

了解时钟基础知识是成为数字设计的软件工程师最基础的部分
电子说
描述
如果你有软件工程师背景,想找一份数字设计工程师的工作,那么你需要做的第一件事就是尽可能早的学习时钟概念。对很多从软件工程师转来的初级硬件设计工程师来说,时钟概念都是一件恼人的事情。如果没有时钟,他们就可以将 HDL(Hardware Description Language,硬件描述语言)转换为一种编程语言,如 $display,if 和 for 循环,如同其他的任何编程语言一样。 然而,这些初级设计师所忽视的时钟,通常是数字设计中最基础的部分。
没有什么时候会比在审查初级 HDL 设计工程师第一次设计的产品的时候,所发现的问题更多。现在,我已经和几位在我参与的论坛上发表过问题的人交谈过了。而当深入了解后,发现他们正在做的是什么时,我为他们感到很尴尬。
以遇到的一个学生为例,他不理解为什么网络上没有人重视他的高级加密标准 (AES) 的HDL实现。此处,为了不让他因为名字或项目而尴尬,暂且将他称之为学生。(不,我不是教授。)这个“学生”创建了一个 Verilog 设计,进行不止一轮的 AES 加密,但每一轮都是组合逻辑,且两者之间没有时钟。 我不记得他是在做 AES-128、AES-192 还是 AES-256,但 AES 需要进行 10 到 14 轮计算。 我记得,他的加密引擎在模拟器中运行完美,然而他只使用一个时钟来加密或解密他的数据。 他为自己的工作感到自豪,但不明白为什么那些看过这个项目的人都对他说,他的思考方式像一个软件工程师,而不是一个硬件设计师。
事实上,我现在有机会给像这个“学生”一样的 HDL 新手软件工程师解释疑惑。 他们中的许多人对待 HDL 语言,就像对象另一种软件编程语言一样。 在编程之前,他们去寻找任何软件编程语言的基础知识:如何声明变量,如何创建一个 if 语句或 case 语句,如何编写循环等等。然后,他们编写代码就像编写一个计算机程序——一切都是顺序执行(图1),而完全忽略了数字设计中的基本事实,即所有运行都是并行的。
图1:软件执行是顺序的
有时这些程序员会使用模拟器,如 Verilator,iverilog 或者 EDA 平台。 然后,他们在逻辑代码中使用一堆$ display命令,将它们视为顺序的“printf”,并通过这些命令来使代码运行,而不是使用时钟。 他们的设计在模拟器中只是被单独地“执行”组合逻辑代码。
这些学生向我描述他们的设计,并解释称他们的设计“不需要时钟就能执行”。
天啊,这都是什么想法?
实际上,任何数字逻辑设计如果使用没有时钟都是不能工作的。总有一些物理过程会创建输入。而 这些输入必须在某个开始时间都有效 ——这个时间在其设计中形成第一个时钟刻度。 同样地,在接收这些输入一段时间后就要输出。 对于给定的一组输入,所有输出的有效时间在“无时钟”设计中形成下一个“时钟”。 或许第一个时钟刻度是当他们调整好电路板上的最后一个开关的时候,而最后一个时钟刻度是当他们读取到结果的时候。时钟是如何形成的没关系:有一个时钟就可以。
而这导致的结果就是,那些声称他们的设计“没有时钟”的人解释他正在以不切实际的方式使用模拟器,或者设计中存在一个外部时钟用于设置输入和读取输出 ——而这正是另外一种方式,表明设计中的确存在一个时钟。
如果你发现你自己正试图以这种方式理解数字逻辑必须有一个时钟才能执行,或你认识的某人也是这么尝试理解的,那么本文正适合你们。
接下来,让我们花一两分钟来讨论时钟,以及为什么围绕时钟来构建和设计你的数字逻辑很重要。
硬件设计是并行的
硬件设计学习中的第一部分也是最难的部分,就是硬件设计是并行设计。所有的代码指令并不是依次执行,如同一条指令连着下一条指令(如图1所示),就像计算机程序一样。相反,所有的指令在同一时刻执行,如图2所示。

图2:硬件逻辑并行运行
正是这一点,让很多东西变得不一样。
首先需要改变的是开发人员。你需要学习以并行的方式思考。
如果要通过举例说明两者的区别,硬件循环也许会是个不错的例子。
软件设计中,一个循环是由一连串的指令构成,如图3所示。这些指令构造了一组初始化条件,而真正的逻辑在循环内部执行。通过使用一个循环变量来构造和定义一个循环逻辑,并且这个变量在每次循环中通常都是增加的。计算机CPU不停地重复执行循环中的指令和逻辑,直到循环变量达到了终止条件。循环运行的次数越多,它在程序中运行的时间也就越长。
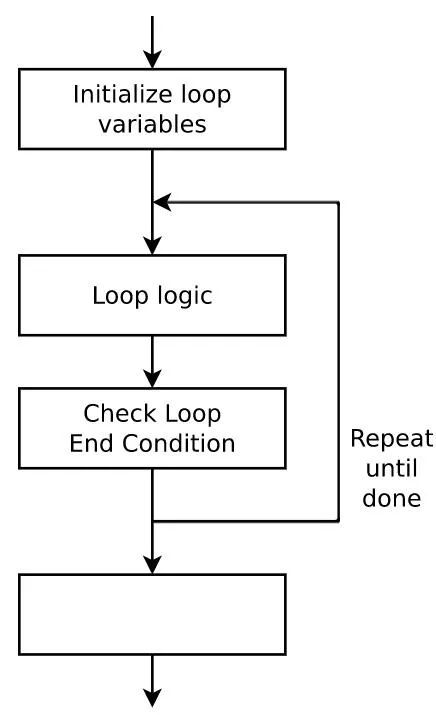
图3:软件循环
而基于硬件的硬件描述语言循环与软件循环完全不同。恰恰相反,HDL 合成工具使用循环来使得所有逻辑的副本同时并行运行。而用来构造循环逻辑的代码,如定义索引、索引增长、检查索引是否达到终止条件等等,是不需要合成的,通常会被移除。此外,由于合成工具正在构建物理线路和逻辑块,所以执行循环的次数在合成时间之后不能改变。之后,硬件的数量是固定的,不能再改变。
导致的结果便是,硬件循环结构(如下图4所示),与软件循环结构(如上图3所示)有很大的区别。

图4:HDL循环
这有几个后果。例如,硬件循环迭代与软件循环迭代不同,它不必依赖前期的循环迭代的输出。这导致的结果是,运行一个包含一组数据的逻辑循环很难在下一个时钟得到响应。
但是…现在让我们再次回到时钟概念。
时钟是任何 FPGA 设计的核心。一切都围绕着它展开。事实上,我认为所有的逻辑设计开发都应该从时钟开始。时钟不应该在设计完成后添加, 而是在你一开始思考如何设计架构时就要考虑。
为什么时钟很重要?
第一步,你要理解数字逻辑设计的一切操作在硬件上执行时都是需要时间的。不仅如此,不同的操作需要的时间总量也是不同的。从芯片上的一部分移动到另一部分也要花费时间。
或许用图表的方式能更直观的解释这一点。我们将输入置于算法的顶部,逻辑放在中间,而输出则放在底部。时间为轴,从上到下运行,从一个时钟到下一个时钟。这种视觉效果看起来就如下图 5 所示:
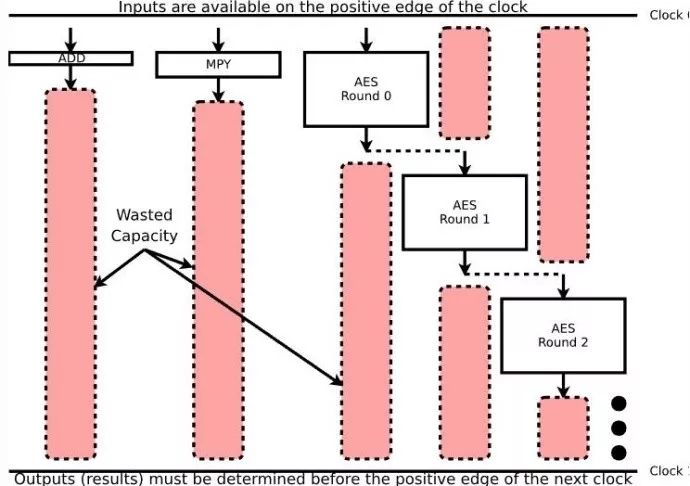
图5:三个操作的逻辑耗时
图例 5 展示了几个不同的操作:加法、乘法、以及多轮的 AES 算法——尽管为了讨论的目的,它可以是多轮任意其它算法。我在垂直方向上使用了方框的尺寸,以表示每个操作可能需要多少时间。此外,将依赖于其它操作的方框堆叠起来。因此,如果你想要在一个时钟里面做很多轮的 AES 算法,你要明白第二轮算法在第一轮算法结束后才会开始。因此,适应这一逻辑将会增加时钟之间的时间间隔,并减慢整体的时钟频率。
现在让我们关注这个粉色方框。
这个粉色框表示在硬件电路中浪费的运行能力,即你本可以用来做更多事情的时间,但因为需要等待时钟,或者等待输入被处理,而导致你什么也不能做。例如,在上面的概念图中,完成乘法运算所花费的时间不需要长达一轮 AES 算法的时间,加法也是。然而,当 AES 算法正在执行时,你不能够对这两个操作结果进行任何的动作,因为这些操作都需要等待下一个时钟来获取他们的下一个输入。这就是图 5 中粉色方框所表达的:空闲电路。另外,由于每一轮 AES 算法都会推迟下一个时钟的到来,所以图 5 中存在大量的空闲电路。因此,该设计的运行速度不会像硬件允许的那么快。
如果我们只使用 AES 算法,那么每一个时钟都正好完成一轮的 AES 计算。如此一来,就可以减少运行能力的浪费,从而让整个设计运行得更快。
图 6 展示了这种设计思想。
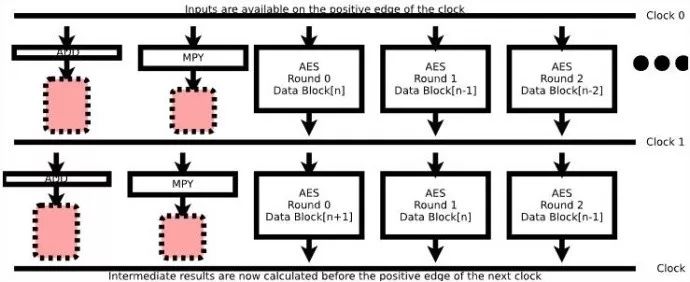
图6:分解操作加快时钟频率
由于我们将操作分解为更小的操作,每一个都能在时钟单元内完成,因此,我们提高了运行能力。甚至,我们可以通过管道加密算法,而不是一次只加密一个数据块。这种逻辑设计的结果不会比上图 5 所示的更快,但是如果可以保持管道充满,则可以提高 AES 加密吞吐量至 10-14x 之间。
所以,这个设计更赞。
还可以有其它更好的方案吗?当然!如果你熟悉 AES ,你就知道 AES 算法的每一轮计算中都有一些独立的步骤。这些步骤可再次分解,从而可以再次提高每轮逻辑算法的整体时钟速度。而这可以增加你能执行的加法和乘法运算的次数,以及加密引擎的微管道,以便你能在每个时钟的基础上运行更多的数据。
设计不错。
不过,上图 6 中还有些其它的东西。
首先,箭头表示路由延迟。(这个数字不是按比例绘制的,它仅仅是这个讨论例子的示例。)每一块逻辑都需要上一块逻辑将结果传递给它。这意味着即使某个逻辑块不需要时间执行——例如,只是重新排列线路或其它等等,将逻辑块从一个芯片的末端移动到另一块也是需要花费时间的。所以,即使你将操作极简化了,每一轮数据的传递仍旧存在延迟。
其次,你可能注意到,没有一个箭头的起始处在时钟刻度上,即没有一个逻辑块一直运行到下个时钟开始。这是为了演示 启动时间和维持时间的概念。触发器电路,即一种捕获数据并同步到时钟的电路结构,在下一个时钟到达前需要一定的时间,此刻数据也已经是固定和确定的。另外,尽管时钟通常被认为是瞬时的,但它从来都不是。它在不同的时刻到达芯片的不同部位。而这再次要求操作之间需要一些缓冲。
通过以上讨论,我们可以得出哪些结论呢?
逻辑实现需要花费时间。
逻辑越多花费的时间也越多。
完成两个时钟刻度之间的逻辑所花费的时间总和(包含例行的延迟、启动和维持时间、时钟不确定性等),限制了时钟速度。时钟之间的逻辑处理越多,时钟速率就越慢。
完成最慢操作所需的时钟速度,限制了最快操作的速度。正如上述例子中的加法操作。它的执行速度本可以比乘法以及任何一轮单独的 AES 算法都更快,但它的速度在该设计中被其余的逻辑拖慢了。
硬件定义也会限制时钟速度。即使操作中不包含任何的逻辑,也是需要花费时间的。
因此,平衡的设计尝试在整个设计中将大量相同的逻辑放在时钟之间。
时钟之间应该放多少逻辑量?
现在你已经知道你必须处理时钟,那么根据上述信息你该怎么修改和构思你的设计?答案是限制时钟之间的逻辑数量。但问题是,这个数量是多少呢?你又该如何得到这个数量呢?
得出时钟之间你能放置多少逻辑数量的一个方法便是,将时钟速度设置为任意速度,然后在与你需要的硬件配套的工具套件中构建你的设计。无论何时,当你的设计无法满足其计时需求时,都需要返回并拆分设计中的组件,或减慢时钟速度。通过使用设计工具,你最终能够找到那条最长的路径。
如果你这样做了,你将自学到一些探索方法,然后通过使用这些方法,就可以找到在运行的硬件的时钟之间可以放置的具体逻辑数量。
例如,我倾向于在 Xilinx 7 系列零件中进行 100MHz 时钟速率的设计。这些设计通常运行在大约 80MHz 速率的Spartan-6 上,或者50MHz的 iCE40上——尽管这些都不是硬性关系。把在一个芯片上正常执行的程序放在另一个上执行,可能会超载,亦可能会时钟检查失败。
下面有一些我曾经在使用时钟时得到的一些粗略的探索性经验。由于只是个人经验,这些方法并不适合所有的设计:
1.通常,我在设计一个32 位的加法时,会使用一个时钟内有 4-8个条目的多路复用器。
如果要使用一个较快的时钟,例如频率为 200 MHz,可能就需要将加法操作从多路复用器上剥离下来。
ZipCPU 的最长路径,实际上是从 ALU 的输出到 ALU 的输入。
这听起来很简单。它甚至符合前面的经验法则。
但 ZipCPU 的问题在于,如何在较快的速度下将输出路由回输入。
让我们跟踪一下这个路径:跟随 ALU,逻辑路径首先通过一个4路多路复用器来决定是否ALU,内存或分频输出需要回写。 然后将该回写结果馈送到旁路电路中,以确定是否需要将其立即传入 ALU 作为其两个输入之一。 只有在该多路复用器末端并且旁路路径执行 ALU 操作时,多路复用器才会产生。 因此,所有这些逻辑步骤都会在通过 ALU 时造成压力。 然而,由于ZipCPU的设计结构,任何在此路线的时钟都可能会按比例减缓 ZipCPU 运行速度。 这意味着有可能这条最长线路仍然是 ZipCPU 中最长的一段线路。
我曾经对以更高的速度运行 ZipCPU 感兴趣,这是我尝试分解和优化的第一个逻辑路径。
2.16×16位乘法器需要一个时钟。
有时,在某些硬件上,我可以在一个时钟上运行 32×32 位的乘法。而在其他硬件上,我需要分解这个操作。 因此,如果我需要一个签名的 32×32 位乘法,我使用我专门为此建立的流水线例程。 该例程包含其中的几种乘法方法,允许我从适合我目前正在工作的硬件的选项中进行选择。
你的硬件可能也还支持 18×18 位乘法。 一些 FPGA 还支持在一个优化的硬件时钟内进行乘法和累加。只要你对使用的硬件足够熟悉,你就知道你能用它做什么。
3. 访问任何 RAM 块都需要一个时钟。
如果可以的话,应尽量避免在该时钟周期调整索引。 同样,避免在此时钟期间做任何有关输出的事情。
尽管我认为这是一条很好的规则,但我已经在 100MHz 的 Xilinx 7 系列设备上违反了其中的两个部分,而没有产生(严重的)影响。 (在 iCE40 设备上有问题。)
例如,ZipCPU 从寄存器读取数据,给结果加上一个即时数,然后从结果中选择是否应该在寄存器、PC上,还是条件代码寄存器中加上即时数——都在一个时钟内。
另外一个例子就是,长期以来 Wishbone Scope 根据当前时钟是否从存储器进行读取,确定从缓冲区内读取的地址。 从这个依赖中断它,需要添加另一个延迟时钟,所以当前版本不会再破坏这个(自我强加的)规则。
这些规则只是我随着时间积累下来的方法经验,用来判定单个时钟内可容纳的逻辑数量。 这些经验法则与设备和时钟速度有关,因此它们可能不适用于你的设计开发。 我建议你积累自己的探索经验,以便你知道在时钟周期之间能做些什么。
下一步
也许我能够提供给任何新的 FPGA 开发人员的最后建议,就是学习 HDL 时要在实际硬件上进行练习,而不仅仅是在模拟器上。与实际硬件组件相关联的工具,其在检查代码和计算所需时间方面都很出色。 此外,以高速时钟构建设计的想法是好的,但这不是硬件设计的最终结果。
记住,硬件设计是并行的。 一切都从时钟开始。
-
如何成为一名嵌入式软件工程师?2025-04-15 4837
-
嵌入式软件工程师如何提升自己?2024-06-12 3193
-
嵌入式软件工程师和硬件工程师的区别?2024-05-16 8176
-
嵌入式软件工程师是什么?2021-12-24 3565
-
Python成为软件工程师的最爱2021-11-27 6452
-
关于嵌入式软件工程师的七问七答2021-09-09 2660
-
软件工程师该了解的时钟知识2020-05-04 1193
-
如何成为谷歌软件工程师2019-09-03 3892
-
硬件工程师必备要了解哪些基础知识2018-10-30 2210
-
软件工程师的从业要求有哪些2018-09-19 7339
-
硬件工程师和软件工程师哪个更有前途?2017-08-23 4404
-
诚聘FPGA软件工程师2017-02-17 3982
-
招聘:软件工程师(数字信号处理方向-FPGA)、硬件工程师2015-04-25 3726
-
嵌入式工程师比普通软件工程师好在哪里?2014-11-20 4266
全部0条评论

快来发表一下你的评论吧 !
