

云计算平台是什么_云计算平台的搭建_云计算平台的功能
云通信与安全
描述
一、什么是云计算平台
云计算平台也称为云平台。云计算平台可以划分为3类:以数据存储为主的存储型云平台,以数据处理为主的计算型云平台以及计算和数据存储处理兼顾的综合云计算平台。
二、云计算平台服务特征
(1)服务无处不在--用户只需要一台具备基本计算能力的计算设备以及一个有效的互联网连接,就可以随时随地使用该服务。从这个意义来讲,任何联网的应用,都具备成为云计算平台的潜力。
(2)具备进入成本--用户具备使用该服务的需求,但是并不具备独立提供该服务的经济或者技术条件。譬如说某些企业需要定期地进行大规模的运算,但是并不值得专门为此购置一台具备大规模运算能力的计算设备。超算中心通过发展客户群让多个用户来分担超级计算机的成本,使得其用户能够在不拥有计算设备的情况下以较小的成本完成计算任务。
(3)用户决定应用--云计算平台提供计算能力(包括处理器、内存、存储、网络接口),但是并不关心用户的应用类型。用户利用云计算平台所提供的计算能力,并且充分考虑云计算平台所设定的(技术和经济)限制,开发出丰富多彩的应用。满足如上几个条件的云计算平台,又可以按照其所提供服务之层次细分为基础设施服务(IaaS,例如在线存储和数据库服务)、平台即服务(PaaS,例如AMP虚拟主机和JavaEE应用服务器容器)和软件即服务(SaaS,例如GoogleDocs)。很多厂商在提到云计算的时候,往往会同时提到分布式计算(DistributedComputing)、并行计算(ParalleComputing)、网格计算(GridComputing)、实用计算(UtilityComputing)等等概念。事实上用户并不关心这些五花八门的新名词,他们所关心的仅仅是某项服务是否可用以及使用该服务所需要的成本。说得难听点,这些概念仅仅是云计算平台提供商在创建云计算平台时才需要了解的技术细节,它们可以被认为是云计算的表象,但并不是云计算的本质。
三、云计算平台的功能
云计算平台使企业可以更有效地利用其IT硬件和软件投资。企业可以通过该基础结构打破相互隔离的系统中固有的物理障碍,对系统群的管理犹如对单个实体那样自动进行。对于提供信息服务、降低IT管理复杂性、促进创新、以及通过实时工作负载均衡来提高响应能力而言,云计算平台都是最好的选择。
下面我们通过几个场景来看看使用云计算平台之后的情况:
1)当你需要使用服务资源的时候:
用户可以通过一个简单的Web界面联机提交使用服务资源的申请。他们可以为自己的项目指定期望的开始日期和结束日期。数据中心管理员可以批准或拒绝这个申请。批准后自动化服务管理平台就会从可用的资源池中选择适合的服务器、存储、操作系统和软件等资源,并且根据所申请的资源配置要求对这些资源进行部署。用户只需在等待很短的时间后就会收到平台自动发送的信息,告知用户所需求的资源已经部署完毕,可以使用。
2)当服务资源出现紧张的时候:
虚拟世界需要大量的计算能力,当虚拟空间扩大或登录用户增多时尤其如此。大型多人在线网络游戏(MMPOG)就是超大型虚拟世界的典范。一些商业化虚拟世界拥有多达几百万的注册用户,并且由数千台服务器提供支持。
托管虚拟世界的企业可以通过自动化服务管理平台中的实时监控器,显示当前基础结构的使用情况,或者显示虚拟世界的任何指定“区域”中客户的平均响应时间。该企业发现A区域的用户数量大幅增加,导致资源使用增加,响应时间正在减缓,而此时X区域和Y区域的用户数量较少,负载较低。于是,该企业可以在自动化服务管理平台中通过手动的方式重新平衡资源,(当然我们也可以预先在平台中定义好资源平衡使用的策略,这样在发生资源使用紧张的时候,管理平台就可以按照定义好的策略自动触发相应的操作)分别从X区域和Y区域分别撤出5台服务器,并将这10台服务器提供给A区域使用,用来缓解负载。几分钟后,这10台服务器重新分配完成,而这个过程没有对任何区域中的任何用户造成影响,A区域的响应时间也恢复到可接受的水平。该企业通过重新利用未充分使用的设备,极大地节省了成本,并保持了较高的客户满意度、避免了用户需要呼叫帮助中心来寻求帮助,并且在几分钟之内就完成了以前需要几天或几周时间来完成的工作。
用户对于云计算平台的主要需求包括:
云计算平台最好是一个基于Web的门户服务形式,用户可以很方便的登录并申请所需的资源。
平台应该可以通过自动或者半自动的方式发现数据中心中的可用资源并提供给用户选择使用。
平台应该可以得到流程引擎的支持,可以整合管理流程(例如ITIL),例如申请、批准、评审和审计等功能。
云计算平台的后端应该是一系列用来进行部署、监控、计费的系统,满足用户对于申请资源的要求。
自动化供应
用户通过基于角色的Web门户网站来实现自动化供应。用户在门户网站填写一张表单来定义其硬件平台、CPU、内存、存储、操作系统、中间件和团队成员及其相关角色等信息。整个过程大约需要5分钟。通过门户网站提交请求之后,数据中心管理员会得到通知,并登录以批准、修改和/或拒绝该请求。一旦批准,系统就会启动一个定义好的自动化工作流程来完成整个部署工作。完全自动化的供应流程符合安全要求,减少了人为原因造成的错误,大大缩短了系统部署的时间。
预订和调度
在提交服务申请时,需要用户了解资源使用的时间情况。因为在提交申请时需要用户填写服务的开始和结束时间,这样便于数据中心的管理人员对于资源使用情况有所了解。在服务到达结束时间时,系统会自动将资源收回,以便可以给其他需要资源的服务来使用。当然用户可以变更服务的结束时间,这也是管理平台的重要功能之一,我们将在下面的部分说明。
变更管理
在某些项目中可以能会面临开发延期或者新需求等有关的一些未知因素。这些未知因素有时会使遵守合同规定的结束日期变得困难,当结束日期在项目延期之前几个月便得到确认时,这种情况尤其明显。因此,系统允许用户请求延长其原定的合同结束日期。
经过授权的项目成员可以登录到平台门户网站,请求延长合同结束日期。数据中心管理员从资源能力和业务合理性两方面对该请求进行评估。管理员可以登录到Web界面来查看该请求,并进行审批操作。新的日期一经批准,将会执行相应的任务,也会对合同进行更新以反映新的结束日期。
更改合同
云计算平台还提供对于服务申请资源的变更功能。对于采用新技术或未经测试技术的高风险项目而言,经常需要变更服务器的操作系统、软件等资源。
云计算平台的合同变更功能非常灵活,用户可以在原有的系统中添加或删除软件组件或者连同操作系统完全重新部署。用户也可以向现有合同中添加服务器或者去除服务器,或者在符合要求的硬件系统上,也可以选择增加或减少分配给一个或多个虚拟机的资源数量。当变更申请提交后,整个系统的变更操作都是自动进行的,无需人工介入,系统可以在很短的时间内完成变更申请,提供给用户使用。
四、云计算平台搭建方法
目前开源的云计算平台的搭建都要依托Linux系统,因此我们有2种办法搭建云计算平台:安装Linux系统和在其他操作系统下安装Linux虚拟机后搭建云平台。目前主流的虚拟机有:
VirtualBox
Vmware
有了Linux系统环境后就能搭建云计算平台了,几大开源云平台系统有:
Hadoop系统
OpenStack
云计算平台的搭建=Linux系统+开源云平台+SSH框架。
五、云计算平台原理
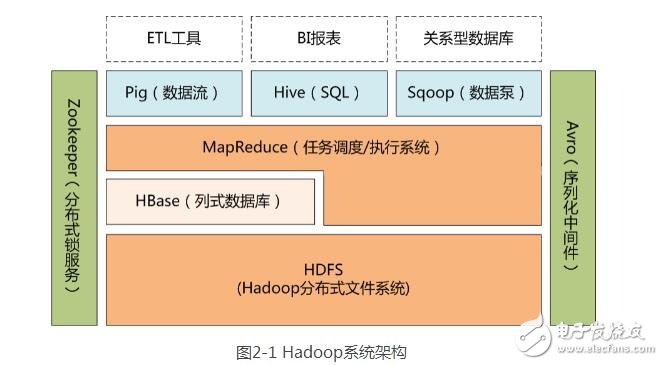
1.Hadoop系统原理
Hadoop是一个开源的可运行于大规模集群上的分布式并行编程框架,其最核心的设计包括:Map Reduce和HDFS。基于 Hadoop,你可以轻松地编写可处理海量数据的分布式并行程序,并将其运行于由成百上千个结点组成的大规模计算机集群上。
简单的说:Map Reduce框架的核心步骤主要分两部分:Map和Reduce。当你向Map Reduce框架提交一个计算作业时,它会首先把计算作业拆分成若干个Map任务,然后分配到不同的节点上去执行,每一个Map任务处理输入数据中的一部分,当Map任务完成后,它会生成一些中间文件,这些中间文件将会作为Reduce任务的输入数据。Reduce对数据做进一步处理之后,输出最终结果。
Map Reduce是Hadoop的核心技术之一,为分布式计算的程序设计提供了良好的编程接口,并且屏蔽了底层通信原理,使得程序员只需关心业务逻辑本事,就可轻易的编写出基于集群的分布式并行程序。从它名字上来看,大致可以看出个两个动词Map和Reduce,“Map(展开)”就是将一个任务分解成为多个子任务并行的执行,“Reduce”就是将分解后多任务处理的结果汇总起来,得出最后的分析结果并输出。
适合用 Map Reduce来处理的数据集(或任务)有一个基本要求:待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。
想要彻底了解Hadoop系统的原理是十分困难的,由于篇幅有限,知识水平也不高,我只能描写其大概面貌,本次课程设计的核心是学习搭建与运用云计算平台,没有足够的时间与精力去完全了解Hadoop的原理,在这里我们不妨就理解为:
Hadoop系统=HDFS分布式文件系统+Map Reduce运算机制。
这样就能很好的明白它们的大致关系,有助于对后面实验的理解。
2.Ubuntu系统
本次课程设计所使用的Linux系统是ubuntu14。
Ubuntu(乌班图)是一个以桌面应用为主的Linux操作系统,其名称来自非洲南部祖鲁语或豪萨语的“Ubuntu”一词,意思是“人性”、“我的存在是因为大家的存在”,是非洲传统的一种价值观,类似华人社会的“仁爱”思想。Ubuntu基于Debian发行版和GNOME桌面环境,而从11.04版起,Ubuntu发行版放弃了Gnome桌面环境,改为Unity,与Debian的不同在于它每6个月会发布一个新版本。Ubuntu的目标在于为一般用户提供一个最新的、同时又相当稳定的主要由自由软件构建而成的操作系统。
LTS 是 Ubuntu 的长期支持版,因此 Ubuntu 14.04 支持周期长达 3-5 年。因此 Ubuntu 14.04 是追求稳定的用户和企业的最佳选择。所以本次课程设计选择ubuntu14.04LTS版本完全能够应付云平台搭建与相关实验的任务。
六、云计算平台搭建过程
1.Ubuntu系统的安装
去Ubuntu官网下载好对应版本的系统镜像,并用虚拟光驱软件加载镜像,选择安装Ubuntu系统,一路点击继续后大约10来分钟就可以安装好Ubuntu系统了。
2.Hadopp系统部署
修改机器名:
打开/etc/hostname文件,将/etc/hostname文件中的Ubuntu改为你想取的机器名。这里我取“s15“。重启系统后才会生效。
安装ssh服务:
在terminal窗口中输入:Sudoaapt-getinstallopenssh-server
建立ssh无密码登录本机
在terminal窗口中输入:
ssh-keygen-tdsa-P‘’-f~/.ssh/id_dsa
cat~/.ssh/id_dsa.pub》》~/.ssh/authorized_keys
登录localhost:
在terminal窗口中输入:bin/start-all.sh
安装Hadoop:
下载Hadoop安装包并解压,打开Hadoop/conf/Hadoop.sh文件,配置conf/Hadoop.sh:找到#exportJAVA_HOME=。。。一行,去掉#,然后加上本机JDK的路径。
打开conf/core-site.XML文件,加入如下代码:
《configuration》
《property》
《name》fs.default.name《/name》
《value》hdfs://localhost:9000《/value》
《/property》
《/configuration》
打开conf/mapred-site.XML文件,编辑如下:
《configuration》
《property》
《name》mapred.job.tracker《/name》
《value》localhost:9001《/value》
《/property》
《/configuration》
打开conf/masters文件和conf/slaves文件,添加secondary的主机名,作为单机版环境,这里只需填写localhost就Ok了。
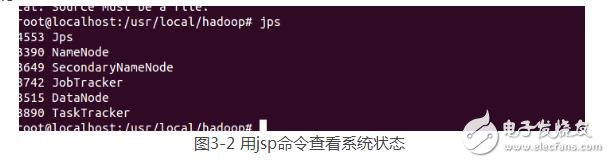
到这里Hadoop系统就部署完毕了。调用bin/start-all.sh命令即可以启动Hadoop,用JSP命令查看系统状态,出现如下信息说明系统部署成功:
- 相关推荐
- 热点推荐
- 云计算平台
-
什么是云计算平台?搭建云计算平台需要什么条件2025-01-09 1215
-
AI云平台与传统云计算的区别2024-10-14 1727
-
如何理解云计算?2024-08-16 2875
-
什么是云计算2023-04-21 2465
-
树莓派-搭建边缘计算云平台2022-12-03 2666
-
#硬声创作季 #云计算 云计算-1304.06 云平台部署-k8s部署01-2水管工 2022-10-11
-
云计算平台有哪些_几种云计算平台的介绍2017-12-28 47554
-
云计算平台在高校的开发及应用2017-10-20 1201
-
基于云计算平台搭建及应用部署2017-10-11 1035
-
什么是云计算?2017-08-09 5094
-
5款开源云计算平台的介绍2010-04-12 1647
-
什么是云计算 云计算的定义2009-11-18 3941
全部0条评论

快来发表一下你的评论吧 !
