

Cyclone V FPGA在高带宽存储接口中的应用
接口/总线/驱动
描述
FPGA的开发相对于传统PC、单片机的开发有很大不同。FPGA以并行运算为主,以硬件描述语言来实现;相比于PC或单片机(无论是冯诺依曼结构还是哈佛结构)的顺序操作有很大区别,也造成了FPGA开发入门较难。
越来越多的应用场景都需要FPGA能够和外部存储器之间建立数据传输通道,如视频、图像处理等领域,并且对数据传输通道的带宽也提出了较大的需求,这就导致了FPGA和外部Memory接口的实际有效带宽成为了制约系统性能的瓶颈,所以Memoiy控制器的效能,则成为提升系统性能的关键要素。
存储器接口的底层架构
QuartusII 11.0及以后版本提供的Controller控制器均为High Performance ControllerII(HPC II),相对于早期提供的HPC,有了部分功能和性能上的升级和改进。CycloneII/IV使用的是ALTMEMPHY,而Cyclone V可以使用新的UniPHY架构。存储器接口的底层架构和外部接口如图1所示。
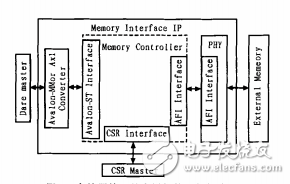
图1 存储器接口的底层架构和外部接口图
从图1可见,整个存储接口是由三部分组成的,Controller单元、PHY单元及一些相关接口。其中主要的便是Controller单元、PHY单元。Controller单元主要负责控制初始化、刷新等Memory的命令操作,还能够完成访问地址和数据的组织排序,支持大带宽、较高的工作频率。另外,Controller单元还支持数据重排,能够降低访问冲突,增加系统工作的效率。PHY单元工作在Controller单元和外部Memory之间,主要负责完成物理层的数据路径及数据路径的时序处理。
Controller单元和PHY单元之间是通过Altera PHYInterface,即AFI接口进行连接的。与标准的DDR PHYInterface,即DFI接口相比,AFI接口更加适合基于ALTMEMPHY和UniPHY的开发。AFI接口可以被认为是DFI接口的子集,是对DFI接口进行了少量的简化和修改而来的。
MPFE的功能及底层架构
在视频和图像处理领域,FPCA需要频繁地访问Memory接口,完成数据的写入和渎出操作。Cyclone V的HMC能够支持多端口前端的并行访问,极大地方便了读写数据交互的操作。多端口前端,即MPFE(Multi-port Front End),底层架构如图2所示。
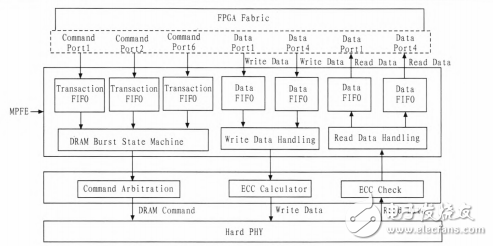
图2 MPFE底层架构图
MPFE可以使得FPGA的多个处理进程共享一个Memory的命令队列。这样不同的端口都可以访问Memory接口,完成对Memory的读写操作。MP FE都是基于Avalon总线的时序进行地址、命令和数据的交互的。在实际有效带宽一定的情况下,MPFE可以将带宽按照不同的需求分配到相应的端口。
如图2所示,MPFE是由6个命令FIFO,4个64bit位宽的读FIFO和4个64bit位宽的写FIFO组成,通过这些FIFO来完成命令和数据的交互。其中,读FIFO可以被配置为单向的读FIFO,写FIFO可以被配置为单向的写FIFO,也可以在一个Port里使用双向FIFO、此时该Port会调用1个读FIFO和1个写FIFO来完成。
如果前端的数据位宽比较大,也可以将FIFO拼接起来,组合为128bit或256bit位宽的FIFO,128bit位宽情况下,会调用2个读或写FIFO 256bit位宽情况下,会调用4个读或写FIFO。如果一个Port设置为256bit位宽,同时设置为双向FIFO.则该Port会消耗全部的读写FIFO,此时也就相当于将多端口前端作为单端口前端来使用了。
如果前端的数据位宽比较小,也可以将64bit位宽的FIFO设置为32bit位宽,此时仍会占用1个FIFO,高32bit的数据位宽则会闲置。
由此可见,MPFE在使用上十分灵活,能够适应不同的应用方式,满足FPGA内部不同逻辑模块对Memory的读写访问。
多端口前端的调度策略
MPFE本身相当于一个调度器,采用分时复用的方式,对来自不同端口的数据和命令进行调度。若干个端口之间的调度遵循两个条件,即端口的优先级(Priority)和权重(Weight)。优先级参数和权重参数是可以指定的,如图3所示,在IP例化时的Controller Settings界面中,手动填写端口的这两个参数值。
优先级参数可以在1~7之间任意指定,优先级参数值越大,代表该端口的优先级越高。高优先级的端口相对于低优先级的端口会被优先调度。优先级是一个绝对的参数,如果一个端口的优先级设置为7,则这个端口享有最高优先级,它在任何情况下都会被优先调度,这样另外的优先级为6或更低优先级的端口必须等待优先级为7的端口工作完成之后才会被调度。
如果两个端门的优先级一样,那么相对的优先级会取决于端口的权重参数。权重参数可以在0~31之间设置。为了避免高优先级的某个端口长时间占用接口总线的带宽,引入了加权循环调度算法(Weighted Round Robin,WRR),WRR算法仍然会优先处理高优先级的端口,但是低优先级的端口也不会出现不被调度的情况。WRR是根据端口权重与所有排队等待调度的端口的权重总和的比来平等地分配带宽。因此,在处理多个端口的高优先等级的业务时,可以确保每个端口都不会过度地占用接口的总线带宽。
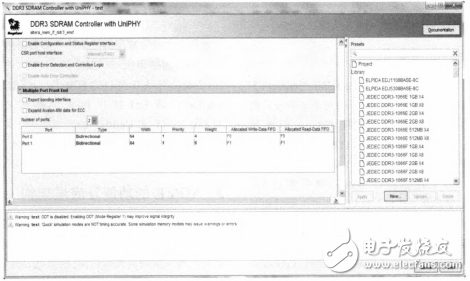
图3 指定端口的优先级和权重
在端口的优先级参数都一样的情况下,权重参数能够决定端口间相对的带宽分配,如图3所示,端口0和端口1的优先级均为1,权重参数值分別为4和6,则端口0和端口1分別会占用大致40%和60%的Memory接口总带宽。
HMC的ModelSim功能仿真
仿真过程不仅能够观察到HMC内部工作的时序,还能够大致测箅出HMC工作时的有效带宽。在系统设计开始阶段,可以用于评估Memory接口实际有效带宽是否满足设计需求。如图4和图5所示。

图4 HMC的ModelSim仿真图
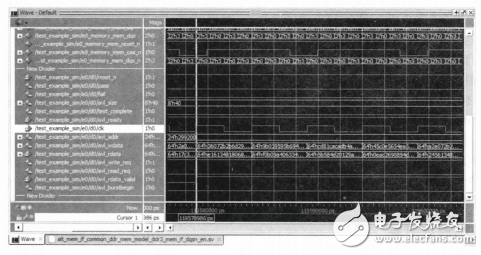
图5 HMC的ModelSim仿真图
-
Cyclone V器件:满足多领域需求的FPGA解决方案2026-03-29 276
-
Flash存储器在单片机接口中的应用综述2021-06-29 950
-
基于Cyclone V FPGA的高带宽存储接口应用2019-06-13 1713
-
Cyclone IV FPGA器件系列资料概述免费下载2018-11-22 1987
-
Cyclone IV 器件中的外部存储器接口2017-11-14 2810
-
Cyclone IV FPGA 器件系列概述2017-11-13 5230
-
【干活分享】Cyclone V FPGA技术精选十问十答2014-12-04 8015
-
Mouser提供业界领先的Altera Cyclone V低功耗FPGA2013-05-21 1536
-
怎样为自己的设计选择Altera Cyclone V FPGA?2013-02-26 2842
-
Altera公司 Cyclone V 28nm FPGA功耗优势2012-09-05 1359
-
Cyclone V SoC FPGA硬核处理器系统简介2012-09-04 5773
-
低功耗Cyclone IV FPGA2010-03-31 1812
-
Altera新Cyclone IV FPGA拓展了Cyclo2009-11-04 1691
-
在高清晰LCD HDTV 中使用Cyclone III FPGA2008-10-16 5181
全部0条评论

快来发表一下你的评论吧 !
