

深度学习之GPU硬件选型
显卡
描述
深度学习在2012年大放异彩,gpu计算也走入了人们的视线之中,它使得大规模计算神经网络成为可能。人们可以通过07年推出的CUDA(Compute Unified Device Architecture)用代码来控制gpu进行并行计算。本文首先根据显卡一些参数来推荐何种情况下选择何种gpu显卡,然后谈谈跟cuda编程比较相关的硬件架构。
1.选择怎样的GPU型号
这几年主要有AMD和NVIDIA在做显卡,到目前为止,NVIDIA公司推出过的GeForce系列卡就有几百张[1],虽然不少都已经被淘汰了,但如何选择适合的卡来做算法也是一个值得思考的问题,Tim Dettmers[2]的文章给出了很多有用的建议,根据自己的理解和使用经历(其实只用过GTX 970…)我也给出一些建议。
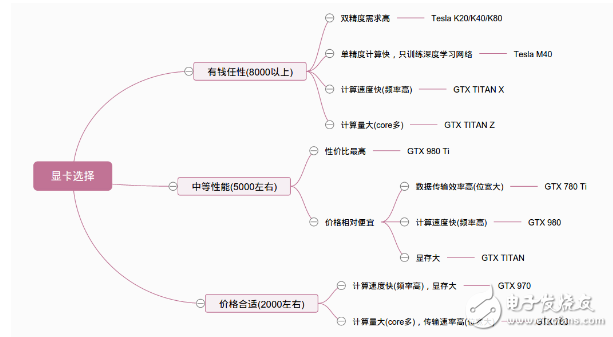
179上面并没有考虑笔记本的显卡,做算法加速的话还是选台式机的比较好。性价比最高的我觉得是GTX 980ti,从参数或者一些用户测评来看,性能并没有输给TITAN X多少,但价格却便宜不少。从图1可以看出,价位差不多的显卡都会有自己擅长的地方,根据自己的需求选择即可。要处理的数据量比较小就选择频率高的,要处理的数据量大就选显存大core数比较多的,有double的精度要求就最好选择kepler架构的。tesla的M40是专门为深度学习制作的,如果只有深度学习的训练,这张卡虽然贵,企业或者机构购买还是比较合适的(百度的深度学习研究院就用的这一款[3]),相对于K40单精度浮点运算性能是4.29Tflops,M40可以达到7Tflops。QUADRO系列比较少被人提起,它的M6000价格比K80还贵,性能参数上也并没有好多少。
在挑选的时候要注意的几个参数是处理器核心(core)、工作频率、显存位宽、单卡or双卡。有的人觉得位宽最重要,也有人觉得核心数量最重要,我觉得对深度学习计算而言处理器核心数和显存大小比较重要。这些参数越多越高是好,但是程序相应的也要写好,如果无法让所有的core都工作,资源就被浪费了。而且在购入显卡的时候,如果一台主机插多张显卡,要注意电源的选择。
2.一些常见的名称含义
上面聊过了选择什么样的gpu,这一部分介绍一些常见名词。随着一代一代的显卡性能的更新,从硬件设计上或者命名方式上有很多的变化与更新,其中比较常见的有以下一些内容。
gpu架构:Tesla、Fermi、Kepler、Maxwell、Pascal
芯片型号:GT200、GK210、GM104、GF104等
显卡系列:GeForce、Quadro、Tesla
GeForce显卡型号:G/GS、GT、GTS、GTX
gpu架构指的是硬件的设计方式,例如流处理器簇中有多少个core、是否有L1 or L2缓存、是否有双精度计算单元等等。每一代的架构是一种思想,如何去更好完成并行的思想,而芯片就是对上述思想的实现,芯片型号GT200中第二个字母代表是哪一代架构,有时会有100和200代的芯片,它们基本设计思路是跟这一代的架构一致,只是在细节上做了一些改变,例如GK210比GK110的寄存器就多一倍。有时候一张显卡里面可能有两张芯片,Tesla k80用了两块GK210芯片。这里第一代的gpu架构的命名也是Tesla,但现在基本已经没有这种设计的卡了,下文如果提到了会用Tesla架构和Tesla系列来进行区分。
而显卡系列在本质上并没有什么区别,只是NVIDIA希望区分成三种选择,GeFore用于家庭娱乐,Quadro用于工作站,而Tesla系列用于服务器。Tesla的k型号卡为了高性能科学计算而设计,比较突出的优点是双精度浮点运算能力高并且支持ECC内存,但是双精度能力好在深度学习训练上并没有什么卵用,所以Tesla系列又推出了M型号来做专门的训练深度学习网络的显卡。需要注意的是Tesla系列没有显示输出接口,它专注于数据计算而不是图形显示。
最后一个GeForce的显卡型号是不同的硬件定制,越往后性能越好,时钟频率越高显存越大,即G/GS《GT《GTS《GTX。
3.gpu的部分硬件
这一部分以下面的GM204硬件图做例子介绍一下GPU的几个主要硬件(图片可以点击查看大图,不想图片占太多篇幅)[4]。这块芯片它是随着GTX 980和970一起出现的。一般而言,gpu的架构的不同体现在流处理器簇的不同设计上(从Fermi架构开始加入了L1、L2缓存硬件),其他的结构大体上相似。主要包括主机接口(host interface)、复制引擎(copy engine)、流处理器簇(Streaming Multiprocessors)、图形处理簇GPC(graphics processing clusters)、内存等等。
39主机接口,它连接了gpu卡和PCI Express,它主要的功能是读取程序指令并分配到对应的硬件单元,例如某块程序如果在进行内存复制,那么主机接口会将任务分配到复制引擎上。
复制引擎(图中没有表示出来),它完成gpu内存和cpu内存之间的复制传递。当gpu上有复制引擎时,复制的过程是可以与核函数的计算同步进行的。随着gpu卡的性能变得强劲,现在深度学习的瓶颈已经不在计算速度慢,而是数据的读入,如何合理的调用复制引擎是一个值得思考的问题。
流处理器簇SM是gpu最核心的部分,这个翻译参考的是GPU编程指南,SM由一系列硬件组成,包括warp调度器、寄存器、Core、共享内存等。它的设计和个数决定了gpu的计算能力,一个SM有多个core,每个core上执行线程,core是实现具体计算的处理器,如果core多同时能够执行的线程就多,但是并不是说core越多计算速度一定更快,最重要的是让core全部处于工作状态,而不是空闲。不同的架构可能对它命名不同,kepler叫SMX,maxwell叫SMM,实际上都是SM。而GPC只是将几个sm组合起来,在做图形显示时有调度,一般在写gpu程序不需要考虑这个东西,只要掌握SM的结构合理的分配SM的工作即可。
图中的内存控制器控制的是L2内存,每个大小为512KB。
4.流处理器簇的结构
上面介绍的是gpu的整个硬件结构,这一部分专门针对流处理器簇SM来分析它内部的构造是怎样的。首先要明白的是,gpu的设计是为了执行大量简单任务,不像cpu需要处理的是复杂的任务,gpu面对的问题能够分解成很多可同时独立解决的部分,在代码层面就是很多个线程同时执行相同的代码,所以它相应的设计了大量的简单处理器,也就是stream process,在这些处理器上进行整形、浮点型的运算。下图给出了GK110的SM结构图。它属于kepler架构,与之前的架构比较大的不同是加入了双精度浮点运算单元,即图中的DP Unit。所以用kepler架构的显卡进行双精度计算是比较好的。
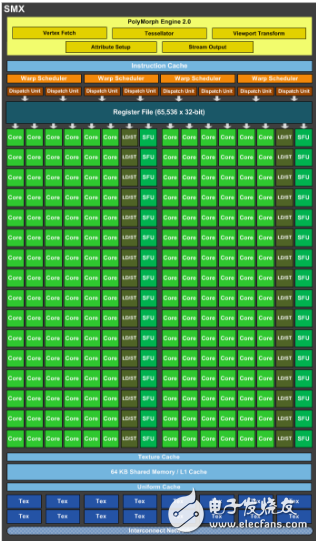
上面提到过的一个SM有多个core或者叫流处理器,它是gpu的运算单元,做整形、浮点型计算。可以认为在一个core上一次执行一个线程,GK110的一个SM有192个core,因此一次可以同时执行192个线程。core的内部结构可以查看[5],实现算法一般不会深究到core的结构层面。SFU是特殊函数单元,用来计算log/exp/sin/cos等。DL/ST是指Load/Store,它在读写线程执行所需的全局内存、局部内存等。
一个SM有192个core,8个SM有1536个core,这么多的线程并行执行需要有统一的管理,假如gpu每次在1536个core上执行相同的指令,而需要计算这一指令的线程不足1536个,那么就有core空闲,这对资源就是浪费,因此不能对所有的core做统一的调度,从而设计了warp(线程束)调度器。32个线程一组称为线程束,32个线程一组执行相同的指令,其中的每个thread称为lane。一个线程束接受同一个指令,里面的32个线程同时执行,不同的线程束可执行不同指令,那么就不会出现大量线程空闲的问题了。但是在线程束调度上还是存在一些问题,假如某段代码中有if…else…,在调度一整个线程束32个线程的时候不可能做到给thread0~15分配分支1的指令,给thread16~31分配分支2的指令(实际上gpu对分支的控制是,所有该执行分支1的线程执行完再轮到该执行分支2的线程执行),它们获得的都是一样的指令,所以如果thread16~31是在分支2中它们就需要等待thread0~15一起完成分支1中的计算之后,再获得分支2的指令,而这个过程中,thread0~15又在等待thread16~31的工作完成,从而导致了线程空闲资源浪费。因此在真正的调度中,是半个warp执行相同指令,即16个线程执行相同指令,那么给thread0~15分配分支1的指令,给thread16~31分配分支2的指令,那么一个warp就能够同时执行两个分支。这就是图中Warp Scheduler下为什么会出现两个dispatch的原因。
另外一个比较重要的结构是共享内存shared memory。它存储的内容在一个block(暂时认为是比线程束32还要大的一些线程个数集合)中共享,一个block中的线程都可以访问这块内存,它的读写速度比全局内存要快,所以线程之间需要通信或者重复访问的数据往往都会放在这个地方。在kepler架构中,一共有64kb的空间大小,供共享内存和L1缓存分配,共享内存实际上也可看成是L1缓存,只是它能够被用户控制。假如共享内存占48kb那么L1缓存就占16kb等。在maxwell架构中共享内存和L1缓存分开了,共享内存大小是96kb。而寄存器的读写速度又比共享内存要快,数量也非常多,像GK110有65536个。
此外,每一个SM都设置了独立访问全局内存、常量内存的总线。常量内存并不是一块内存硬件,而是全局内存的一种虚拟形式,它跟全局内存不同的是能够高速缓存和在线程束中广播数据,因此在SM中有一块常量内存的缓存,用于缓存常量内存。
小结
本文谈了谈gpu的一些重要的硬件组成,就深度学习而言,我觉得对内存的需求还是比较大的,core多也并不是能够全部用上,但现在开源的库实在完整,想做卷积运算有cudnn,想做卷积神经网络caffe、torch,想做rnn有mxnet、tensorflow等等,这些库内部对gpu的调用做的非常好并不需用户操心,但了解gpu的一些内部结构也是很有意思的。
另,一开始接触GPU并不知道是做图形渲染的…所以有些地方可能理解有误,主要基于计算来讨论GPU的构造。
-
相比GPU和GPP,FPGA是深度学习的未来?2016-07-28 7773
-
FPGA在深度学习应用中或将取代GPU2024-03-21 1281
-
新手小白怎么学GPU云服务器跑深度学习?2024-06-11 2444
-
深度学习框架TensorFlow&TensorFlow-GPU详解2018-12-25 4341
-
Mali GPU支持tensorflow或者caffe等深度学习模型吗2022-09-16 3102
-
什么是深度学习?使用FPGA进行深度学习的好处?2023-02-17 2155
-
最基本的深度学习系统的硬件指南2017-09-22 1470
-
深度学习方案ASIC、FPGA、GPU比较 哪种更有潜力2018-02-02 11133
-
GPU和GPP相比谁才是深度学习的未来2019-10-18 1912
-
GPU 引领的深度学习2023-01-04 1402
-
深度学习如何挑选GPU?2023-07-12 1077
-
GPU的张量核心: 深度学习的秘密武器2023-09-26 2045
-
GPU在深度学习中的应用与优势2023-12-06 2697
-
深度学习GPU加速效果如何2024-10-17 1293
-
GPU深度学习应用案例2024-10-27 2663
全部0条评论

快来发表一下你的评论吧 !
