

大数据分析到底需要多少种工具_大数据分析总结
人工智能
描述
越来越多的应用涉及到大数据,不幸的是所有大数据的属性,包括数量、速度、多样性等等都是描述了数据库不断增长的复杂性。那么大数据给我们带来了什么好处呢?大数据最大的好处在于能够让我们从这些数据中分析出很多智能的、深入的、有价值的信息。
最近比较了179种不同的分类学习方法(分类学习算法)在121个数据集上的性能,发现Random Forest(随机森林)和SVM(支持向量机)分类准确率最高,在大多数情况下超过其他方法。本文针对“大数据分析到底需要多少种工具?”
分类方法大比武
大数据分析主要依靠机器学习和大规模计算。机器学习包括监督学习、非监督学习、强化学习等,而监督学习又包括分类学习、回归学习、排序学习、匹配学习等(见图1)。分类是最常见的机器学习应用问题,比如垃圾邮件过滤、人脸检测、用户画像、文本情感分析、网页归类等,本质上都是分类问题。分类学习也是机器学习领域,研究最彻底、使用最广泛的一个分支。
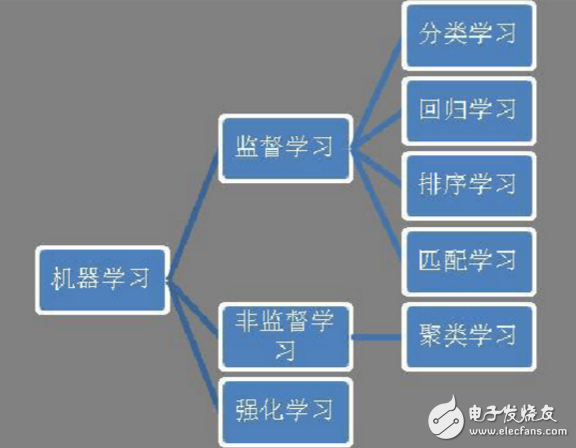
图1机器学习分类体系
最近、Fernández-Delgado等人在JMLR(Journal of Machine Learning Research,机器学习顶级期刊)杂志发表了一篇有趣的论文。他们让179种不同的分类学习方法(分类学习算法)在UCI 121个数据集上进行了“大比武”(UCI是机器学习公用数据集,每个数据集的规模都不大)。结果发现Random Forest(随机森林)和SVM(支持向量机)名列第一、第二名,但两者差异不大。在84.3%的数据上、Random Forest压倒了其它90%的方法。也就是说,在大多数情况下,只用Random Forest 或 SVM事情就搞定了。
几点经验总结
大数据分析到底需要多少种机器学习的方法呢?围绕着这个问题,我们看一下机器学习领域多年得出的一些经验规律。
大数据分析性能的好坏,也就是说机器学习预测的准确率,与使用的学习算法、问题的性质、数据集的特性包括数据规模、数据特征等都有关系。
一般地,Ensemble方法包括Random Forest和AdaBoost、SVM、Logistic Regression 分类准确率最高。
没有一种方法可以“包打天下”。Random Forest、SVM等方法一般性能最好,但不是在什么条件下性能都最好。
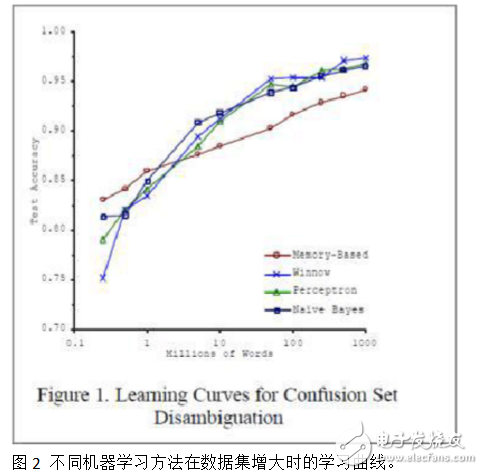
不同的方法,当数据规模小的时候,性能往往有较大差异,但当数据规模增大时,性能都会逐渐提升且差异逐渐减小。也就是说,在大数据条件下,什么方法都能work的不错。参见图2中Blaco & Brill的实验结果。
对于简单问题,Random Forest、SVM等方法基本可行,但是对于复杂问题,比如语音识别、图像识别,最近流行的深度学习方法往往效果更好。深度学习本质是复杂模型学习,是今后研究的重点。
在实际应用中,要提高分类的准确率,选择特征比选择算法更重要。好的特征会带来更好的分类结果,而好的特征的提取需要对问题的深入理解。
应采取的大数据分析策略
建立大数据分析平台时,选择实现若干种有代表性的方法即可。当然,不仅要考虑预测的准确率,还有考虑学习效率、开发成本、模型可读性等其他因素。大数据分析平台固然重要,同时需要有一批能够深入理解应用问题,自如使用分析工具的工程师和分析人员。
只有善工利器,大数据分析才能真正发挥威力。
在工具学习上,入门工具推荐两类:SQL(Structured Query Language)、Microsoft Office Excel,进阶工具推荐:SPSS Clementine/Python。
1、SQL
SQL是数据提取工具,大中型企业都会建立自己的数据库系统,常用数据会建立数据报表系统(常说的BI系统,即business intelligence),供业务人员使用。但深入业务分析需要更多的底层数据,报表系统里没有呈现的数据,这时就需要使用SQL工具提取数据库系统数据。
SQL工具很多,有oracle、mysql、sqlserver、hive等,除了细微差异,大多数SQL语句都通用。
SQL工具学习很容易,真正需要下功夫的是对数据库表结构的了解。从常用数据表了解,摸清数据指标及含义,建立起表结构间关系,完成日常工作数据提取工作为要。有精力的童鞋可以再去探索非常用数据表。
2、Microsoft Office Excel
Excel应该是所有数据分析师的入门工具。除了一些常用功能使用外,就是使用数据透视表和多学习内嵌函数,能省去不少工作量。除了数据量级处理有限外,Excel功能强大不能仅仅用强大来形容。高阶Excel学习,可以继续了解宏使用。
3、SPSS Clementine/Python
在数据分析进阶路上,还有一类工具是:数据建模工具,如SPSS Clementine、R、Python等。大数据时代,数据维度过于丰富,数据量级过于庞大,对于未知数据探索,手动计算发现数据关系的工作量已经过于繁重,交给这些数据模型工具就简单多了。其内嵌了大量精细的数据算法,我们需要做的就是掌握统计理论,掌握算法原理,输入规范的数据,等待模型的结果。当然,对模型的掌握,结论的解读,业务的理解,都是使用建模工具必须要学习的
下面我总结了分析大数据的5个方面。
1. Analytic Visualizations(可视化分析)
不管是对数据分析专家还是普通用户,数据可视化是数据分析工具最基本的要求。可视化可以直观的展示数据,让数据自己说话,让观众听到结果。
2. Data Mining Algorithms(数据挖掘算法)
可视化是给人看的,数据挖掘就是给机器看的。集群、分割、孤立点分析还有其他的算法让我们深入数据内部,挖掘价值。这些算法不仅要处理大数据的量,也要处理大数据的速度。
3. Predictive Analytic Capabilities(预测性分析能力)
数据挖掘可以让分析员更好的理解数据,而预测性分析可以让分析员根据可视化分析和数据挖掘的结果做出一些预测性的判断。
4. Semantic Engines(语义引擎)
我们知道由于非结构化数据的多样性带来了数据分析的新的挑战,我们需要一系列的工具去解析、提取、分析数据。语义引擎需要被设计成能够从“文档”中智能提取信息。
5. Data Quality and Master Data Management(数据质量和数据管理)
数据质量和数据管理是一些管理方面的最佳实践。通过标准化的流程和工具对数据进行处理可以保证一个预先定义好的高质量的分析结果。
假如大数据真的是下一个重要的技术革新的话,我们最好关注大数据能给我们带来的好处,而不仅仅是挑战。
-
Quick BI助力云上大数据分析---深圳云栖大会2018-04-03 3165
-
数据分析需要的技能2018-04-10 3341
-
大数据分析逻辑2018-10-08 2455
-
工业大数据分析平台的应用价值探讨2018-11-12 3615
-
Get职场新知识:做分析,用大数据分析工具2023-12-05 3403
-
什么是大数据分析?大数据分析的含义与目前形式2018-10-12 17361
-
什么叫大数据分析2018-11-10 32619
-
BI大数据分析系统,大数据可视化分析平台2019-02-13 1739
-
大数据分析工具有哪些2019-02-28 13230
-
大数据分析如何来增强2020-01-26 1743
-
Hadoop的Nuts和Bolts大数据分析2020-03-20 3647
-
还在为大数据分析工具发愁?以下是2021最值得推荐的大数据分析工具2021-03-05 3040
-
一个好的大数据分析工具需要做到哪些?_光点科技2022-12-30 1575
-
什么是大数据分析2023-05-19 3087
-
raid 在大数据分析中的应用2024-11-12 1405
全部0条评论

快来发表一下你的评论吧 !
