

基于神经网络结构在命名实体识别中应用的分析与总结
电子说
描述
近年来,基于神经网络的深度学习方法在自然语言处理领域已经取得了不少进展。作为NLP领域的基础任务—命名实体识别(Named Entity Recognition,NER)也不例外,神经网络结构在NER中也取得了不错的效果。最近,本文作者也阅读学习了一系列使用神经网络结构进行NER的相关论文,在此进行一下总结,和大家一起分享学习。
1 引言
命名实体识别(Named Entity Recognition,NER)就是从一段自然语言文本中找出相关实体,并标注出其位置以及类型,如下图。它是NLP领域中一些复杂任务(例如关系抽取,信息检索等)的基础。

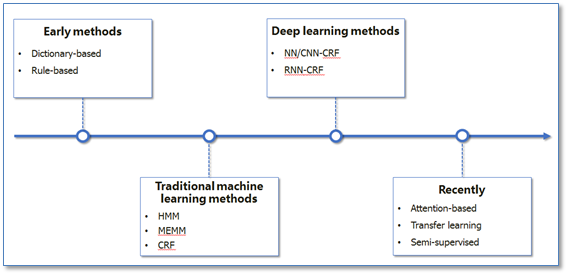
NER一直是NLP领域中的研究热点,从早期基于词典和规则的方法,到传统机器学习的方法,到近年来基于深度学习的方法,NER研究进展的大概趋势大致如下图所示。
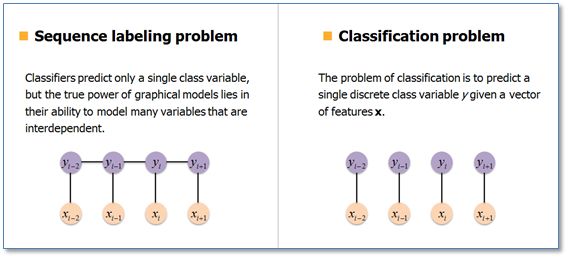
在基于机器学习的方法中,NER被当作是序列标注问题。与分类问题相比,序列标注问题中当前的预测标签不仅与当前的输入特征相关,还与之前的预测标签相关,即预测标签序列之间是有强相互依赖关系的。例如,使用BIO标签策略进行NER时,正确的标签序列中标签O后面是不会接标签I的。
在传统机器学习中,条件随机场(Conditional Random Field,CRF)是NER目前的主流模型。它的目标函数不仅考虑输入的状态特征函数,而且还包含了标签转移特征函数。在训练时可以使用SGD学习模型参数。在已知模型时,给输入序列求预测输出序列即求使目标函数最大化的最优序列,是一个动态规划问题,可以使用维特比算法进行解码。

在传统机器学习方法中,常用的特征如下:

接下里我们重点看看如何使用神经网络结构来进行NER 。
2 NER中主流的神经网络结构
2.1 NN/CNN-CRF模型
《Natural language processing (almost) from scratch》是较早使用神经网络进行NER的代表工作之一。在这篇论文中,作者提出了窗口方法与句子方法两种网络结构来进行NER。这两种结构的主要区别就在于窗口方法仅使用当前预测词的上下文窗口进行输入,然后使用传统的NN结构;而句子方法是以整个句子作为当前预测词的输入,加入了句子中相对位置特征来区分句子中的每个词,然后使用了一层卷积神经网络CNN结构。
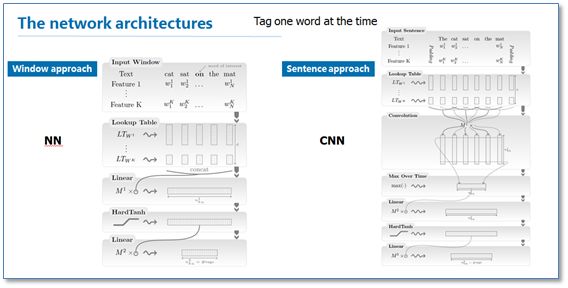
在训练阶段,作者也给出了两种目标函数:一种是词级别的对数似然,即使用softmax来预测标签概率,当成是一个传统分类问题;另一种是句子级别的对数似然,其实就是考虑到CRF模型在序列标注问题中的优势,将标签转移得分加入到了目标函数中。后来许多相关工作把这个思想称为结合了一层CRF层,所以我这里称为NN/CNN-CRF模型。

在作者的实验中,上述提到的NN和CNN结构效果基本一致,但是句子级别似然函数即加入CRF层在NER的效果上有明显提高。
2.2 RNN-CRF模型
借鉴上面的CRF思路,在2015年左右出现了一系列使用RNN结构并结合CRF层进行NER的工作。代表工作主要有: 将这些工作总结起来就是一个RNN-CRF模型,模型结构如下图:
将这些工作总结起来就是一个RNN-CRF模型,模型结构如下图:
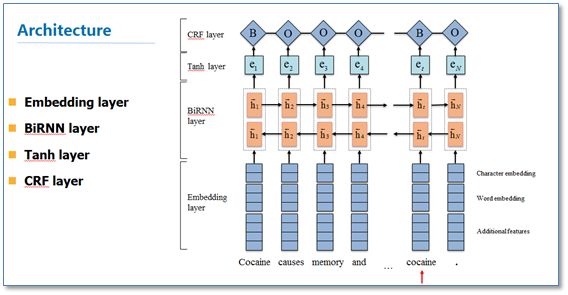
它主要有Embedding层(主要有词向量,字符向量以及一些额外特征),双向RNN层,tanh隐层以及最后的CRF层构成。它与之前NN/CNN-CRF的主要区别就是他使用的是双向RNN代替了NN/CNN。这里RNN常用LSTM或者GRU。实验结果表明RNN-CRF获得了更好的效果,已经达到或者超过了基于丰富特征的CRF模型,成为目前基于深度学习的NER方法中的最主流模型。在特征方面,该模型继承了深度学习方法的优势,无需特征工程,使用词向量以及字符向量就可以达到很好的效果,如果有高质量的词典特征,能够进一步获得提高。
3 最近的一些工作
最近的一年在基于神经网络结构的NER研究上,主要集中在两个方面:一是使用流行的注意力机制来提高模型效果(Attention Mechanism),二是针对少量标注训练数据进行的一些研究。
3.1 Attention-based
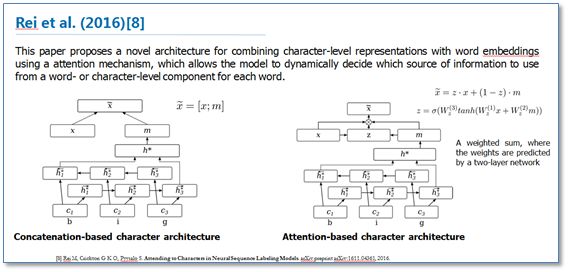
《Attending to Characters in Neural Sequence Labeling Models》该论文还是在RNN-CRF模型结构基础上,重点改进了词向量与字符向量的拼接。使用attention机制将原始的字符向量和词向量拼接改进为了权重求和,使用两层传统神经网络隐层来学习attention的权值,这样就使得模型可以动态地利用词向量和字符向量信息。实验结果表明比原始的拼接方法效果更好。
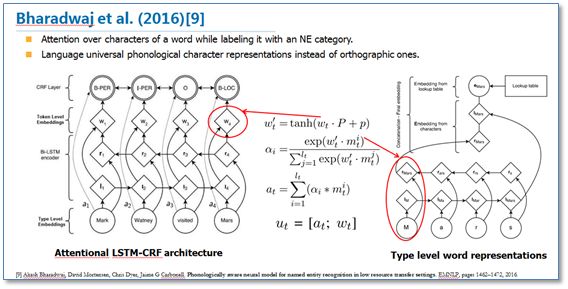
另一篇论文《Phonologically aware neural model for named entity recognition in low resource transfer settings》,在原始BiLSTM-CRF模型上,加入了音韵特征,并在字符向量上使用attention机制来学习关注更有效的字符,主要改进如下图。
3.2 少量标注数据
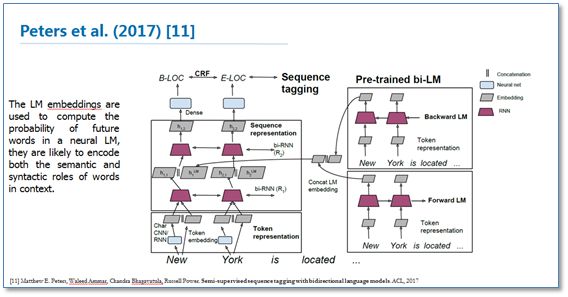
对于深度学习方法,一般需要大量标注数据,但是在一些领域并没有海量的标注数据。所以在基于神经网络结构方法中如何使用少量标注数据进行NER也是最近研究的重点。其中包括了迁移学习《Transfer Learning for Sequence Tagging with Hierarchical Recurrent Networks》和半监督学习。这里我提一下最近ACL2017刚录用的一篇论文《Semi-supervised sequence tagging with bidirectional language models》。该论文使用海量无标注语料库训练了一个双向神经网络语言模型,然后使用这个训练好的语言模型来获取当前要标注词的语言模型向量(LM embedding),然后将该向量作为特征加入到原始的双向RNN-CRF模型中。实验结果表明,在少量标注数据上,加入这个语言模型向量能够大幅度提高NER效果,即使在大量的标注训练数据上,加入这个语言模型向量仍能提供原始RNN-CRF模型的效果。整体模型结构如下图:
4 总结
最后进行一下总结,目前将神经网络与CRF模型相结合的NN/CNN/RNN-CRF模型成为了目前NER的主流模型。我认为对于CNN与RNN,并没有谁占据绝对的优势,各自有相应的优点。由于RNN有天然的序列结构,所以RNN-CRF使用更为广泛。基于神经网络结构的NER方法,继承了深度学习方法的优点,无需大量人工特征。只需词向量和字符向量就能达到主流水平,加入高质量的词典特征能够进一步提升效果。对于少量标注训练集问题,迁移学习,半监督学习应该是未来研究的重点。

-
粒子群优化模糊神经网络在语音识别中的应用2010-05-06 2580
-
HanLP分词命名实体提取详解2019-01-11 3544
-
基于结构化感知机的词性标注与命名实体识别框架2019-04-08 2106
-
【案例分享】ART神经网络与SOM神经网络2019-07-21 3327
-
HanLP-命名实体识别总结2019-07-31 2261
-
神经网络结构搜索有什么优势?2019-09-11 4299
-
基于自适应果蝇算法的神经网络结构训练2017-01-03 853
-
新型中文旅游文本命名实体识别设计方案2021-03-11 1302
-
一种改进的深度神经网络结构搜索方法2021-03-16 1199
-
命名实体识别的迁移学习相关研究分析2021-04-02 1467
-
神经网络在控制中的应用总结2021-04-21 1116
-
几种典型神经网络结构的比较与分析2021-04-28 1072
-
基于神经网络的中文命名实体识别方法2021-06-03 878
-
关于边界检测增强的中文命名实体识别2021-09-22 4146
-
卷积神经网络结构2023-08-17 2518
全部0条评论

快来发表一下你的评论吧 !
