

谷歌探讨了如果分类器不再仅限于微小的改变,最终输出会是什么结果
电子说
描述
深度学习系统很容易受到生成样本的攻击,对输入的参数进行细微的改变会导致网络输出变化,但人类肉眼却看不出什么差别。通常,这些对抗样本只对每个像素做少量调整,或者修改图像中少量像素。也就是说,大部分对抗样本都将重点放在对输入数据极小或不易察觉的改变上。
在这篇论文中,谷歌的研究人员探讨了如果分类器不再仅限于微小的改变,最终输出会是什么结果。他们构建了一个独立于图像的补丁,能让神经网络做出非常明显的反应。这个补丁可以放置在分类器视野内的任何地方,并让分类器输出一个目标类。因为这个补丁是独立于场景的,所以攻击样本无需提前了解光照条件、相机角度、分类器类型以及其他信息。
在VGG16上,用打印出的补丁对分类器进行攻击。分类器先将图片以97%的概率识别为“香蕉”;在下图添加补丁后,分类器以99%的概率将其识别为“烤面包机”
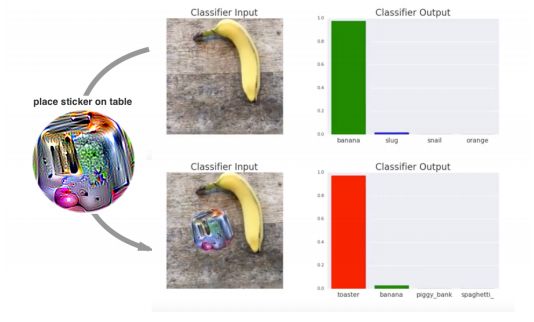
生成对抗补丁之后,补丁可以发布到网上供其他人打印或使用。此外,由于攻击会使用较大的扰动,目前的防御技术主要是针对较小扰动的,面对大扰动也许会不稳定。最近的研究表明,在MNIST上最先进的对抗训练模型仍然容易受到较大扰动的影响。
与以往不同,研究人员将补丁作为图像的一部分作为攻击,它可以变成任意形状,然后训练各种类型的图像,在每个图像上随机变换、缩放并旋转补丁,使用梯度下降进行优化。
假设图片x∈Rw×h×c,补丁为p,补丁位置l,补丁变换为t,将补丁应用操作器(patch application operator)定义为A(p,x,l,t)。

操作器输入一个补丁、一个图片、一个位置以及任何补丁的变换,然后进行训练,优化识别出正确类别的概率。
为了得到训练后的补丁P^,我们在目标函数上训练:
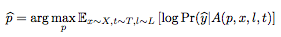
X表示正在训练的一套图像,T是经过变换的补丁分布,L是图像位置的分布。
研究人员认为这种攻击利用了图像分类任务的构建方式。虽然图像可能包含多个对象,但只有一个目标标签是正确的。所以网络必须学会检测每一帧最“明显”的项目。对抗补丁通过生成比现实世界中的物体更显著的输入来利用这一特征。因此,在目标检测或图像分割模型受到攻击时,我们希望烤面包机补丁能被分类为烤面包机,而不影响图像的其他部分。
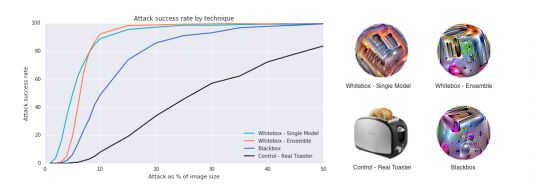
不同方法创造出对抗补丁的比较。成功率是将补丁放在图片顶部计算的。每张图片都经历了400张位置不同的补丁测试;同时又经历了400张不同大小补丁照片的测试
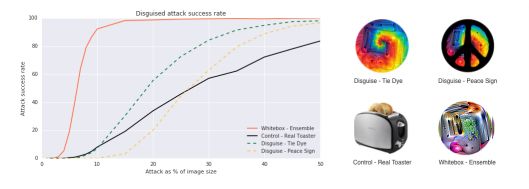
伪装成不同类别的补丁比较。研究人员发现他们可以改变补丁的样式,但仍然能骗过分类器
结果表明,这个通用、稳定、有针对性的补丁无论放在图片的哪个位置,都能成功骗过分类器,而且不需要提前了解场景信息。这些补丁还可以打印出来,在许多地方通用。
-
ADS805E数字输入信号最小要3.5V,这个仅限于时钟信号CLK还是同时包括了输出使能信号OE?2024-12-17 537
-
MCSPTR2AK396电机控制套件的编程是否仅限于最基本的 SVPWM 实现?2026-04-21 9420
-
是否仅限于在直通模式下使用2个vGPU?2018-10-08 4867
-
请问MAX125与DSP相连的所有信号线的电平都需要转换还是仅仅限于数据地址线?2019-04-04 1907
-
反射计怎么分类 ?2020-04-07 4516
-
充满传感器的世界将如何改变我们2020-04-27 2306
-
可以在Virtex-5的任何片中实现CFGLUT5原语,还是仅限于SLICE_M中的LUT?2020-05-28 3962
-
stm32芯片的选型与分类及GPIO口的分析2022-02-14 2173
-
阈值分类器组合的多标签分类算法2018-01-22 1265
-
新报告探讨了如何在VR和AR市场中使用OLED显示器2018-10-01 2554
-
谷歌正式发布其AR导航功能——但目前仅限于Pixel手机2019-05-13 3657
-
AMD表示在中国的合资企业的处理器将仅限于在第一代Zen架构 我国自主CPU何去何从2019-06-06 6071
-
Google的翻译功能将不再仅限于智能手机2020-07-28 2630
-
丰田与比亚迪合作仅限BEV领域,广汽丰田无DMI插混项目2024-05-11 1752
全部0条评论

快来发表一下你的评论吧 !
