

深度伪造人脸检测项目
描述
各位 AI 爱好者们,准备好通过各种 AI 技术来应对一个迫切需要被解决的全球问题了吗?MathWorks 诚邀您参加 2025 IEEE Signal Processing Cup 挑战赛:“野外深度伪造人脸检测”(DFWild-Cup)。
为什么挑战深度伪造?
随着合成数据生成的兴起,深度伪造已成为一个重大威胁——它能够操纵公众舆论,甚至导致身份盗窃。在这个挑战赛中,您可以运用在现实世界场景中获得的多样化的数据,来设计与实现算法,以识别面部图像的真实性。
参加挑战有什么好处?
您不仅有机会应用 AI 技术处理一个亟待解决的全球问题,还能有机会在 IEEE ICASSP 2025——全球最大的信号处理技术学术会议上展示您的作品以赢取 5000 美元的大奖!
您准备好了吗?
开始设置环境并启动深度伪造检测项目吧!您可以点击阅读原文,在打开网页的右下方,点击 “Download Live Script” 来获取这个项目的 MATLAB 入门代码。
如果您所在的学校没有MATLAB 全校使用授权,您可以访问 MathWorks 的 IEEE Signal Processing Cup 网站 ,申请免费的MATLAB竞赛软件许可并获取其他相关学习资源。您也可以访问MATLAB Academy 学习多门免费自定义进度的在线入门课程。
目录
第一步:加载数据
第二步:创建 Image Datastores
第三步:加载或创建网络
第四步:准备训练数据
第五步:训练神经网络
第六步:测试神经网络
第七步:创建提交
总结
第一步:加载数据
注册您的团队,然后获取下载训练和验证数据集的说明。将这些压缩文件存放在当前目录下名为 datasetArchives 的子文件夹中。

下面的代码将帮您自动解压这些文件,并将数据集整理到“real”和“fake”类别中:
datasetArchives = fullfile(pwd,"datasetArchives"); datasetsFolder = fullfile(pwd,"datasets"); if ~exist(datasetsFolder,'dir') mkdir(datasetsFolder); untar(fullfile(datasetArchives,"train_fake.tar"),fullfile(datasetsFolder,"train")); untar(fullfile(datasetArchives,"train_real.tar"),fullfile(datasetsFolder,"train")); untar(fullfile(datasetArchives,"valid_fake.tar"),fullfile(datasetsFolder,"valid")); untar(fullfile(datasetArchives,"valid_real.tar"),fullfile(datasetsFolder,"valid")); end
第二步:创建 Image Datastores
想要高效地处理包含大量图像的数据集,创建 Image Datastore 是必不可少的。这种数据格式允许我们存储大量的图像数据,包括那些超出内存容量的,并在神经网络训练期间高效地批次读取图像。
以下是为训练和验证数据集分别创建 Image Datastore 的方法。您需要在函数 imageDatastore 中指定其所需要包含图像的文件夹,并指明子文件夹名称对应于图像的标签,然后可以利用 shuffle 函数对图像进行随机排序的处理。
trainImdsFolder = fullfile(datasetsFolder,'train');
validImdsFolder = fullfile(datasetsFolder,'valid');
imdsTrain = shuffle(imageDatastore(trainImdsFolder, ...
IncludeSubfolders=true, ...
LabelSource="foldernames"));
imdsValid = shuffle(imageDatastore(validImdsFolder, ...
IncludeSubfolders=true, ...
LabelSource="foldernames"));
通过检查 Image Datastore 中所包含文件的大小,您可以看到这个挑战赛的训练数据集包含 26,2160 张图像,而验证数据集只包含 3072 张图像。由于目前我们还没有获得用于评估性能的测试数据集,可以使用 splitEachLabel 函数将训练数据集划分为两个新的 Image Datastore,如:10% 用于训练、2% 用于测试。
[imdsTrain,imdsTest] = splitEachLabel(imdsTrain,0.1,0.02,"randomized")
现在您可以获取数据集标签的类别名称和数量,然后按如下方式查看一些面部图像数据。
classNames = categories(imdsTrain.Labels); numClasses = numel(classNames); numImages = numel(imdsTrain.Labels); idx = randperm(numImages,16); I = imtile(imdsTrain,Frames=idx); figure imshow(I)
第三步:加载或创建网络
现在,训练、验证和测试数据集的 Image Datastore 都已经准备好了!下一步是加载一个预训练好的网络或创建一个新网络模型。
如果您是深度学习的新手,可以使用像 ResNet 或 VGG 这样的预训练网络来节省时间并提高性能。MATLAB 提供了一些预训练模型,可以作为起点。以下是加载预训练网络的简单方法:我们使用函数 imagePretrainedNetwork 来加载一个具有指定标签类别数量的预训练好的 ResNet-50 神经网络作为示例。请注意,在运行代码之前,您需要在 MATLAB 的 “Add-Ons” 下,搜索、下载并安装名为 “Deep Learning Toolbox Model for ResNet-50 Network” 的插件。
net = imagePretrainedNetwork("resnet50",NumClasses=numClasses);
如果您更倾向于创建自己的网络模型,MATLAB 的 Deep Network Designer 应用程序【https://www.mathworks.com/help/deeplearning/ug/build-networks-with-deep-network-designer.html】是一个可以用来设计和可视化深度学习网络模型的好工具。您还可以使用Deep Network Designer 导入 PyTorch 模型 【https://ww2.mathworks.cn/help/releases/R2024b/deeplearning/ug/import-pytorch-model-using-deep-network-designer.html】。
第四步:准备训练数据
准备数主要包括调整图像大小以匹配神经网络的输入尺寸,并通过数据增强来提高模型的鲁棒性。数据增强技术,如旋转、缩放和翻转,可以使模型更具泛化能力。MATLAB 提供了便捷的内置函数,如 imageDataAugmenter 和 augmentedImageDatastore。
这里我们采用的增强操作包括:随机沿垂直轴翻转训练图像,以及在训练图像上随机进行最多 30 像素的水平和垂直平移。
inputSize = net.Layers(1).InputSize;
pixelRange = [-30 30];
imageAugmenter = imageDataAugmenter( ...
RandYReflection=true, ...
RandXTranslation=pixelRange, ...
RandYTranslation=pixelRange);
augimdsTrain = augmentedImageDatastore(inputSize(1:2),imdsTrain, ...
DataAugmentation=imageAugmenter);
您需要注意的是:对于验证和测试图像,我们只需要调整大小而不需要进行其他增强处理。因此,我们使用 augmentedImageDatastore 函数来自动调整大小,而不指定其他任何预处理操作。
augimdsValid = augmentedImageDatastore(inputSize(1:2),imdsValid); augimdsTest = augmentedImageDatastore(inputSize(1:2),imdsTest);
第五步:训练神经网络
当数据和网络模型都准备就绪后,我们可以开始训练模型了。
在迁移学习里,一般具有可学习参数的最后一层需要重新训练。它通常是一个全连接层或一个输出大小与标签类别数量匹配的卷积层。为了增加对该层的更新程度并加速收敛,您可以使用 setLearnRateFactor 函数增加这些层可学习参数的学习率因子。这里我们将它们的可学习参数的学习率因子设置为 10。
net = setLearnRateFactor(net,"res5c_branch2c/Weights",10);
net = setLearnRateFactor(net,"res5c_branch2c/Bias",10);
接着定义训练选项,如优化器和学习率等。这些选择需要进行经验分析。您可以使用MATLAB 的 Experiment Manager 应用程序,通过实验探索不同的训练选项。
作为示例,我们将训练选项设置如下:
使用 Adam 优化器进行训练。
为了减少对预训练权重的更新程度,使用较小的学习率。将学习率设置为 0.0001。
每 5 次迭代使用验证数据验证网络。对于较大的数据集,为防止验证减慢训练速度,可以增加此值。
在图中显示训练进度并监控准确率指标。
禁用详细输出。
options = trainingOptions("adam", ...
InitialLearnRate=0.0001, ...
MaxEpochs=3, ...
ValidationData=augimdsValid, ...
ValidationFrequency=5, ...
MiniBatchSize=11, ...
Plots="training-progress", ...
Metrics="accuracy", ...
Verbose=false);
然后,使用 trainnet 函数训练神经网络。对于图像分类,您可以使用交叉熵损失。要使用 GPU 训练模型,你需要一个Parallel Computing Toolbox 的许可证和一个支持的 GPU 设备。有关 MATLAB 所支持设备的更多信息,请参阅 GPU 计算要求。
默认情况下,如果有可用的 GPU,trainnet 函数将使用 GPU。否则,它将使用 CPU。您还可以在训练选项中设置 ExecutionEnvironment 参数以指定执行环境。
net = trainnet(augimdsTrain,net,"crossentropy",options);
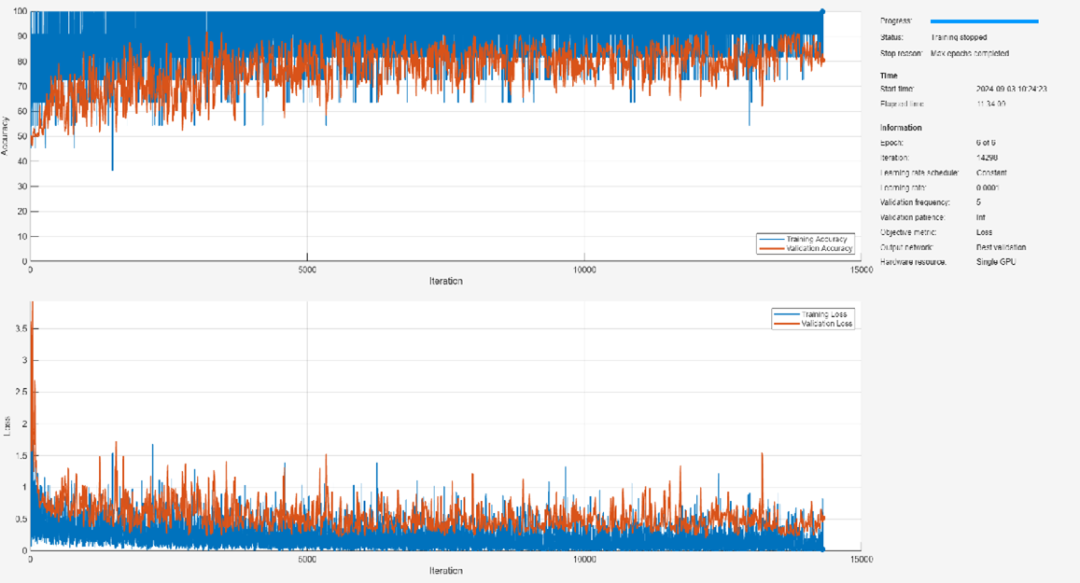
第六步:测试神经网络
然后在测试数据集上评估训练好的模型,以测试模型在未知数据上的表现。您可以使用 minibatchpredict 函数对多个观测进行预测。该函数也会在有可用 GPU 的情况下自动使用 GPU。
YTestScore = minibatchpredict(net,augimdsTest);
您还可以使用 scores2label 函数将预测得分转换为标签值。
YTest = scores2label(YTestScore,classNames);
让我们评估分类准确率,即测试数据的正确预测百分比,并在混淆矩阵中可视化分类准确率。
TTest = imdsTest.Labels; accuracy = mean(TTest==YTest); figure confusionchart(TTest,YTest); title(['Accuracy','approx',num2str(round(acc*10000)/100),'%'])
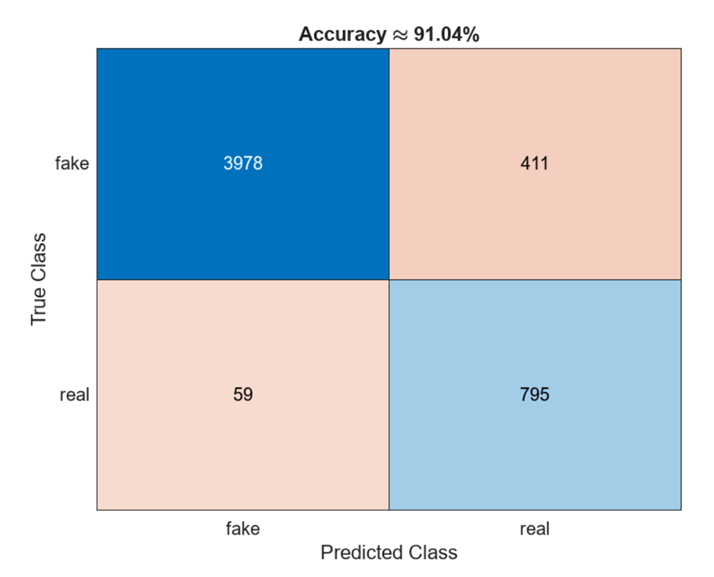
第七步:创建提交
当您对训练的模型感到满意时,可以将其应用于识别之后所发布的测试数据集并创建提交!由于目前用于评估的测试数据集目前还没有发布,我们在这里使用从训练数据集中所分割出来的测试数据集,展示如何利用代码自动创建符合提交格式要求的文件。
testImgSize = size(augimdsTest.Files,1);
fileId = cell(testImgSize,1);
for i = 1:testImgSize
fileId{i,1} = augimdsTest.Files{i}(1,end-10:end-4);
end
resultsTable = table(fileId, YTestScore(:,2));
outPutFilename = 'mySubmission.txt';
writetable(resultsTable,outPutFilename,'Delimiter',' ','WriteVariableNames',false,'WriteRowNames',false)
zip([pwd '/mySubmission.zip'],outPutFilename)
至此,您已经成功开启了深度伪造人脸检测项目!期待看到大家是如何应对这个挑战的!
最后
别忘了通过 MathWorks 的 2025 IEEE Signal Processing Cup 网站 申请免费的 MATLAB 竞赛软件许可,并探索更多资源!如果您有任何问题,请随时通过 studentcompetitions@mathworks.com 联系我们。
2025 IEEE Signal Processing Cup 将会是大家学习、创新并在国际舞台上展示技能的绝佳机会——不仅能收获人工智能和信号处理方向宝贵经验,还有机会为这个重要研究领域做出贡献,不容错过!
-
人脸检测模型有哪些2024-07-03 2779
-
红色警戒!深度伪造欺诈蔓延全球,ADVANCE.AI助力出海企业反欺诈新升级2024-06-12 1603
-
什么叫深度伪造技术 深度伪造技术发展趋势分析2023-07-21 2384
-
人工智能换脸为什么人脸转到90度时会出现漏洞?2022-08-16 1439
-
用OpenCV搭建活体检测器教程2021-11-05 3468
-
基于生成对抗网络的深度伪造视频综述2021-05-10 1689
-
【HarmonyOS HiSpark AI Camera】活体人脸检测2020-11-18 1582
-
采用人脸活体检测技术,防止恶意者伪造和窃取2020-06-17 1550
-
泰尔实验室推出“AI伪造人脸鉴别平台”,专门应对技术的安全风险2020-04-24 3067
-
人工智能如何避免深度伪造的出现2020-02-28 2921
-
深度学习在人脸检测中的应用2019-07-08 3815
-
基于深度学习与融入梯度信息的人脸姿态分类检测_苏铁明2017-01-08 885
-
人脸检测_嵌入式系统设计与实践项目报告2016-02-29 613
-
基于openCV的人脸检测系统的设计2014-12-23 4898
全部0条评论

快来发表一下你的评论吧 !
