

简单地描述了如何用机器学习绕过E-ZPass New York网站的验证码
描述
让我们一起攻破世界上最流行的WordPress的验证码插件每个人都讨厌验证码——在你被允许访问一个网站之前,你总被要求输入那些烦人的图像中所包含的文本。验证码被设计成,以验证你是一个真正的人的方式,来防止电脑自动填写表单。但是随着深度学习和计算机视觉的兴起,它们现在往往很容易被攻破。我在读Adrian Rosebrock的优秀的著作《Python计算机视觉深度学习》。在书中,Adrian简单地描述了他如何用机器学习绕过E-ZPass New York网站的验证码:
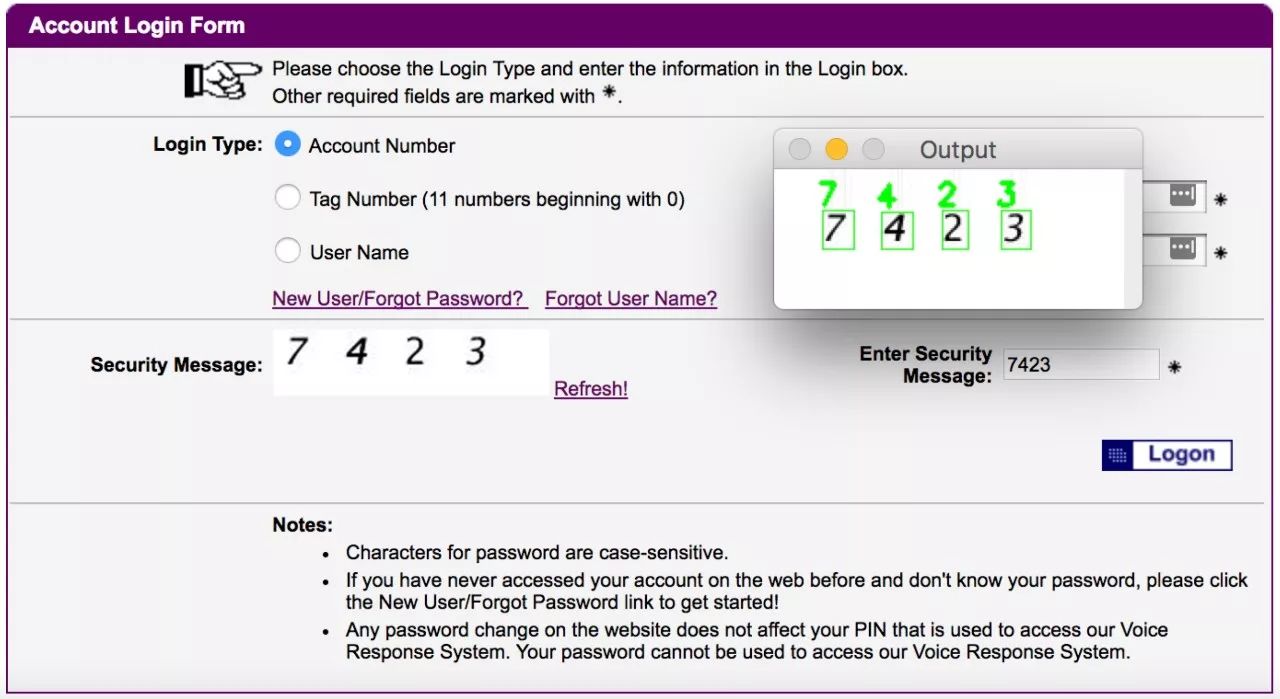
Adrian没有访问生成验证码图片的应用的源代码的权限。为了破解这个系统,他不得不下载成百上千个示例图像并手动解答它们,用以训练他的深度学习系统。但是如果我们想打破一个开放源代码的验证码系统,将会怎么样?我去wordpress.org插件注册表搜索“验证码”。最靠前的结果是一个叫“真正简单的验证码”的插件,有超过100万个活跃安装:
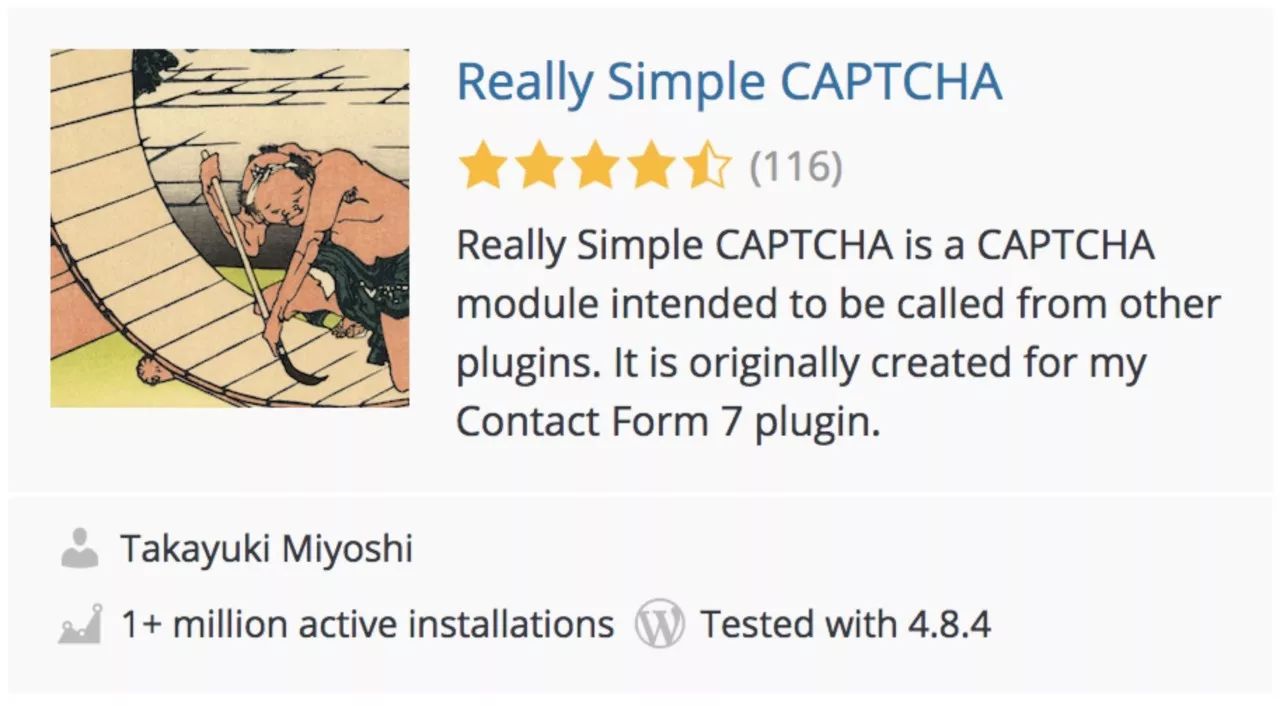
并且最好的一点是,它开源!因为我们有生成验证码的源代码,那么这应该是很容易破解的。为了让事情更有挑战性,让我们给自己一个时间限制。我们是否能够在15分钟内破解这个验证码系统?让我们试试看!重要提示:这绝不是针对“真正简单的验证码”这个插件或它的作者的批评。插件作者本人也说,这个插件不再安全,建议您使用其他东西。这只是一个快速而有趣的技术挑战。但是如果你是剩下的100万个用户中的一个,也许你应该切换到其他插件:)
挑战开始
为了打造一个进攻计划,让我们先来看看这个插件会生成哪种类型的图片。在演示站点上,我们看到这个:

好的,所以验证码图像似乎是四个字母。让我们在PHP源代码中验证这一点:
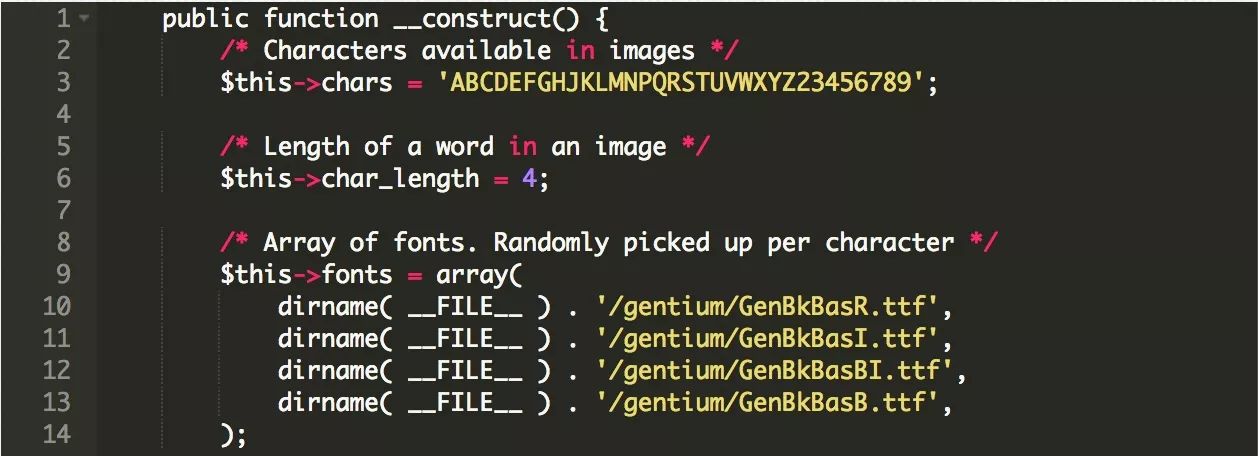
是的,它会产生一个四字母的验证码,并采用随机组合的四种不同的字体。我们可以看到,它从不在代码中使用“O”或“I”,以避免用户混淆。这给了我们总共32个可能需要识别的字母和数字。没问题!到目前为止时间过去:2分钟。
我们的工具集
在我们进一步讨论之前,让我们说一下为了解决这个问题我们将会用到的工具:Python3Python是一种非常有趣的编程语言,它有很好的机器学习和计算机视觉库。OpenCVOpenCV是一种流行的计算机视觉和图像处理框架。我们将使用OpenCV来处理验证码图像。它有一个Python应用接口,因此我们可以直接从Python中使用它。KerasKeras是一个由Python写的深度学习的框架。它可以使我们用最少的代码,方便地定义、训练和使用深层神经网络。TensorFlowTensorFlow是谷歌的机器学习库。我们会在Keras中写代码,但Keras并没有真正实现神经网络的逻辑本身,它其实是在后台调用谷歌的TensorFlow进行计算。好,现在让我们回到挑战!
创造我们的数据集
训练任何机器学习系统,我们都需要训练数据集。破解一个验证码系统,我们则需要训练数据看起来像这样:


这是唯一我不会给你示例代码的部分。我们这样做是为了教育,我不想让你真的去黑WordPress网站。不过,我会给你我最后生成的这10000张图像,以便你可以重复我的结果。到目前为止时间过去:5分钟。
简化问题
现在我们有了训练数据,我们可以直接用它来训练神经网络:
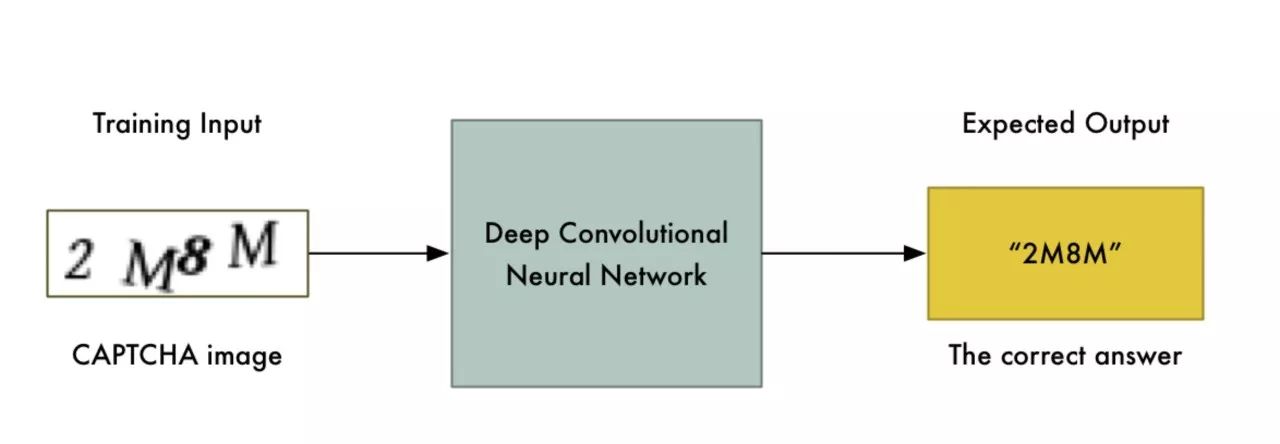
有足够的训练数据,这种粗暴的方法甚至也行得通 - 但我们可以使问题更容易解决。问题越简单,训练数据越少,计算资源消耗就越少。毕竟我们只有15分钟!幸运的是,验证码图像总是由四个字母组成。如果我们能用某种方式把图像分割开来,这样每一个字母都是一个独立的图像,那么我们只需要训练神经网络一次识别一个字母:
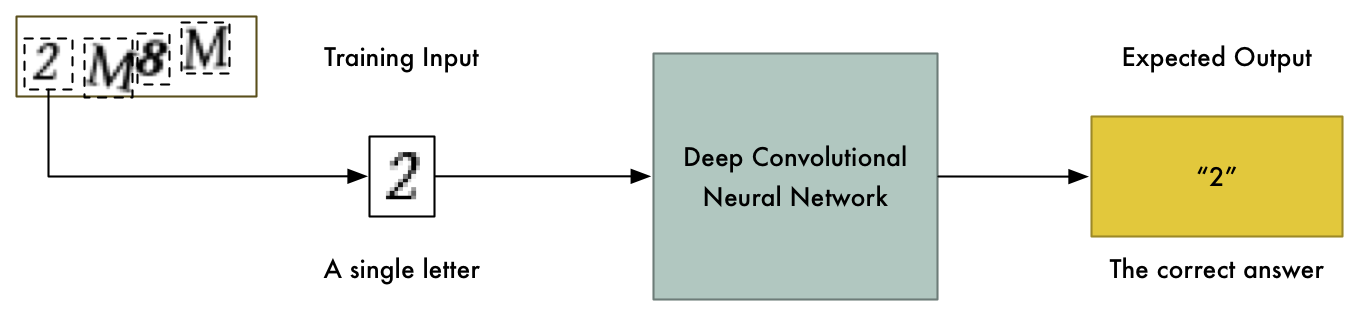
我没有时间浏览10000个训练图像,并在Photoshop中手动将它们分割成单独的图像。这将需要几天,而我只剩下10分钟了。而且我们不能将图像分成四个相同大小的块,因为验证码会将这些字母随机放置在不同的水平位置:
每个图像中的字母随机放置,使分割图像更难一些。
幸运的是,我们仍然可以自动执行此操作。在图像处理中,我们经常需要检测具有相同颜色的像素团。这些连续像素团周围的边界被称为轮廓。OpenCV有一个内置的findContours()函数,可以用来检测这些连续的区域。那么我们将从一个原始的验证码图像开始:
然后,我们将图像转换为纯黑白(这称为阈值设定),这样就很容易找到连续的区域:
接下来,我们将使用OpenCV的findContours()函数来检测图像中各个包含相同颜色像素的连续团:
那么只需将每个区域保存为一个单独的图像文件即可。而且由于我们知道每个图像应该包含从左到右的四个字母,所以我们可以使用这些知识来标记字母。只要我们按顺序保存它们,我们能够用适当的字母名称保存每个字母图像。但是等等 —— 我看到一个问题! 有时候验证码有这样的重叠字母:
这意味着我们最终将提取将两个字母拼凑在一起的区域:
如果我们不处理这个问题,我们最终会创建糟糕的训练数据。我们需要解决这个问题,以免我们不小心让机器把这两个相连的字母识别为一个字母。
我们将把任何宽度比高度还长的区域对半分开,并把它当作两个字母。这是很粗暴,但这么处理对识别这些验证码依然行得通。
现在我们有了一种提取单个字母的方法,让我们在所有的CAPTCHA图像上运行它。目标是收集每个字母的不同变化。我们可以将每个字母保存在自己的文件夹中。下面是我提取所有字母后,我的“W”文件夹的样子:
从我们的10000个验证码图像中提取的一些“W”字母。我一共得到了1147个不同的“W”图像。到目前为止时间过去:10分钟。
创建和训练神经网络
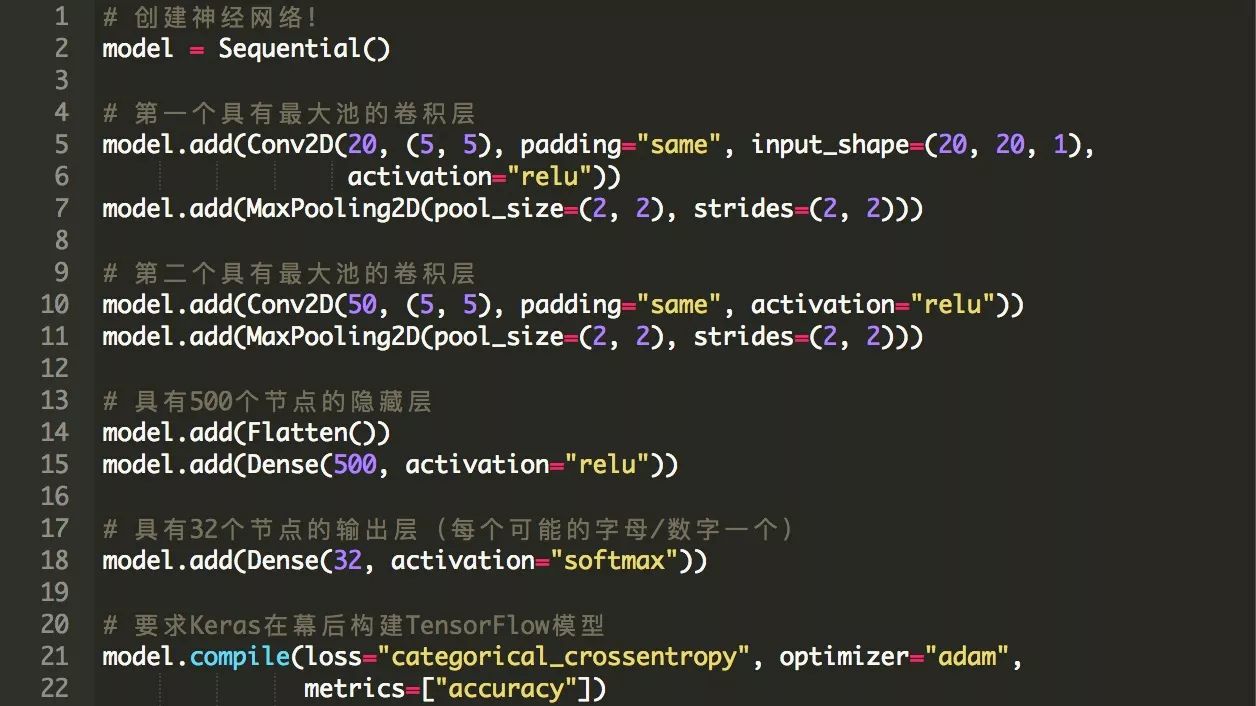
由于我们只需要识别单个字母和数字的图像,我们不需要一个非常复杂的神经网络架构。识别字母比识别诸如猫和狗的图片这样的复杂图像要容易得多。我们将使用具有两个卷积层和两个完全连接层的简单卷积神经网络结构:

如果你想知道更多关于卷积神经网络是如何工作的,为什么他们被用作图像识别非常理想,请查看Adrian的书或我以前的文章。用Keras定义这个神经网络体系结构只需要使用几行代码:
现在,我们可以开始训练它了!

用训练数据集训练10次后,我们达到了近100%的准确度。现在,只要我们想,我们应该能够自动绕过这个验证码了!我们做到了!到目前为止时间过去:15分钟。(~!)
使用训练的模型破解验证码
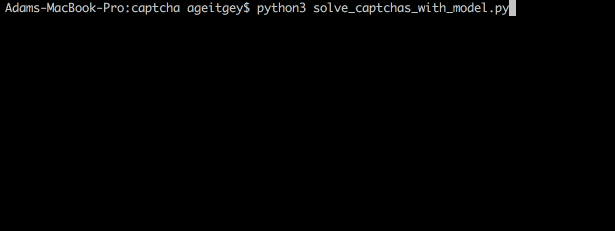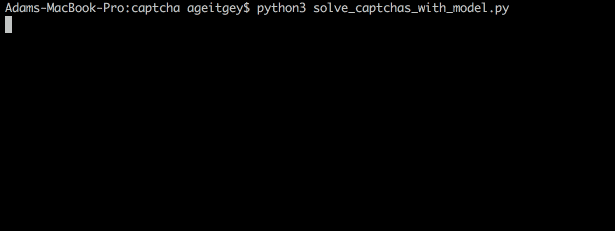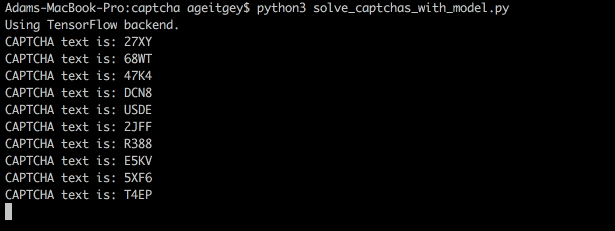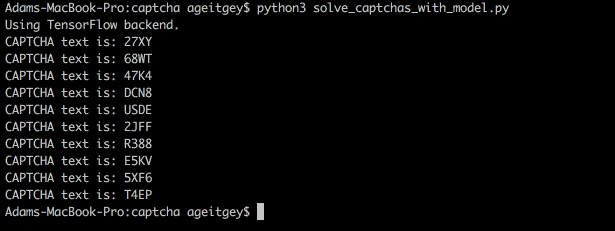
现在,我们有一个训练有素的神经网络,用它来破解真正的验证码非常简单:1.从使用该WordPress插件的网站抓取真实的验证码图像。2.使用我们用来创建训练数据集的相同方法,将验证码图像分解为四个单独的字母图像。3.要求我们的神经网络对每个字母图像做一个单独的预测。4.使用四个预测字母作为验证码的答案。5.愉快的玩耍吧以下是我们的模型如何解码真正的验证码
或者从命令行
-
自动化测试如何绕过Cloudflare验证码?Python + Selenium 脚本实战指南!2025-08-15 934
-
Java 中验证码的使用2023-09-25 2088
-
验证码到底在验证啥?聊一聊验证码是怎么为难我们人类的2023-08-12 3703
-
打码平台是如何高效的破解市面上各家验证码平台的各种形式验证码的?2022-11-01 2947
-
一文解析验证码与打码平台的攻防对抗2022-09-28 5188
-
带带弟弟OCR通用验证码识别SDK免费开源版2022-03-30 5800
-
爬虫实现目标网站验证码登陆2021-12-11 2871
-
验证码层出不穷?试试这个自动跳过验证码的工具2020-11-15 6835
-
如何使用Python机器学习解决验证码的资料说明2019-05-03 2718
-
以一个真实网站的验证码为例,实现了基于一下KNN的验证码识别2018-12-24 8468
-
如何利用机器学习破解验证码的源代码教程2018-04-30 6288
-
多样变换的手写验证码自动识别算法2017-12-20 884
-
无法验证邮箱,总是提示验证码错误,验证码明明是正确的。2017-05-12 10540
-
C#教程之中文验证码2016-04-20 648
全部0条评论

快来发表一下你的评论吧 !
