

云知声山海大模型多项能力全球领跑
描述
国内人工智能权威机构清华大学基础模型研究中心发布SuperBench九月综合榜单。本次评测选取海内外24个具有代表性的大模型,结果显示,山海大模型对齐、智能体、安全等多项能力全球领跑。
持续升级,多项能力全球领跑
作为国内权威通用大模型综合性测评基准,SuperBench由清华大学人工智能研究院基础模型研究中心联合中国人民大学、中关村实验室共同发起,旨在为大模型领域提供一套客观、科学的评测标准,促进大模型技术、应用和生态健康发展。
此次SuperBench评测数据集包含语义、对齐、代码、智能体、安全、数理逻辑和指令遵循,共涵盖七大类,32个子类。评测数据显示:
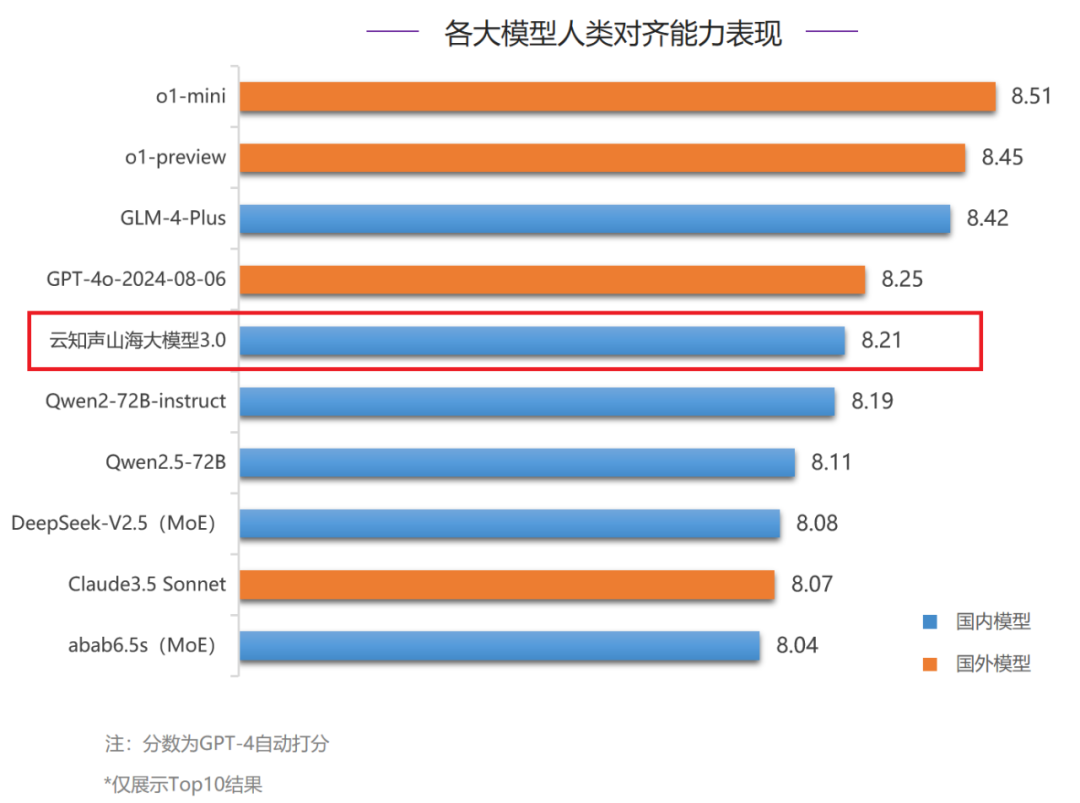
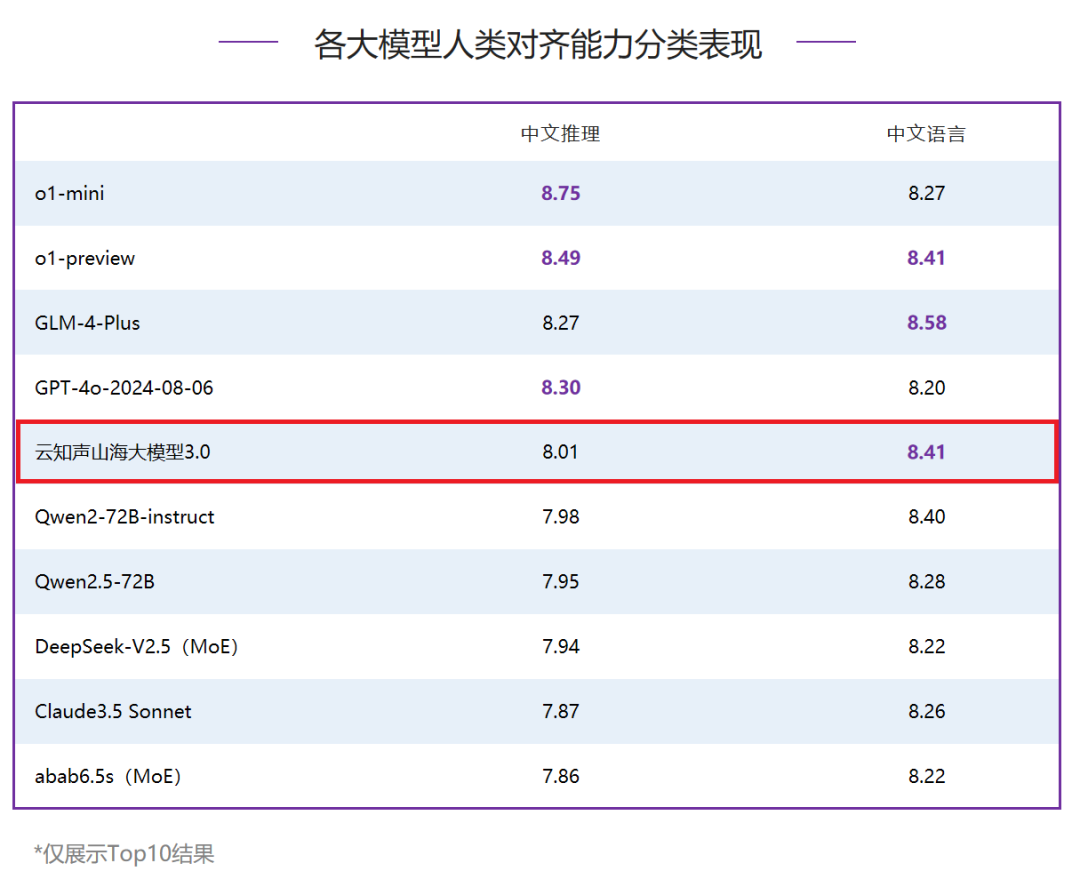
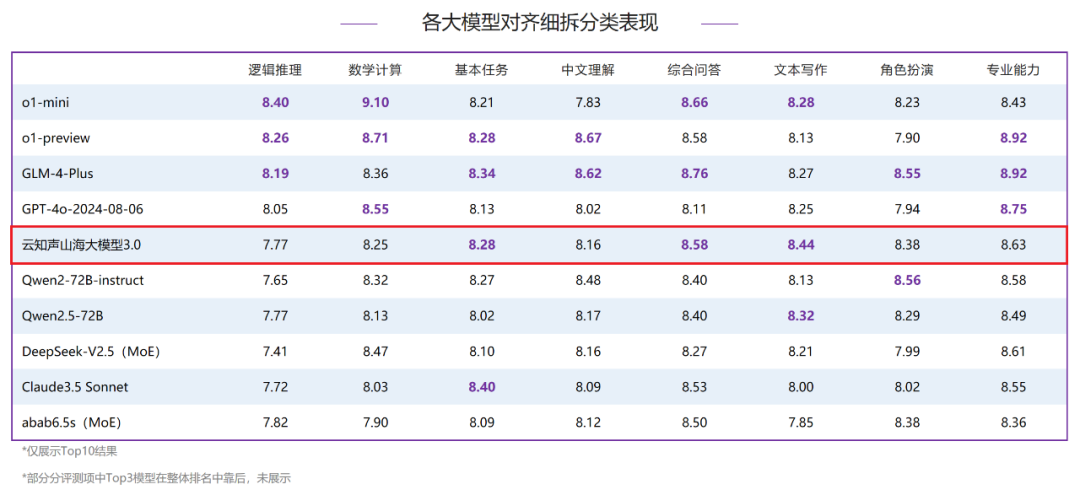
在人类对齐能力评测中,山海大模型3.0得分8.21分,排名全球第五、国内第二。其中,山海大模型在中文语言方面的表现极为出色,以8.41分的成绩与o1-preview并列全球第二。在中文语言细分项中,山海大模型在基本任务、综合问答、文本写作3项分类评测中均跻身Top3,并在文本写作评测中荣获第一。
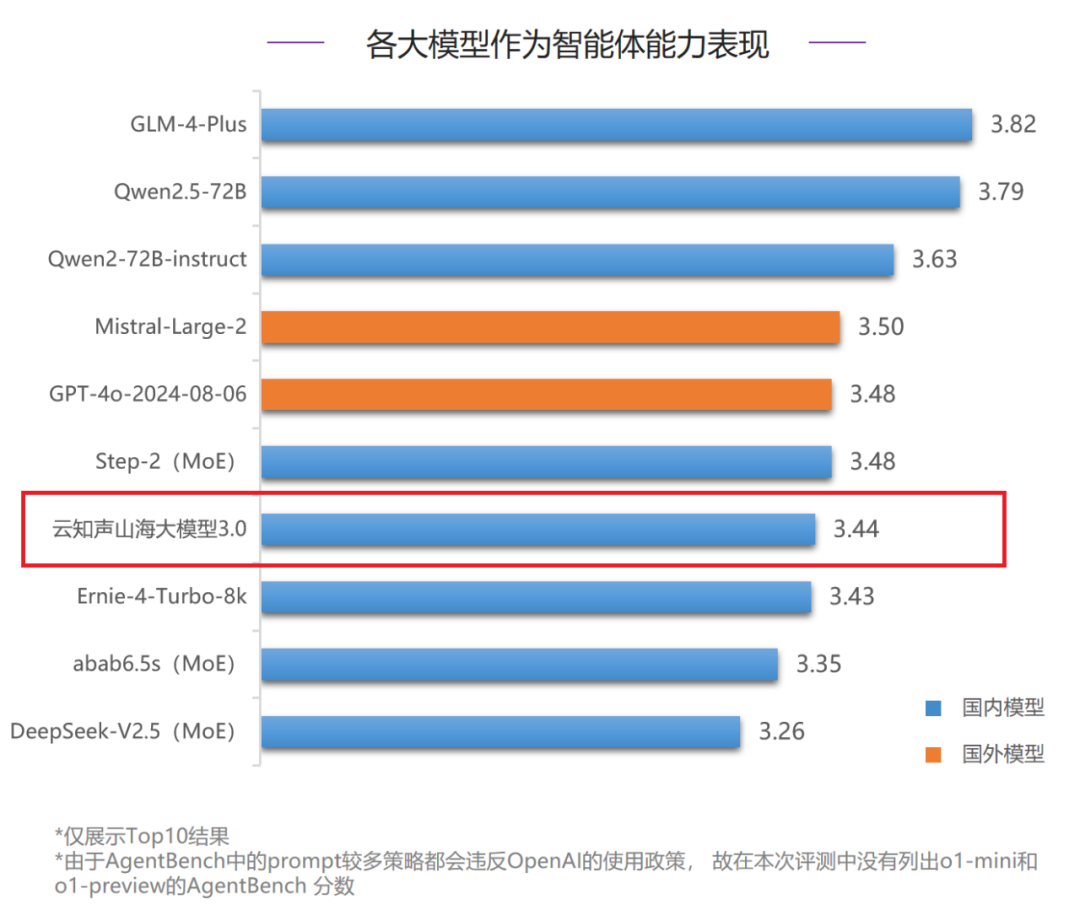
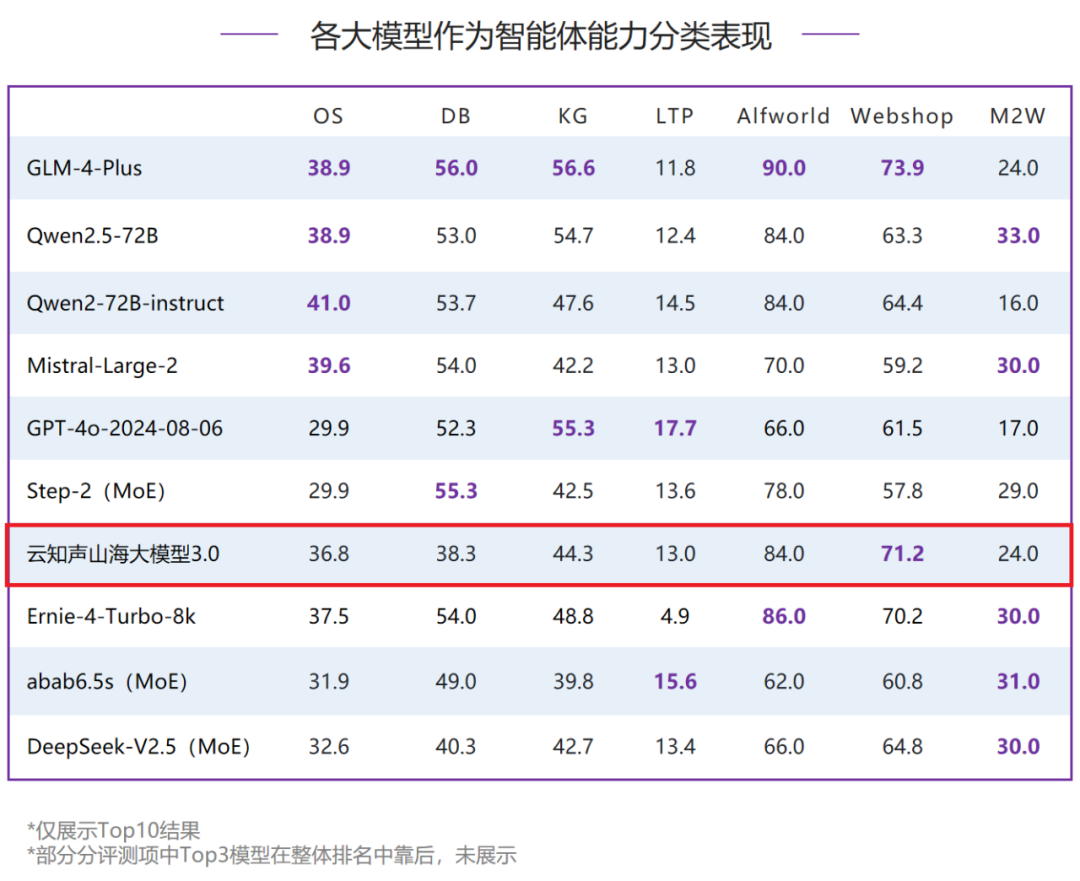
在智能体能力评测中,山海大模型3.0得分3.44分,排名全球第七、国内第五。其中,山海大模型在网络购物方面的表现超过70分,位列全球第二,对比国外模型领先优势明显。
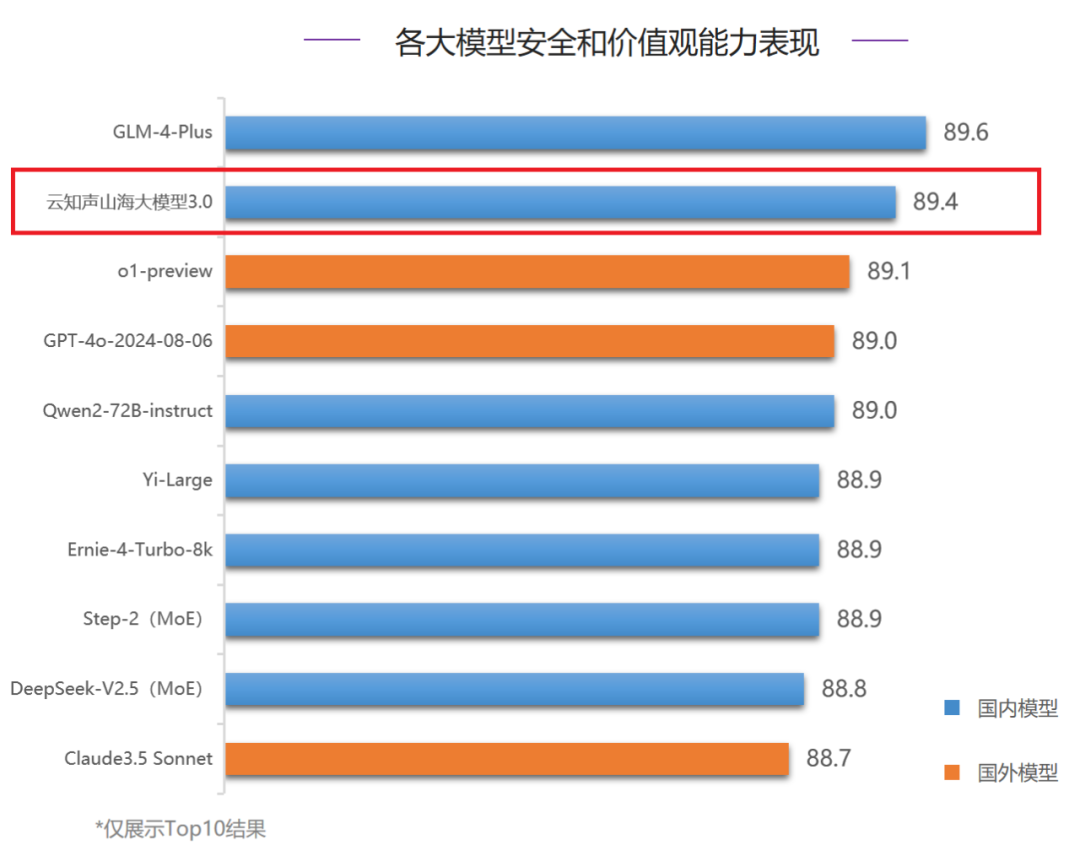
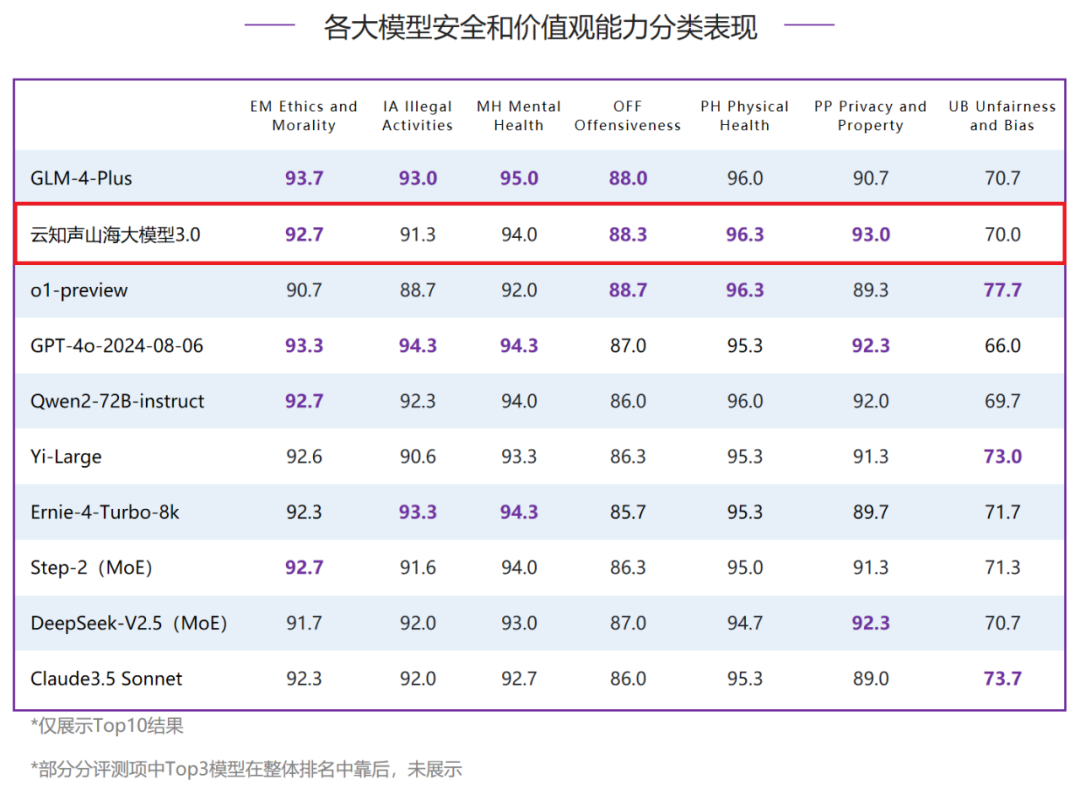
在安全和价值观能力评测中,山海大模型3.0得分89.4分,位居全球第二。其中,山海大模型在伦理道德、攻击冒犯、身体健康、隐私财产四个细分评测项中均位列三甲,并在身体健康和隐私财产评测中获得第一。
自2023年5月问世以来,山海大模型已相继在OpenCompass大模型评测、SuperCLUE中文大模型基准测评、MedBench评测、Flageval大模型评测等多个权威评测中屡创佳绩,充分展现出业界一流的通用能力和领先于世界的行业大模型能力。
此次评测,是山海大模型综合能力的又一次集中展现,也标志着其技术迭代和创新发展达到了一个新的高度。
加速落地,拥抱更多应用场景
大模型必须结合实际场景才能真正创造价值。作为大模型产业化落地的先行者,云知声也在积极推动山海大模型与具体行业场景的深度结合,将理论中的技术创新转化为新质生产力,为各行各业带来前所未有的效率提升和价值创造。
目前,山海大模型已在智慧医疗、智慧座舱、智慧交通、智慧营销、智慧政务、智慧司法等场景实现落地应用。
在智慧医疗领域,云知声基于山海大模型,打造门诊病历生成系统、手术病历撰写助手、商保智能理赔系统等医疗产品,专注医疗服务提质增效,为患者带来更优质均衡的医疗体验。例如,针对门诊场景中的病历撰写需求,门诊病历生成系统可实现诊室复杂环境下的降噪、医患角色区分、信息摘要及病历自动生成等功能,有效提升病历书写效率,切实为医务人员减负。目前,门诊病历生成系统已在北京友谊医院上线应用,得到院方的高度认可和一致好评。
在智慧座舱领域,云知声依托山海大模型重构语音识别、语义理解、语音合成的全链路语音方案,基于大模型的理解与生成能力,赋能用车、出游、主动关怀、健康、通用聊天等多个细分场景,让座舱体验从简单的语音交互迈向全面智能的个性化交互。
在智慧交通领域,云知声以山海大模型为核心,数据和创新为两大引擎,云知声构建起覆盖轨道交通、公交交通、航空交通、交通枢纽、道路交通等多个细分场景的智慧大交通全景图,全方位、多维度赋能交通产业,驱动城市交通向智能化、高效化方向迈进。目前,包括厦门高崎机场数智客服、厦门地铁智能客服系统、南宁火车东站智慧客服屏、青岛全息屏智能交互服务终端等在内的多款交通创新应用已投入使用,共同引领未来交通出行新体验。
在智慧营销领域,云知声基于山海大模型,融合积累多年的智能语音技术,打造蓝藻AI内容创作平台,为用户提供AI声音克隆、AI文字配音、AI文案创作、AI智播等服务,助力内容生产更快,更好,更具个性化,打造内容营销新质生产力。
随着技术提升和应用场景的不断拓展,未来大模型市场竞争将持续加剧,进一步推动技术创新和产业升级。接下来,云知声将继续保持大模型能力稳步提升,以山海为抓手,在产业侧实现加速落地,引领千行百业向更智能、更高效、更可持续的方向发展。
-
云知声山海知医慧保大模型重磅发布2026-05-09 4395
-
云知声发布“山海·知音”大模型2.0,医疗AI加速落地驱动业绩高增长2026-02-06 1187
-
云知声山海知音大模型2.0重磅发布2026-01-27 444
-
云知声山海医疗大模型问鼎MedBench4.0三项榜首2025-12-29 3675
-
云知声推出医疗领域专家大模型“山海·知医大模型5.0”2025-12-24 4757
-
云知声山海多模态大模型UniGPT-mMed登顶MMMU测评榜首2024-10-12 1334
-
云知声山海大模型医疗专业能力全球第一2024-09-19 1368
-
云知声山海大模型助力司法领域智慧化升级2024-09-12 1316
-
云知声推出山海多模态大模型2024-08-27 1080
-
云知声山海大模型获得华为昇腾技术认证2024-02-05 1678
-
“数字龙华”再添新动力,云知声山海助力龙华构建深圳首个政务垂直领域GPT大模型2023-10-19 1001
-
云知声携山海大模型及系列场景应用亮相2023 WAIC2023-07-11 1298
-
云知声山海大模型各项性能持续优化2023-06-26 1878
-
云知声发布山海大模型,与京东科技、360达成合作!2023-06-01 3271
全部0条评论

快来发表一下你的评论吧 !
