

斯坦福探索深度神经网络可解释性 决策树是关键
人工智能
描述
深度学习的热潮还在不断涌动,神经网络再次成为业界人士特别关注的问题,AI 的未来大有可期,而深度学习正在影响我们的日常生活。近日斯坦福大学给我们分享咯一则他对深度神经网络可解释性的探索的论文,我们去看看他是如理解的吧!
近日,斯坦福大学计算机科学博士生 Mike Wu 发表博客介绍了他对深度神经网络可解释性的探索,主要提到了树正则化。其论文《Beyond Sparsity: Tree Regularization of Deep Models for Interpretability》已被 AAAI 2018 接收。
近年来,深度学习迅速成为业界、学界的重要工具。神经网络再次成为解决图像识别、语音识别、文本翻译以及其他困难问题的先进技术。去年十月,Deepmind 发布了 AlphaGo 的更强版本,从头开始训练即可打败最优秀的人类选手和机器人,表明 AI 的未来大有可期。在业界,Facebook、谷歌等公司将深度网络集成在计算 pipeline 中,从而依赖算法处理每天数十亿比特的数据。创业公司,如 Spring、Babylon Health 正在使用类似的方法来颠覆医疗领域。深度学习正在影响我们的日常生活。
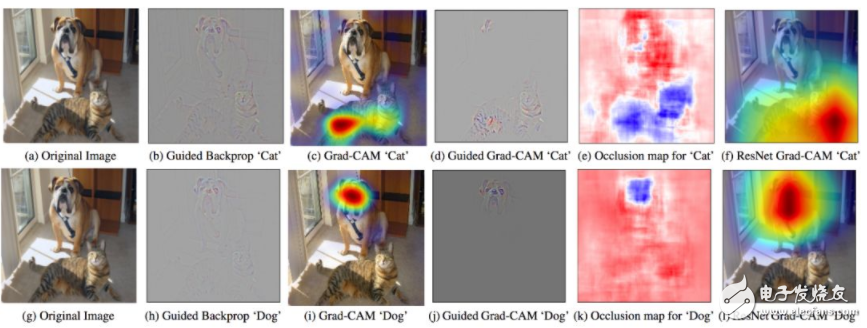
图 1:GradCam - 利用目标概念的梯度突出重要像素,从而创建决策的视觉解释。
但是深度学习是一个黑箱。我第一次听说它时,就对其工作原理非常费解。几年过去了,我仍然在探索合理的答案。尝试解释现代神经网络很难,但是至关重要。如果我们打算依赖深度学习制造新的 AI、处理敏感的用户数据,或者开药,那么我们必须理解这些模型的工作原理。
很幸运,学界人士也提出了很多对深度学习的理解。以下是几个近期论文示例:
Grad-Cam(Selvaraju et. al. 2017):使用最后卷积层的梯度生成热力图,突出显示输入图像中的重要像素用于分类。
LIME(Ribeiro et. al. 2016):使用稀疏线性模型(可轻松识别重要特征)逼近 DNN 的预测。
特征可视化(Olah 2017):对于带有随机噪声的图像,优化像素来激活训练的 DNN 中的特定神经元,进而可视化神经元学到的内容。
Loss Landscape(Li et. al. 2017):可视化 DNN 尝试最小化的非凸损失函数,查看架构/参数如何影响损失情况。

图 2:特征可视化:通过优化激活特定神经元或一组神经元,从而生成图像(Olah 2017)。
从上述示例中可见,学界对如何解释 DNN 存在不同见解。隔离单个神经元的影响?可视化损失情况?特征稀疏性?
什么是可解释性?
我们应该把可解释性看作人类模仿性(human simulatability)。如果人类可以在合适时间内采用输入数据和模型参数,经过每个计算步,作出预测,则该模型具备模仿性(Lipton 2016)。
这是一个严格但权威的定义。以医院生态系统为例:给定一个模仿性模型,医生可以轻松检查模型的每一步是否违背其专业知识,甚至推断数据中的公平性和系统偏差等。这可以帮助从业者利用正向反馈循环改进模型。
决策树具备模仿性
我们可以很轻松地看到决策树具备模仿性。例如,如果我想预测病人心脏病发作的风险,我可以沿着决策树的每个节点走下去,理解哪些特征可用于作出预测。
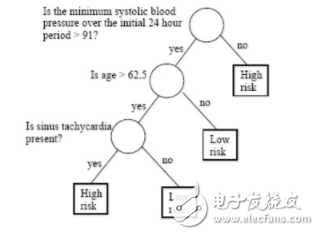
图 3:训练用于分类心脏病发作风险的决策树。这棵树最大路径长度为 3。
如果我们可以使用决策树代替 DNN,那么已经完成了。但是使用 DNN 尽管缺乏可解释性,但是它的能力远超过决策树。所以我们是否可以将决策树和 DNN 结合起来,构架具备模仿性的强大模型?
我们可以试着做一个类似 LIME 的东西,构建一个模拟决策树来逼近训练后的 DNN 的预测结果。但是训练深度神经网络时会出现很多局部极小值,其中只有部分极小值容易模仿。因此,用这种方法可能最后会陷于一个难以模仿的极小值(生成一个巨型决策树,无法在合理时间内走完)。
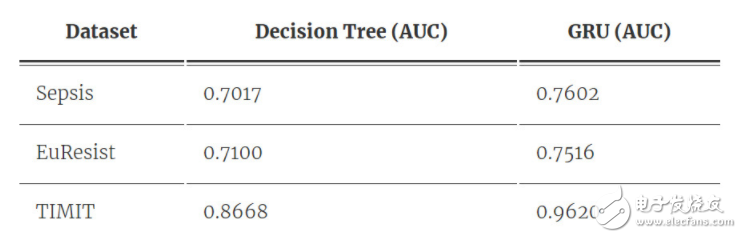
表 1:决策树和 RNN 在不同数据集上的性能。我们注意到 RNN 的预测能力比决策树优秀许多。
直接优化提高模仿性
如果我们想在优化过程中提高模仿性,则可以尝试找到更具可解释性的极小值。完美情况是,我们训练一个行为非常像(但并不是)决策树的 DNN,因为我们仍然想利用神经网络的非线性。
另一种方式是使用简单决策树正则化深度神经网络。我们称之为树正则化。
树正则化
若我们有包含 N 个序列的时序数据集,每一个序列有 T_n 个时间步。当没有限制时,我们可以假设它有二元输出。一般传统上,训练循环神经网络(RNN)可以使用以下损失函数:
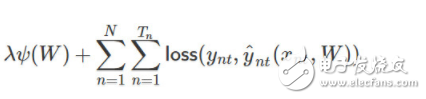
其中ψ为正则化器(即 L1 或 L2 正则化)、λ 为正则化系数或强度、W 为一组 RNN 的权重矩阵、y_nt 为单个时间步上的标注真值、y_nt hat 为单个时间步上的预测值。此外,损失函数一般可以选为交叉熵损失函数。
添加树正则化需要改变两个地方。第一部分是给定一些带权重 W 的 RNN,且权重 W 可以是部分已训练的,我们将 N 个长度为 T 的数据 X 传递到 RNN 中以执行预测。然后我们就能使用这 N 个数据对训练决策树算法,并尝试匹配 RNN 的预测。

图 4:在优化过程中的任意点,我们能通过一个简单的决策树逼近部分训练的 DNN。
因此,我们现在有了模拟 DT,但我们可以选择一个十分小或十分大的决策树,因此我们需要量化树的大小。
为了完成量化过程,首先我们需要考虑树的平均路径长度(APL)。对于单个样本,路径长度就等于游历树并作出预测的长度。例如,如图 3 所示,若有一个用来预测心脏病的决策树,那么假设输入 x 为 age=70。该样本下路径长度因为 70》62.5 而等于 2。因此平均路径长度可以简单地表示为 ∑ pathlength(x_n, y_n hat)。

图 5:给定一棵决策树与数据集,我们能计算平均路径长度以作为模拟、解释平均样本的成本。通过把这一项加入到目标函数,我们就能鼓励 DNN 生成简单的 DT 树并惩罚复杂而巨大的决策树。
因此我们最后能将损失函数改写为以下形式:
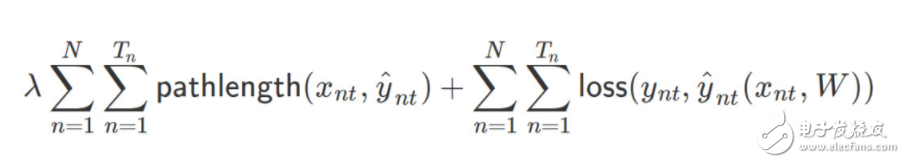
现在只有一个问题:决策树是不可微的。但我们可能真的比较希望能用 SGD 以实现更快速和便捷的最优化,因此我们也许可以考虑更具创造性的方法。
我们可以做的是添加一个代理模型,它可能是一个以 RNN 权重作为输入的多层感知机(MLP),并期望能输出平均路径长度的估计量,就好像我们在训练一个决策树一样。
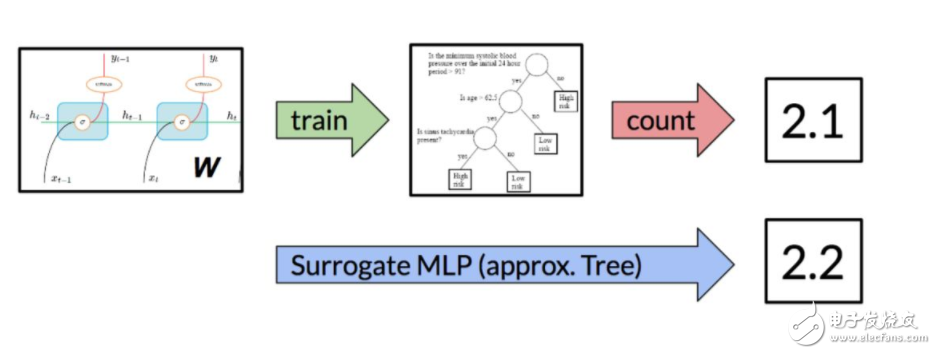
图 6:通过使用代理模型,我们可以利用流行的梯度下降算法来训练 DNN。为了训练一个代理模型,我们最小化标注真值和预测 APL 之间的 MSE。
当我们优化 RNN/DNN 时,每一个梯度下降步都会生成一组新的权重 W_i。对于每一个 W_i,我们能训练一个决策树并计算平均路径长度。在训练几个 epoch 之后,我们能创建一个大型数据集并训练代理 MLP。
训练过程会给定一个固定的代理,我们能定义正则化目标函数,并优化 RNN。若给定一个固定的 RNN,我们将构建一个数据集并优化 MLP。
小测试数据集
检查新技术有效性的一个好方法是在合成数据及上进行测试,在其中我们可以强调新技术提出的效益。
考虑以下的虚构数据集:给定单位二维坐标系统内的点 (x_i,y_i),定义一个抛物线决策函数。
y=5?(x?0.5)^2+0.4
我们在单位正方形 [0,1]×[0,1] 内均匀地随机采样 500 个点,所有在抛物线之上的点设为正的,在抛物线之下的点设为负的。我们通过随机翻转 10% 的边界附近(图 7 的两条灰色抛物线之间)的点以添加一些噪声。然后,随机分离出 30% 的点用作测试集。
我们训练了一个 3 层 MLP 用作分类器,其中第一层有 100 个节点,第二层有 100 个节点,第三层有 10 个节点。我们有意让该模型过度表达,以使其过拟合,并强调正则化的作用。
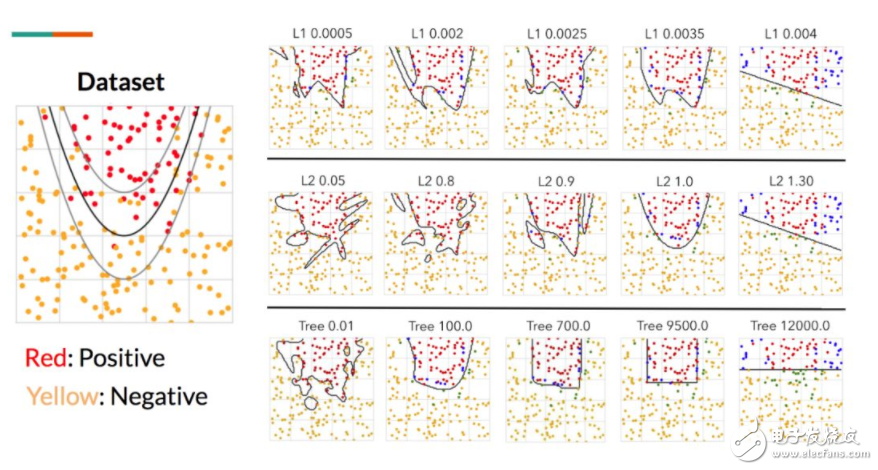
图 7:虚构的抛物线数据集。我们训练了一个深度 MLP,结合不同级别的 L1、L2 正则化和树正则化以测试最终决策边界之间的视觉差异。这里的关键之处在于,树正则化生成了坐标对齐的边界。然后我们用改变的正则化(L1、L2、树)和改变的强度λ训练了一系列的 MLP。我们可以通过描述单位正方形内所有点的行为并画出等高线以评估模型,从而逼近已学习的决策函数。图 7 展示了在不同参数设置下的已学习决策函数的并行对比。
正如预期,随着正则化强度增加,得到的决策函数也更简单(减少过拟合)。更重要的是,这三种正则化方法生成不同形状的决策函数。L1 正则化倾向于生成凹凸不平的线,L2 正则化倾向于球状的线,树正则化倾向于生成坐标对齐的决策函数。这为决策树的工作方式提供了更多的直觉理解。
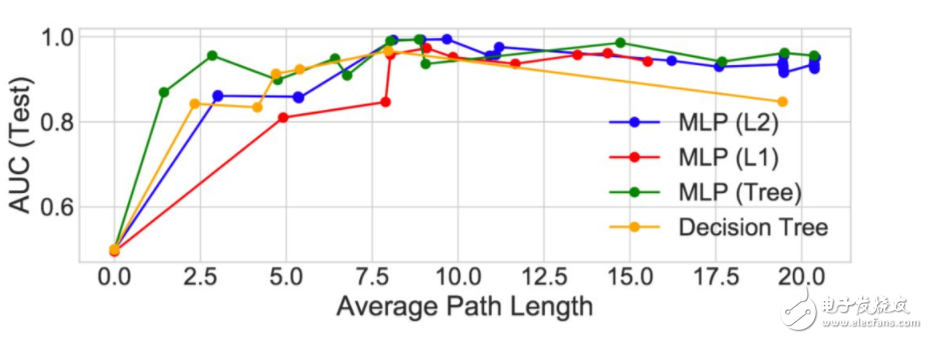
图 8:正则化模型的 APL 性能对比。这里,决策树(黄线)是原始的决策树(没有 DNN)。我们注意到在 1.0 到 5.0 之间树正则化 MLP 的性能高于(以及复杂度低于)所有其它的模型。
至少在这个虚构示例中,树正则化在高度正则化区域(人类可模拟)能得到更好的性能。例如,树正则化结合λ=9500.0 只需要 3 个分支就可以获得类似抛物线的决策函数(有更高的 APL)。
真实数据集
现在我们对树正则化有了一个直观认识,下面就来看一下真实世界数据集(带有二分类结果),以及树正则化与 L1、L2 正则化的对比。以下是对数据集的简短描述:
Sepsis(Johnson et. al. 2016):超过 1.1 万败血症 ICU 病人的时序数据。我们在每个时间步可以获取 35 个生命体征的数据向量、标签结果(如含氧量或心率)和 5 个二分类结果的标签(即是否使用呼吸机或是否死亡)。
EuResist(Zazzi et. al. 2012):5 万 HIV 病人的时序数据。该结构非常类似于 Sepsis,不过它包括 40 个输入特征和 15 个输出特征。
TIMIT(Garofolo et. al. 1993):630 位英语说话人的录音,每个语句包括 60 个音素。我们专注于区分阻塞音(如 b、g)和非阻塞音。输入特征是连续声系数和导数。
我们对真实世界数据集进行虚拟数据集同样的操作,除了这次我们训练的是 GRU-RNN。我们再次用不同的正则化执行一系列实验,现在还利用针对 GRU 的不同隐藏单元大小进行实验。
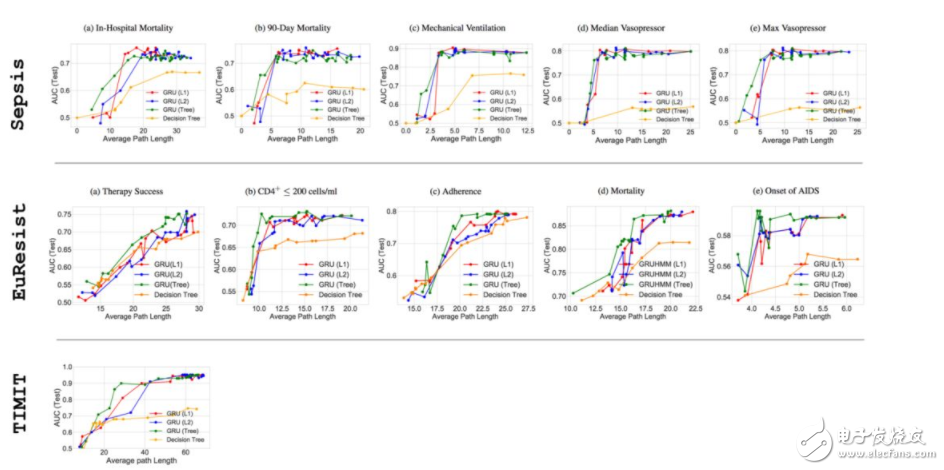
图 9:正则化模型在 Sepsis(5/5 输出维度)、EuResist (5/15 输出维度)和 TIMIT 的 APL 上的性能对比。可以看到在 APL 较小时,性能与图 8 类似,树正则化达到更高的性能。更多详细结果和讨论见论文 https://arxiv.org/pdf/1711.06178.pdf。
即使在带有噪声的真实世界数据集中,我们仍然可以看到树正则化在小型 APL 区域中优于 L1 和 L2 正则化。我们尤其关注这些低复杂度的「甜蜜点」(sweet spot),因为这就是深度学习模型模仿性所在,也是在医疗、法律等注重安全的环境中实际有用之处。
此外,我们已经训练了一个树正则化 DNN,还可以训练一个模仿性决策树查看最终的决策树是什么样子。这是一次很好的完整性检查,因为我们期望模仿性决策树具备模仿性,且与特定问题领域相关。
下图展示了针对 Sepsis 中 2 个输出维度的模仿性决策树。由于我们不是医生,因此我们请一位败血症治疗专家检查这些树。
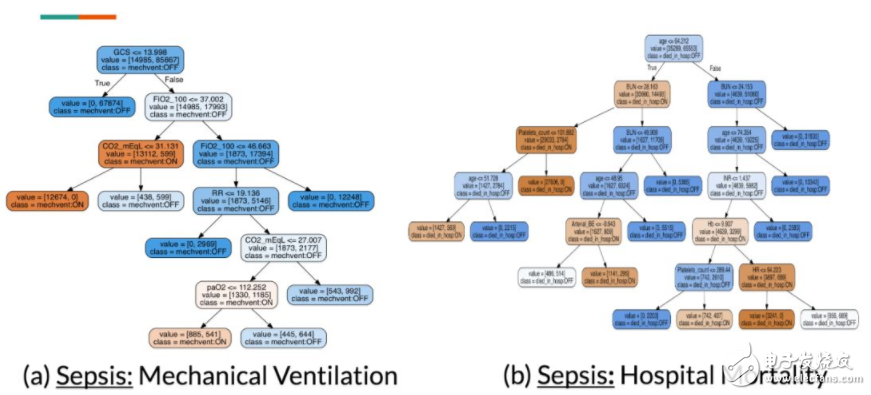
图 10:构建决策树以仿真已训练的树正则化 DNN(包含 Sepsis 的 5 个维度中的两个)。从视觉上,我们可以确认这些树的 APL 值较小,并且是可模仿的。
考虑 mechanical ventilation 决策树,临床医生注意到树节点上的特征(FiO2、RR、CO2 和 paO2)以及中断点上的值是医学上有效的,这些特征都是测量呼吸质量的。
对于 hospital mortality 决策树,他注意到该决策树上的一些明显的矛盾:有些无器官衰竭的年轻病人被预测为高死亡率,而其他的有器官衰竭的年轻病人却被预测为低死亡率。然后临床医生开始思考,未捕获的(潜在的)变量如何影响决策树过程。而这种思考过程不可能通过对深度模型的简单敏感度分析而进行。
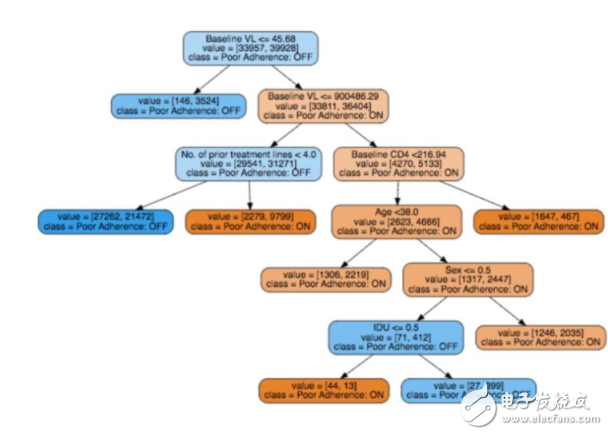
图 11:和图 10 相同,但是是从 EuResist 数据集的其中一个输出维度(服药坚持性)。
为了把事情做到底,我们可以看看一个尝试解释病人不能服从 HIV 药物处方(EuResist)的原因的决策树。我们再次咨询了临床医生,他确认出,基础病毒量(baseline viral load)和事先治疗线(prior treatment line)是决策树中的重要属性,是有用的决策变量。多项研究(Langford, Ananworanich, and Cooper 2007, Socas et. al. 2011)表明高基线的病毒量会导致更快的病情恶化,因此需要多种药物鸡尾酒疗法,太多的处方使得病人更难遵从医嘱。
可解释性优先
本文的重点是一种鼓励复杂模型在不牺牲太多预测性能的前提下,逼近人类模仿性功能的技术。我认为这种可解释性非常强大,可以允许领域专家理解和近似计算黑箱模型正在做的事情。
AI 安全逐渐成为主流。很多会议如 NIPS 开始更多关注现代机器学习中的公平性、可解释性等重要问题。之前我们认真地将深度学习应用于消费者产品和服务(自动驾驶汽车),我们确实需要更好地了解这些模型的工作原理。这意味着我们需要开发更多可解释性示例(人类专家参与其中)。
Notes:本文将会出现在 AAAI 2018 上(Beyond Sparsity: Tree Regularization of Deep Models for Interpretability),预印版可在 arXiv 上找到:https://arxiv.org/abs/1711.06178。类似的版本已经在 NIP 2017 上进行了 oral 解读。
问答
代理 MLP 追踪 APL 表现如何?
让人吃惊地好。在所有实验中,我们使用带有 25 个隐藏节点的单层 MLP(这是相当小的一个网络)。这必须有一个预测 APL 权重的低维表征。
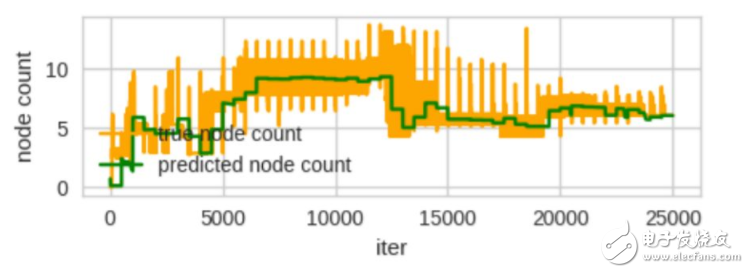
图 12:真节点计数指的是真正训练决策树并计算 APL。已预测的节点计数指的是代理 MLP 的输出。
与原决策树相比,树正则化模型的表现如何?
上述的每个对比图展示了与正则 DNN 对比的决策树 AUCs。为了生成这些线,我们在不同决策树超参数(即定义叶、基尼系数等的最小样本数)上进行了网格搜索。我们注意到在所有案例中,DT 表现要比所有正则化方法更差。这表明树正则化不能只复制 DT。
文献中有与此相似的吗?
除了在文章开头提及的相关工作,模型提取/压缩很可能是最相似的子领域。其主要思想是训练一个更小模型以模拟一个更深网络。这里,我们主要在优化中使用 DT 执行提取。
树正则化的运行时间如何?
让我们看一下 TIMIT 数据集(最大的数据集)。L2 正则化 GRU 每 epoch 用时 2116 秒。带有 10 个状态的树正则化 GRU 每个 epoch 用时 3977 秒,这其中包含训练代理的时间。实际上,我们做的非常谨慎。例如,如果我们每 25 个 epoch 做一次,我们将获得 2191 秒的一个平均的每 epoch 的成本。
在多个运行中,(最后的)模拟 DT 稳定吗?
如果树正则化强大(高λ),最终的 DT 在不同运行中是稳定的(顶多在一些节点上不同)。
DT 对深度模型的预测有多准确?
换言之,这一问题是在问如果训练期间 DT 的预测与 DNN 预测是否密切匹配。如果没有,那么我们无法有效地真正正则化我们的模型。但是我们并不希望匹配很精确。
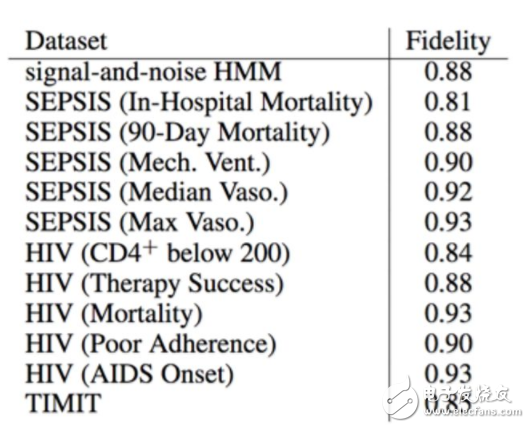
在上表中,我们测量了保真度(Craven and Shavlik 1996),这是 DT 预测与 DNN 一致的测试实例的百分比。因此 DT 是准确的。
残差 GRU-HMM 模型
(本节讨论一个专为可解释性设计的新模型。)
隐马尔可夫模型(HMM)就像随机 RNN,它建模潜在变量序列 [z1,…,zT],其中每个潜在变量是 K 离散状态之一: z_t∈1,?,K。状态序列通常用于生成数据 x_t,并在每个时间步上输出观察到的 y_t。值得注意的是,它包含转化矩阵 A,其中 A_ij=Pr(z_t=i|z_t?1=j),以及一些产生数据的发射参数。HMMs 通常被认为是一个更可阐释的模型,因为聚类数据的 K 潜在变量通常在语义上是有意义的。
当使用 HMM 潜在状态(换言之,当 HMM 捕获数据不足时,只使用 GRU)预测二值目标之时,我们把 GRU-HMM 定义为一个可以建模残差误差的 GRU。根据残差模型的性质,我们可以使用树正则化只惩罚 GRU 输出节点的复杂性,从而使得 HMM 不受限制。
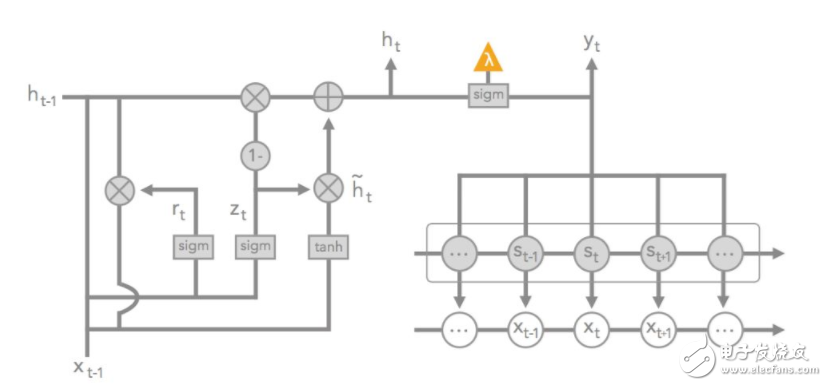
图 13:GRU-HMM 图解。x_t 表征时间步 t 上的输入数据。s_t 表征时间步 t 的潜在状态;r_t,h_t,h_t tilde,z_t 表征 GRU 的变量。最后的 sigmoid(紧挨着橘色三角形)投射在 HMM 状态和 GRU 潜在状态的总和之上。橘色三角形表示用于树正则化的替代训练的输出。
总体而言,深度残差模型比带有大体相同参数的 GRU-only 模型的表现要好 1%。参见论文附录获得更多信息。
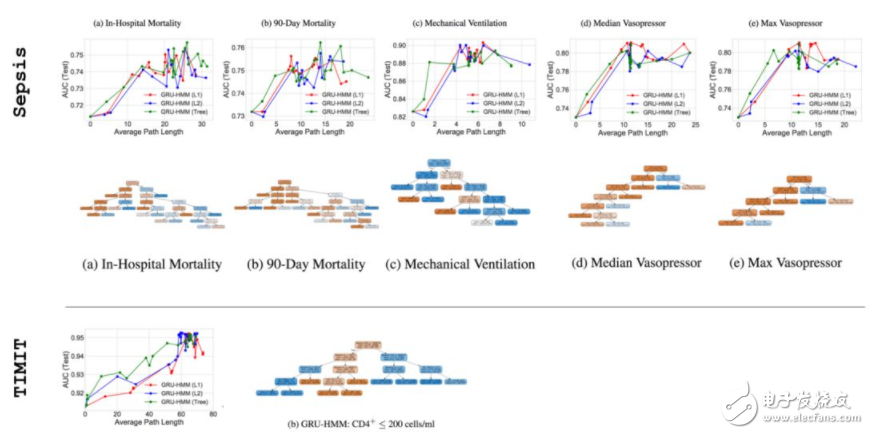
图 14:就像从前,我们可以为这些残差模型绘图并可视化模拟 DT。尽管我们看到相似的「sweet spot」行为,我们注意到最后得到的树有清晰的结构,这表明 GRU 在这一残差设置中表现不同。
-
机器学习模型可解释性的结果分析2023-09-28 1848
-
什么是“可解释的”? 可解释性AI不能解释什么2020-05-31 9384
-
机器学习模型的“可解释性”的概念及其重要意义2018-07-24 20902
-
结合深度神经网络和决策树的完美方案2018-07-25 11093
-
深度神经决策树:深度神经网络和树模型结合的新模型2018-08-19 13578
-
神经网络可解释性研究的重要性日益凸显2019-06-27 6193
-
深度理解神经网络黑盒子:可验证性和可解释性2019-08-15 14434
-
深度神经网络的实现机理与决策逻辑难以理解2020-03-27 3874
-
详谈机器学习的决策树模型2020-07-06 4601
-
什么是决策树模型,决策树模型的绘制方法2021-02-18 14248
-
综述深度神经网络的解释方法及发展趋势2021-03-21 1585
-
GNN解释技术的总结和分析与图神经网络的解释性综述2021-03-27 7379
-
图神经网络的解释性综述2021-04-09 3562
-
机器学习模型的可解释性算法详解2022-02-16 6446
-
可以提高机器学习模型的可解释性技术2023-02-08 2436
全部0条评论

快来发表一下你的评论吧 !
