

机器学习与数据挖掘的关系
人工智能
描述
前言
在大多数非计算机专业人士以及部分计算机专业背景人士眼中,机器学习(Data Mining)以及数据挖掘(Machine Learning)是两个高深的领域。在笔者看来,这是一种过高”瞻仰“的习惯性错误理解(在这里我加了好多定语)。事实上,这两个领域与计算机其他领域一样都是在融汇理论和实践的过程中不断熟练和深入,不同之处仅在于渗透了更多的数学知识(主要是统计学),在后面的文章中我会努力将这些数学知识以一种更容易理解的方式讲解给大家。本文从基本概念出发浅析他们的关系和异同,不讲具体算法和数学公式。希望对大家能有所帮助。
几个相关示例
首先,给大家列举一些生活中与数据挖掘、机器学习相关的应用示例以帮助大家更好的理解。
示例1(关联问题):
经常去超市的同学可能会发现,我们事先在购物清单上列举好的某些商品可能会被超市阿姨摆放在相邻的区域。例如, 面包柜台旁边会摆上黄油、面条柜台附近一定会有老干妈等等。这样的物品摆放会让我们的购物过程更加快捷、轻松。
那么如何知道哪些物品该摆放在一块?又或者用户在购买某一个商品的情况下购买另一个商品的概率有多大?这就要利用关联数据挖掘的相关算法来解决。
示例2(分类问题):
在嘈杂的广场上,身边人来人往。仔细观察他们的外貌、衣着、言行等我们会不自觉地断论这个人是新疆人、东北人或者是上海人。又例如,在刚刚结束的2015NBA总决赛中,各类权威机构会大量分析骑士队与勇士队的历史数据从而得出骑士队或者勇士队是否会夺冠的结论。
在上述第一个例子中,由于地域众多,在对人进行地域分类的时候这是一个典型的多分类问题。而在第二个例子中各类机构预测勇士队是否会战胜骑士队夺冠,这是一个二分类问题,其结果只有两种。二分类问题在业界的出镜率异常高,例如在推荐系统中预测一个人是否会买某个商品、其他诸如地震预测、火灾预测等等。
示例3(聚类问题):
”物以类聚,人以群分“,生活中到处都有聚类问题的影子。假设银行拥有若干客户的历史消费记录,现在由于业务扩张需要新增几款面对不同人群的理财产品,那么如何才能准确的将不同的理财产品通过电话留言的方式推荐给不同的人群?这便是一个聚类问题,银行一般会将所有的用户进行聚类,有相似特征的用户属于同一个类别,最后将不同理财产品推荐给相应类别的客户。
示例4(回归问题):
回归问题或者称作预测问题同样也是一个生活中相当接地气的应用。大家知道,证券公司会利用历史数据对未来一段时间或者某一天的股票价格走势进行预测。同样,房地产商也会根据地域情况对不同面积楼层的房产进行定价预测。
上述两个示例都是回归问题的典型代表,这类问题往往根据一定的历史数据对某一个指定条件下的目标预测一个实数值。
相信经过上面通俗易懂的示例,大家应该初步了解数据挖掘以及机器学习会应用到哪些问题之上(这里列举的四类问题是很常见的,当然还有例如异常检测等应用),这就解决了面对一个新问题三要素中的Why。下面解释什么是机器学习与数据挖掘(即What)以及他们的关系和异同点。
数据挖掘
数据挖掘(Data mining),又译为资料探勘、数据采矿。它是数据库知识发现(英语:Knowledge-Discovery in Databases,简称:KDD)中的一个步骤。数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。
从上面的定义可以看出数据挖掘相对于机器学习而言是一个更加偏向应用的领域。实际上,数据挖掘是一门涉及面很广的交叉学科,在处理各种问题时,只要我们清楚了业务逻辑那么就可以将问题转换为挖掘问题。
数据挖掘的处理过程一般包括数据预处理(ETL、数据清洗、数据集成等),数据仓库(可以是DBMS、大型数据仓库以及分布式存储系统)与OLAP,使用各种算法(主要是机器学习的算法)进行挖掘以及最后的评估工作。
简言之,数据挖掘是一系列的处理过程,最终的目的是从数据中挖掘出你想要的或者意外收获的信息。下图展示了数据挖掘的众多应用领域。
机器学习
在上一节,我们初步讨论了数据挖掘的相关概念, 这一节我们继续讨论机器学习的基础知识、学习方式、常用算法等。
机器学习这门学科所关注的问题是:计算机程序如何随着经验积累自动提高性能。——Tom Mitchell
上述定义是Tom Mitchell在其著作《机器学习》中给出的定义。这个定义简单明了但是却蕴含了太多东西。
通俗的来将,我们写一段程序让计算机自己进行一个学习过程,直到达到一个满意程度。那么学习的目的是什么?怎样学习?满意程度又是如何定义的呢?
通常,假设我们的目标是一个function f,我们会给计算机提供一定的训练数据让其进行学习训练,每一次的学习会训练出一个hypothesis h,当h和f随着计算机不断学习越来越接近时,就说h越来越达到满意程度。而满意程度的度量是用误差e来度量的(针对不同情况有不同的方式)。更简单的说,机器学习就是通过数据训练找一个合适的目标函数的过程。而目前,机器学习学科应用到了大量的统计学知识,我们也称其为统计机器学习。
下面给大家解释一下必须知道的几个概念。
学习方式
根据数据类型的不同,对一个问题的建模有不同的方式。将算法按照学习方式分类是一个不错的想法,这样可以让人们在建模和算法选择的时候考虑能根据输入数据来选择最合适的算法来获得最好的结果。在机器学习领域,有几种主要的学习方式:
1.监督学习(supervised learning)
在监督式学习下,每组训练数据有一个明确的标识或结果,如对人按地域分类中的“新疆”、“上海”、“东别”等属于地域标识。在建立预测模型的时候,监督式学习建立一个学习过程,将预测结果与“训练数据”的实际结果进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率。
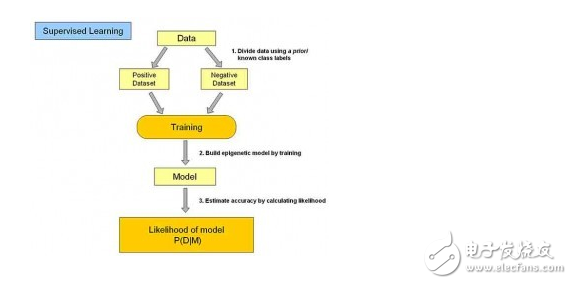
上述示例中的分类问题和回归问题都属于监督学习范畴。其中常用的分类算法包括:决策树分类法(Decision Tree)(参考我之前的文章),朴素贝叶斯分类算法(Native Bayesian Classifier)、基于支持向量机(SVM)的分类器、神经网络法(Neural Network)、k-最近邻法(k-nearest neighbor,kNN)等。
2.非监督式学习(unsupervised learning)
在非监督式学习中,数据并不被标识,学习模型是为了推断出数据的一些内在结构。前面四个示例中的关联问题和聚类问题属于非监督学习的范畴。关联问题中常见算法包括Apriori(该算法基于Spark的并行化算法参考我之前文章)、FP-Growth以及Eclat等,而聚类问题中最经典的算法当属k-Means。
3.半监督式学习(semi-supervised learning)
在半监督式学习学习方式下,输入数据部分被标识,部分没有被标识,这种学习模型可以用来进行预测,但是模型首先需要学习数据的内在结构以便合理的组织数据来进行预测。应用场景包括分类和回归,算法包括一些对常用监督式学习算法的延伸,这些算法首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。如图论推理算法(Graph Inference)或者拉普拉斯支持向量机(Laplacian SVM.)等。
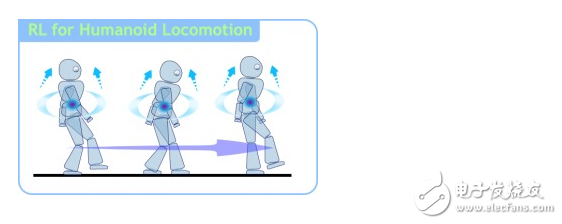
4.强化学习(reinforcement learning)
在这种学习模式下,输入数据作为对模型的反馈,不像监督模型那样,输入数据仅仅是作为一个检查模型对错的方式,在强化学习下,输入数据直接反馈到模型,模型必须对此立刻作出调整。常见的应用场景包括动态系统以及机器人控制等。常见算法包括Q-Learning以及时间差学习(Temporal difference learning)
数据挖掘与机器学习的关系
在上面我们分别介绍了机器学习与数据挖掘的基本概念,应用,相关算法等内容。接下来继续讨论两者的关系与异同。
统计学——1749年
人工智能——1940年
机器学习——1946年
数据挖掘——1980年
从历史的发展可以看出数据挖掘是一门新兴学科,其建立在强有力的知识体系之上,使用了大量的机器学习算法,同时根据上一节的叙述,数据挖掘也使用了一系列的工程技术。而机器学习则是以统计学为支撑的一门偏理论的学科,其不需要考虑诸如数据仓库,OLAP等应用工程技术。
总结
机器学习是一门更加偏向理论性学科,其目的是为了让计算机不断学习找到接近目标函数f的假设h。而数据挖掘则是使用了包括机器学习算法在内的众多知识的一门应用学科,它主要是使用一系列处理方法挖掘数据背后的信息。
-
机器学习与数据挖掘方法和应用2023-09-26 662
-
机器学习与数据挖掘的对比与区别2023-08-17 2266
-
机器学习和数据挖掘的关系2022-06-29 6440
-
人工智能、机器学习、数据挖掘有什么区别2020-05-14 3457
-
人工智能、数据挖掘、机器学习和深度学习的关系2020-03-16 2740
-
代码实例及详细资料带你入门Python数据挖掘与机器学习2019-03-03 3954
-
深度学习与数据挖掘的关系2018-07-04 2866
-
《机器学习与数据挖掘:方法和应用》2018-06-27 941
-
机器学习与数据挖掘的关系2018-01-05 5307
-
【成都】招聘机器学习/数据挖掘/信号与信息处理工程师(可实习)2017-08-18 2468
全部0条评论

快来发表一下你的评论吧 !
