

基于 FPGA 客户端的分布式计算网络设计
FPGA/ASIC技术
描述
高校和私企正在应用分布式平台,而不是安装速度更快、耗电更大的超级计算机来解决日益复杂的科学算法,针对SETI@home 这样的项目,他们则使用数以千计的个人计算机来计算它们的数据。[1,2] 当前的分布式计算网络一般用CPU 或 GPU 来计算项目数据。
FPGA 也正被像 COPACOBANA这样的项目所采用,该项目使用 120个赛灵思 FPGA 通过暴力处理来破解DES 加密文件。[3] 不过在这个案例中,FPGA 都被集中布置在一个地方,这种方案不太适合那些预算紧张的大学或企业。目前并未将 FPGA 当作分布式计算工具,这是因为它们的使用需要借助 PC,才能用新的比特流不断地重新配置整个 FPGA。但是现在有了赛灵思部分重配置技术,为分布式计算网络设计基于 FPGA 的客户端完全可行。
我们汉堡应用技术大学的研究小组为这样的客户端创建了一个原型,并将其实现在单个 FPGA 上。我们的设计由静态和动态两大部分组成。其中静态部分在 FPGA 启动时加载,与此同时用静态部分实现的处理器从网络服务器下载动态部分。动态部分属部分重配置区域,提供共享的 FPGA资源。[4] 采用这种配置,FPGA 可以位于世界上的任何地方,用较低的预算就能够为计算项目提供强大的计算能力。
分布式 SOC 网络
由于具有信号并行处理能力,FPGA能够使用比微处理器慢 8 倍的时钟,低 8 倍的功耗实现比其快三倍的数据吞吐量。[5] 为利用该强大的计算能力实现高数据输入速率,设计人员一般将算法实现为流水线,比如 DES 加密。[3] 我们开发分布式 SoC 网络 (DSN)原型的目的是加快算法的速度和使用分布式 FPGA 资源处理大型数据集。我们的网络设计采用“客户端- 代理-服务器”架构,故我们可以将所有注册的片上系统 (SoC) 客户端分配给每一个网络参与方的计算项目(如图 1所示)。这在将每一个 SoC 客户端连接到唯一的项目的“客户端- 服务器”架构中是无法实现的。
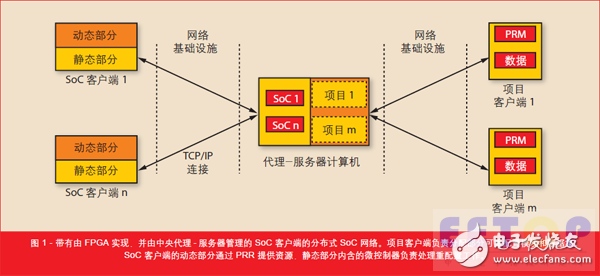
另外,我们选择“代理- 服务器”架构可以将每个 FPGA 的 TCP/IP 连接数量减少到一个。DSN FPGA 负责运算使用专用数据集的算法,而“代理-服务器”则负责管理 SoC 客户端和项目客户端。代理调度连接的 SoC 客户端,让每个项目在相同的时间几乎拥有相同的计算能力,或者在 SoC 的数量少于计算请求的项目时分时复用soc客户端。
项目客户端提供部分重配置模块(PRM) 和激励输入数据集。在连接到“代理- 服务器”之后,项目客户端将PRM 比特文件发送给服务器,然后由服务器将它们分配给带有空闲的部分可重配置区域 (PRR) 的 SoC 客户端。SoC 客户端的静态部分是一个基于MicroBlazeTM 的微控制器,用接收到的 PRM 动态重新配置 PRR。接下来,项目客户端开始通过“代理- 服务器”发送数据集并从 SoC 客户端接收计算的结果。根据项目客户端的需要,举例来说,它可以比较不同的计算结果,或根据计算目的评估计算结果。
MicroBlaze 处理器负责运行客户端软件,客户端软件管理部分重配置以及比特流和数据交换。
SOC 客户端
我们为随 ML605 评估板配套提供的赛灵思 Virtex®-6 FPGA(XC6VLX240T)开发了 SoC 客户端。MicroBlazeTM 处理器负责运行客户端软件,客户端软件负责管理部分可重配置以及比特流和数据交换(如图 2 所示)。用户逻辑封装PRR 的处理器本地总线 (PLB) 外设用以连接静态部分和动态部分。在动态部分驻留的是接收到的 PRM 提供的加速器 IP 核使用的 FPGA 共享资源。为存储接收到的数据和计算完成的数据,我们选择了 DDR3 存储器而非CompactFlash,因为 DDR 存储器有更高的数据吞吐量和无限制的写入访问次数。PRM 存储在专用数据段内,以控制其大小,避免与其它数据集发生冲突。该数据段大小为 10 MB,足以存储完整的 FPGA 配置。因此每一个PRM 都应该与这个数据段的大小匹配。
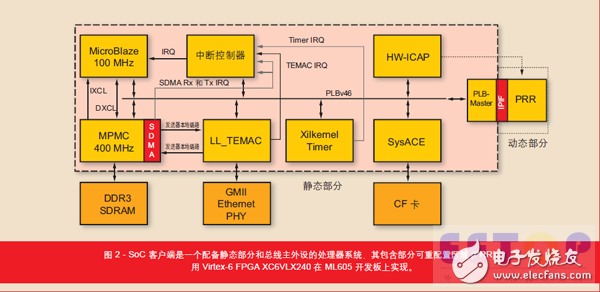
我们还为接收及结果数据集创建了不同的数据段。这些数据段的大小有 50 MB,能够为比如图像或加密文本文件等提供足够的寻址空间。管理这些数据段主要依靠 10 个管理结构。该管理结构包括每个数据集对的起始/ 终点地址,以及指示结果数据集的标志。
为将静态部分连接到 PRR,我们对赛灵思EDK 提供的 IP 连接进行评估,比如快速单向链路 (FSL)、PLB 从和PLB 主等。我们选择将PLB 主/ 从结合使用,以取得便于配置的 IP,可以在无需 MicroBlaze 提供支持的情况下发送和接收数据请求,从而大幅降低每个字传输占用的时钟周期。
对客户端- 服务器通信,FPGA 的内部以太网 IP 硬核是处理器系统静态部分不可或缺的外设。借助本地链路TEMAC 对存储器控制器的软件直接存储器访问 (SDMA) 功能,可减轻数据和比特文件传输带来的 PLB 载荷。在接收 1,518 个字节的帧后,SDMA生成中断请求,调用 lwip_read() 函数来处理这段数据。Lwip_write() 函数告知 SDMA 通过到 TEMAC 的发送通道执行 DMA 传输功能。
我们把 Xikernel(一种用于赛灵思嵌入式处理器的内核),当作 SoC客户端软件的底层实时操作系统加以实现,以便使用用于 TCP/IP 服务器连接的套接字模式发挥轻量级 TCP/IP 栈(LwIP) 库的作用。图 3 概述了客户端线程的初始化、建立、发送和处理顺序。SoC 客户端线程初始化到服务器的连接,并接收存储在 DDR3 存储器中的PRM 比特流(“pr”), 从而应用XILMFS 文件系统。随后Xps_hwicap(硬件内部配置接入点)用 PRM 重新配置 PRR。最后,由总线主外设设置一个状态位,命令 SoC 客户端向服务器发送请求。服务器用数据集(“dr”)做出响应, SoC 客户端把该数据集存储在板载存储器上。这些数据文件包含有内容顺序, 比如“output_length+“ol”+data_to_compute”。output_length 是字节长度,用来保留结果数据的存储范围,后接字符对“ol”。对首个接收到的“dr”消息,会生成一个计算线程和一个发送线程。
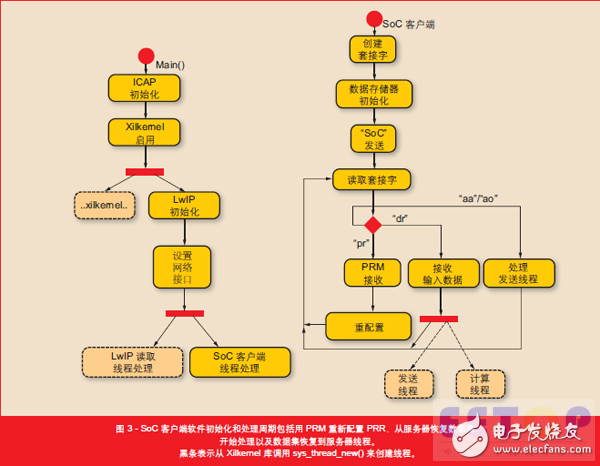
计算线程将输入- 结果数据集的地址发送到 PRR 外设的从接口,并启动PRM 的自动数据集处理功能。管理结构为每个数据集提供这些地址,并在确保结果数据完全可用后设置“完成”标志。在目前的客户端软件概念版本中,计算线程和发送线程通过该结构通信,由发送线程反复检查完成位, 并将lwip_write() 调用存储在存储器中的结果。
在测试 SoC 客户端时,我们发现如果在 PRR 重配置过程中启用全部中断,Xilkernel 的定时器会产生调度函数访问 MicroBlaze,使重配置过程随机发生卡住的状况。如果禁用全部中断,或在没有 Xilkernel 的支持下,对SoC 客户端的 MicroBlaze 处理器使用独立的软件模块,就不会发生这种情况。
配备例化PRM 的总线主控外设
为在 PRM 和外部存储器之间实现自控激励数据和结果的交换,我们将总线主外设构建为一个带数据路径和控制路径的处理器元件(如图 4 所示)。在数据路径中,我们在两个深度均为16 个字的 FIFO 模块之间嵌入 PRM接口,以补偿通信和数据传输延迟。数据路径的两个 FIFO 均直接连接到PLB 的总线主接口。这样,我们通过有限状态机 (FSM) 的直接数据传输,大幅降低时间。由于不采用软件,所以 MicroBlaze 的寄存器文件中不发生中间数据存储。本 RISC 处理器的“加载- 存储”架构一直需要占用两个总线传输周期,用于从某个地址加载 CPU 寄存器,然后将寄存器的内容存储到另一个 PLB 连接的设备。由于从 MicroBlaze 到存储器控制器的DXCL 数据高速缓存链路构成 PLB 的旁路,因此这些“加载- 存储”周期在时序上不能得到改善。这是因为接收到的数据和发送的计算结果都是逐字一次性处理,没有发挥高速缓存的作用。由此 PRR 外设的活动与 MicroBlaze 主软件的处理脱钩,因而 PRR 数据传输不会导致更多的 Xilkernel 环境切换。但仍然不可避免地出现两个主设备竞争总线访问的情况。
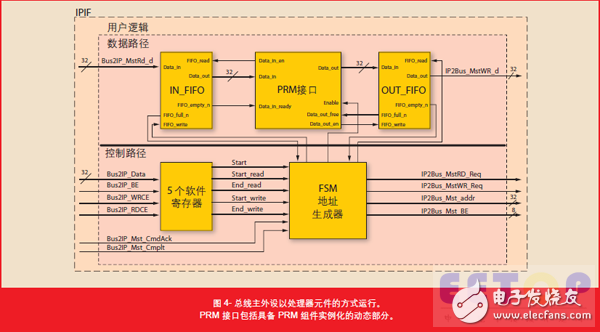
外设的从接口含有四个基于软件驱动的寄存器,可为控制路径提供输入和输出数据集的起始地址和终点地址。另一个软件寄存器为 FSM 设定“起始”位,用于初始化主数据传输周期。完整的数据处理周期的状态经第五个软件寄存器的地址提供给客户端软件。
根据控制路径的 FSM 的状态图可以看出,应该采取让到 PLB 的写入周期优先的策略(图5)。从 OUT_FIFO 提取数据优先于向 IN_FIFO 写入数据,防止 OUT_FIFO 为满时,阻止 PRM 处理算法。读取或写入外部存储器可交替进行,因为每次只能使用一种总线访问方式。当来自客户端的计算线程的软件复位启动 FSM(图 3)时,第一件事就是从外部存储器读取(状态 READ_REQ)。自此,总线主设备就受状态 STARTED 提供的转换条件所提供的决策逻辑的控制(表 1)。
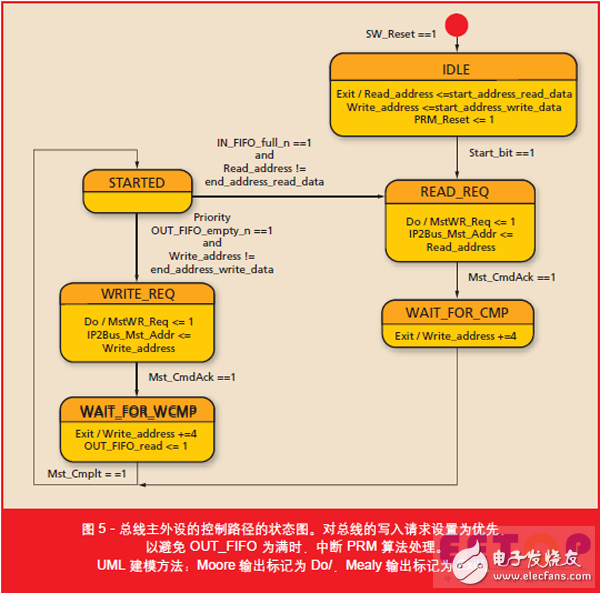

Mealy FSM 输出(标记Exit/)让地址计数器在总线传输完成时递增。这里两个计数器都直接导入到 FSM代码中。一般情况下我们倾向于将定时器和地址计数器分开实现为仅用FSM 输出使能的单独时钟进程,以便让计数器的保持小规模的转换逻辑以及尽量避免将多路复用器输入用于计数器状态反馈。对于此点,XST 综合编译器的结果将 RTL 原理图清楚地体现为并行于可加载计数器的 FSM 抽象,其中的时钟使能输入由预期状态解码逻辑驱动。尽管行为级的 VHDL编码方式更容易让人理解,使用 FPGA资源和简单原语也不会影响功能。
用 PLANAHEAD 设置动态部分
FPGA 中静态和动态部分的配置这一设计流程是一个复杂的开发过程,需要用 PlanAheadTM 物理设计约束工具进行多步操作。第一步就是给在ML505 开发板上实现的由 PetaLinux驱动的动态重配置平台编写设计流程脚本。[6] 就当前迭代而言,将 PRR直接集成到外设的用户逻辑中的设计步骤与过去通过添加总线宏和器件控制寄存器(DCR) 用作 PRM 的 PLB接口、添加 PLB-DCR 桥接器实现总线宏的做法相比更实际。
下面的代码摘自 PlanAhead 项目的 UCF 文件,说明我们如何使用AREA_GROUP 约束确定动态部分的大小和位置:


内部的部分重配置区域的命名方法通过为其指定实例名 PRR,并将实例名相连(prm_interface.vhd)。对我们希望囊括在所需的 PRR 中的全部 FPGA 资源而言,我们用设置左下方坐标和右上方坐标的方法来划定一个矩形区域。
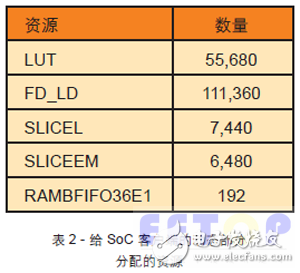
这种特殊的方法只能覆盖 Slice和 BRAM,因为可用的 DSP 元件属于专用时钟区域,归多端口存储器控制器 (MPMC) 设计使用(表 2)。
为避免 ISE® 生成的 PRM 网表使用专属资源,我们将综合选项设置为:dsp_utilization_ratio = 0;use_dsp48 = false;iobuf = false。最后,从 FPGA 编辑器观察到静态部分的布局完全与 PRR 分开,PRR 在本例中占用的资源极少(图 6)。
配备图像处理 PRM 的 SOC 客户端
我们使用在 PRM 中实现的 Sobel/ 中值过滤器验证 SoC 客户端的运算能力及其 TCP/IP 服务器通信功能(图7)。我们使用赛灵思系统生成器(System Generator)开发图像处理邻域运算。赛灵思系统生成器让我们享有 Simulink® 仿真和自动 RTL 代码生成的便利。解串器将输入的像素流转换成 3x3 像素阵列,然后依次排列成一个覆盖整个图像的掩膜,为滤波器的并行乘积加总提供输入,或为后续的中值过滤器比较提供输入。[7] 过滤器的输入和输出像素向量的宽度为 4 位,故我们插入一个 PRM 封装器,以多路复用同步 FIFO 提供的 32 位输入向量的 8个四位元。使用MATLAB® 脚本,我们将 800 x 600 PNG 图像转换为四位灰度像素,用作 PRM 的输入激励。在过滤器的输出端,8 个四位寄存器顺序写入和级联,将字传输给 OUTFIFO(图 4)。
表 3 是 SoC 客户端三个运算步骤(接收 PRM 比特文件、重配置PRR、图像处理序列)的时序测量结果。我们用数字示波器在XGpio_WriteReg() 调用触发的 GPIO 输出处测量第一次到最后一次数据传输周期,采集接收与图像处理周期。
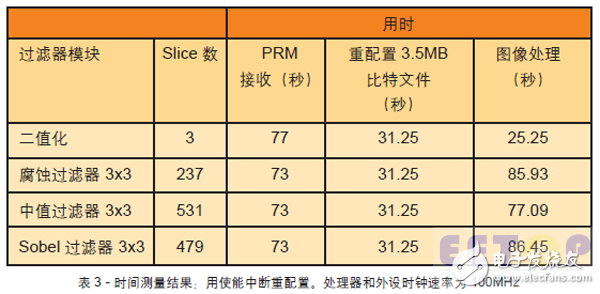
重配置时间间隔都是一样的,因为没有 Xilkernel 调度事件干扰基于软件的 HWICAP 操作。受 FSM 控制的HWICAP 操作在没有 MicroBlaze 互动的情况下,可以超过 112 KBps 的重配置速度实现更短的用时,甚至在启用中断的情况下也不例外。
在从代理向 SoC 客户端发送PRM 的过程中,连接很快中断。因为每传输 100 个字节仅 1 毫秒的延迟,SoC 客户端的通信非常畅通。由于与图像处理周期同步,正常的 Xilkernel线程导致 PLB 访问竞争,因此 SoC客户端在典型状态下运行。二值化序列的用时为 600 x 800/100MHz=4.8毫秒,因为只需要进行一次比较。这个序列嵌套在两次经 PLB 的图像传输中,根据功能性总线仿真的结果,每个字至少需要使用五个时钟周期,故:2 x 5 x 600 x 800/(8 x100MHz)=6 毫秒。由于所有测量的数据传输值都大于我们先前的预估值,我们需要对由总线读取、FIFO 写入和清空、图像处理流水线和总线写入组成的完整时序链条的构成进行详细分析。
部分重配置的力量
在运算复杂算法时,发挥分布式计算网络的力量是理想的选择。这些网络的流行设计目前仅限于使用 CPU 和GPU。我们的基于 FPGA 的分布式SoC 网络架构原型运用 FPGA 的并行信号处理特性来计算复杂算法。
赛灵思部分重配置技术是运用分布在世界各地的 FPGA 共享资源的关键。在我们的架构中,SoC 客户端的静态部分用更新的加速器以自控方式对 FPGA 的动态部分进行重配置。我们必须改进 SoC 客户端,使之能够使用使能中断运行 HWICAP,以实现完全的反应能力。这个方向的第一步是实现 FSM 控制的重配置,不给处理器带来负担。不过我们还需要分析PLB 传输影响以及 MPMC 瓶颈问题。
为管理 SoC 客户端, 使用与LwIP 链接的 Xilkernel 确保重配置驱动程序、动态部分的总线接口及其它应用的线程保持同步。我们进一步重点分析客户端- 服务器系统的时序和动态部分的处理周期,以期发现有更高数据吞吐量和可靠通信能力的软件/RTL 模型配置。
我们的 SoC 客户端的下一阶段的设计必须考虑 AXI4 总线功能。一般来说 PRM 交换可视为与一组软件任务共同执行的额外硬件任务。最后且同样重要的是,我们仍然在优化服务器的软件设计,以期达到更高的客户满意度。
- 相关推荐
- 热点推荐
- F
-
使用VirtualLab Fusion中分布式计算的AR波导测试图像模拟2025-04-10 490
-
VirtualLab Fusion应用:基于分布式计算的AR光波导中测试图像的仿真2025-02-19 527
-
基于分布式计算的AR光波导中测试图像的仿真2024-08-07 5480
-
HarmonyOS开发实例:【分布式新闻客户端】2024-04-17 1691
-
什么是分布式节点2023-08-28 6676
-
Hello HarmonyOS学习笔记:分布式新闻客户端实战(JS、eTS)2022-06-23 3691
-
HDC2021技术分论坛:跨端分布式计算技术初探2021-11-15 2467
-
怎样去设计嵌入式LWIP网络客户端2021-08-06 1772
-
如何利用FPGA设计无线分布式采集系统?2019-10-14 2508
-
什么是分布式计算机网络2010-04-06 5258
-
基于Java的分布式缓存优化在网络管理系统中的应用2009-09-19 2873
-
新型分布式网络管理方案的设计与实现2009-08-27 547
-
智能客户端应用程序的安全性研究与应用2009-08-14 479
-
分布式软件系统2009-07-22 5425
全部0条评论

快来发表一下你的评论吧 !
