

谈Kaggle机器学习之模型融合
人工智能
描述
本文以Kaggle的Titanic入门比赛来讲解stacking的应用(两层!)。
数据的行数:train.csv有890行,也就是890个人,test.csv有418行(418个人)。
而数据的列数就看你保留了多少个feature了,因人而异。我自己的train保留了 7+1(1是预测列)。
在网上为数不多的stacking内容里,相信你早看过了这张图:
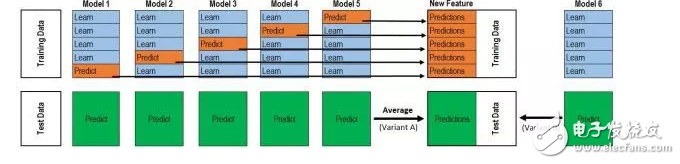
这张图,如果你能一下子就能看懂,那就OK。
如果一下子看不懂,就麻烦了,在接下来的一段时间内,你就会卧槽卧槽地持续懵逼。。.。。.
因为这张图极具‘误导性’。(注意!我没说这图是错的,尽管它就是错的!!!但是在网上为数不多教学里有张无码图就不错啦,感恩吧,我这个小弱鸡)。
我把图改了一下:
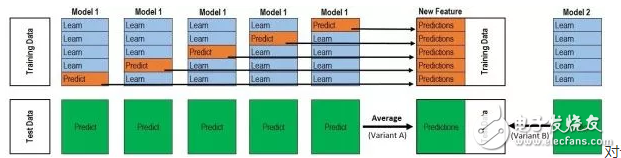
对于每一轮的 5-fold,Model 1都要做满5次的训练和预测。
Titanic :
Train Data有890行。(请对应图中的上层部分)
每1次的fold,都会生成 713行 小train, 178行 小test。我们用Model 1来训练 713行的小train,然后预测 178行 小test。预测的结果是长度为 178 的预测值。
这样的动作走5次! 长度为178 的预测值 X 5 = 890 预测值,刚好和Train data长度吻合。这个890预测值是Model 1产生的,我们先存着,因为,一会让它将是第二层模型的训练来源。
重点:这一步产生的预测值我们可以转成 890 X 1 (890 行,1列),记作 P1 (大写P)
接着说 Test Data 有 418 行。(请对应图中的下层部分,对对对,绿绿的那些框框)
每1次的fold,713行 小train训练出来的Model 1要去预测我们全部的Test Data(全部!因为Test Data没有加入5-fold,所以每次都是全部!)。此时,Model 1的预测结果是长度为418的预测值。
这样的动作走5次!我们可以得到一个 5 X 418 的预测值矩阵。然后我们根据行来就平均值,最后得到一个 1 X 418 的平均预测值。
重点:这一步产生的预测值我们可以转成 418 X 1 (418行,1列),记作 p1 (小写p)
走到这里,你的第一层的Model 1完成了它的使命。
第一层还会有其他Model的,比如Model 2,同样的走一遍, 我们有可以得到 890 X 1 (P2) 和 418 X 1 (p2) 列预测值。
这样吧,假设你第一层有3个模型,这样你就会得到:
来自5-fold的预测值矩阵 890 X 3,(P1,P2, P3) 和 来自Test Data预测值矩阵 418 X 3, (p1, p2, p3)。
到第二层
来自5-fold的预测值矩阵 890 X 3 作为你的Train Data,训练第二层的模型
来自Test Data预测值矩阵 418 X 3 就是你的Test Data,用训练好的模型来预测他们吧。
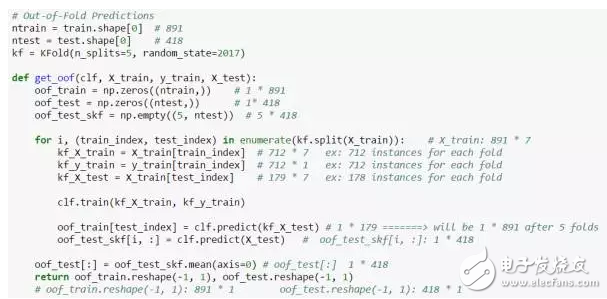
最后 ,放出一张Python的Code,在网上为数不多的stacking内容里, 这个几行的code你也早就看过了吧,我之前一直卡在这里,现在加上一点点注解,希望对你有帮助:
- 相关推荐
- 机器学习
-
机器学习模型之性能度量2020-05-12 0
-
超详细配置教程:用Windows电脑训练深度学习模型2022-11-08 1487
-
机器学习之偏差、方差,生成模型,判别模型,先验概率,后验概率2020-05-14 0
-
机器学习与软件平台的融合2021-01-28 0
-
深度融合模型的特点2021-07-16 0
-
什么是机器学习? 机器学习基础入门2022-06-21 0
-
部署基于嵌入的机器学习模型2022-11-02 0
-
机器学习之模型评估和优化2017-10-12 820
-
机器学习之朴素贝叶斯2018-05-29 891
-
自学机器学习的误区和陷阱2018-05-14 4779
-
Kaggle机器学习/数据科学现状调查2018-06-29 9841
-
如何从13个Kaggle比赛中挑选出的最好的Kaggle kernel2021-06-27 2001
-
如何评估机器学习模型的性能?机器学习的算法选择2023-04-04 1021
-
机器学习算法汇总 机器学习算法分类 机器学习算法模型2023-08-17 1098
-
机器学习模型评估指标2023-09-06 1106
全部0条评论

快来发表一下你的评论吧 !
