能增益,在AI、数据中心、网络和科学计算的性能和总体拥有成本(TCO)方面亦有更出色的表现。相较上一代产品,第五代英特尔 至强 可扩展处理器可在相同功耗范围内提供更高的算力和更快的内存。此外,它与上一代产品的软件和平台兼容,因此部署新系统时可大大减少测试和验证工作。

图2. 第五代英特尔 至强 可扩展处理器具备更强大性能
初步结果表明,该解决方案可以在不可纠正错误(UE)发生之前有效地预测,并在传统的基于CE计数的CE风暴识别机制被触发之前警报可纠正错误(CE)风暴案例。UE和CE风暴警报的预测提前时间因底层故障模型而异,从几分钟到几小时甚至几天不等。该方案经过迭代,预期能够通过优化的DDR5模型预测57%的UE和74%的CE风暴6 。
除了有效的UE和CE风暴预测外,从BMC收集的带外(OOB)内存错误对于进一步诊断和排除内存和系统问题至关重要。
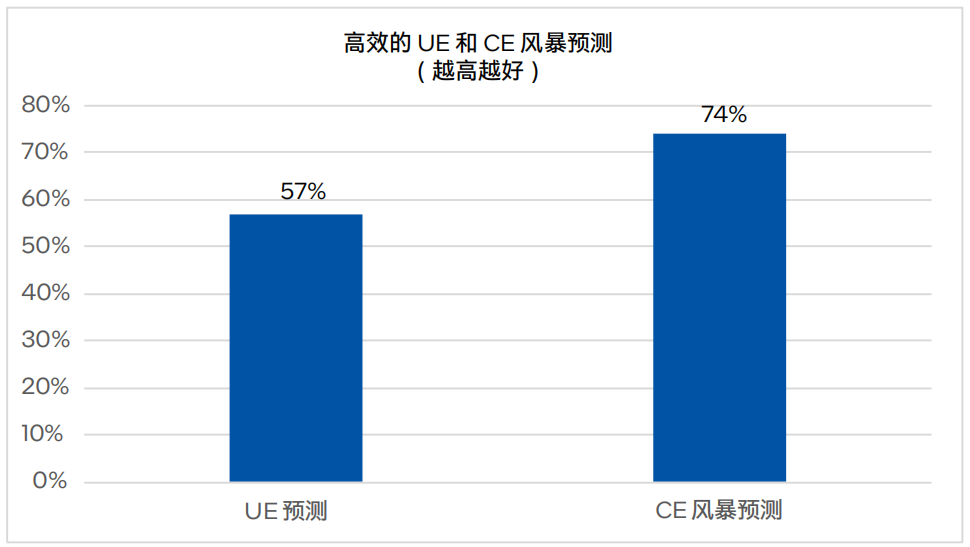
图3. 高效的UE和CE风暴预测
结 论
通过BMC集成英特尔 Memory Resilience Technology技术,可以有效提高阿里云数据中心DDR5内存可靠性。对于阿里云而言,改善整体数据中心的总体拥有成本(TCO)至关重要。英特尔和阿里云正在合作开发下一代的DDR5故障预测技术和提供对新内存技术的方法。
-
英特尔FPGA 支持阿里云的加速即服务2017-10-17 8914
-
DDR5进入放量元年,内存性能提升50%以上!2021-10-25 13281
-
Introspect DDR5/LPDDR5总线协议分析仪2024-08-06 4936
-
阿里巴巴携手英特尔开发一款基于FPGA的解决方案,以帮助客户提升业务应用的性能2017-03-15 3266
-
凌华科技发布两款基于最新的英特尔® 酷睿™处理器的模块化电脑2023-02-15 1026
-
英特尔和谷歌推出面向谷歌云Anthos的英特尔精选解决方案2019-09-02 3762
-
内存条ddr4和显卡ddr52020-07-30 3557
-
英特尔携手阿里云推出了全新领航员计划2.0,共推数智经济发展2020-09-21 2487
-
DDR5放量元年 上游三巨头积极部署2021-10-26 3268
-
金士顿DDR5内存通过英特尔内存解决方案_瑞虎8西伯利亚版上市发布2022-03-16 2088
-
英特尔® Agilex™ M系列满足不断增加的内存带宽需求2022-04-24 2445
-
英特尔13代酷睿模组的最佳之选——科赋DDR5超频电竞内存条2022-12-02 1505
-
DDR5内存的工作原理详解 DDR5和DDR4的主要区别2024-11-22 9843
-
DDR5内存与DDR4内存性能差异2024-11-29 6941
-
德明利推出CKD DDR5内存条 为AI PC提供稳定高频内存解决方案2026-04-03 2371
全部0条评论

快来发表一下你的评论吧 !
