

黑科技大揭秘交通标志识别为什么能实现98%准确率?
MEMS/传感技术
描述
我们可以创建一个能够对交通标志进行分类的模型,并且让模型自己学习识别这些交通标志中最关键的特征。在这篇文章中,我将演示如何创建一个深度学习架构,这个架构在交通标志测试集上的识别准确率达到了98%。
交通标志是道路基础设施的重要组成部分,它们为道路使用者提供了一些关键信息,并要求驾驶员及时调整驾驶行为,以确保遵守道路安全规定。如果没有交通标志,可能会发生更多的事故,因为司机无法获知最高安全速度是多少,不了解道路状况,比如急转弯、学校路口等等。现在,每年大约有130万人死在道路上。如果没有这些道路标志,这个数字肯定会更高。
当然,自动驾驶车辆也必须遵守交通法规,因此需要_识别_和_理解_交通标志。
从传统上来说,可以使用标准的计算机视觉的方法来对交通标志进行检测和分类,但同时也需要耗费相当多的时间来手工处理图像中的重要特征。现在,我们引入深度学习技术来解决这个问题。我们可以创建一个能够对交通标志进行分类的模型,并且让模型自己学习识别这些交通标志中最关键的特征。在这篇文章中,我将演示如何创建一个深度学习架构,这个架构在交通标志测试集上的识别准确率达到了98%。
项目设置
数据集可分为训练集、测试集和验证集,具有以下特点:
图像为32(宽)×32(高)×3(RGB彩色通道)
训练集由34799张图片组成
验证集由4410个图像组成
测试集由12630个图像组成
共有43个种类(例如限速20公里/小时、禁止进入、颠簸路等等)
此外,我们将使用Python 3.5与Tensorflow来编写代码。
图像及其分布
你可以在下图中看到数据集中的一些示例图像,图像的标签显示在相应行的上方。其中一些非常暗,稍后我们会调整它们的对比度。
训练集中各个种类图像的数量明显不平衡,如下图所示。某些种类的图片少于200张,而其他的则有2000多张。这意味着我们的模型可能会偏向于代表性过高的种类,特别是当它的预测无法确定时。我们稍后会看到如何使用数据增强来缓解这个问题。
预处理步骤
我们首先要对图像应用两个预处理步骤:
灰度化
把三通道的图像转换为单通道灰度图像,如下图所示。
归一化
我们通过用数据集平均值减去每个图像并除以其标准偏差来确定图像数据集分布的中心。这有助于提高模型在处理图像时的一致性。生成的图像如下所示:
模型的架构
交通标志分类器架构的灵感来自于Yann Le Cun的这篇论文。我们在他的基础上做了一些调整,并创建了一个模块化的代码库,它允许我们尝试不同的过滤器大小、深度和卷积层的数量,以及完全连接层的维度。为了向Le Cun致敬,我们称这样的网络为**_EdLeNet_** :)。
我们将主要尝试5x5和3x3大小的过滤器(又名内核),并且卷积层的深度从32开始。 EdLeNet的3x3架构如下所示:
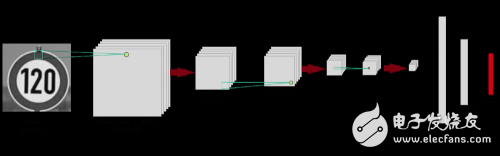
该网络由3个卷积层组成,内核大小为3x3,下一层的深度加倍,使用ReLU作为激活函数,每一层的后面是最大2×2的池操作。最后3层完全连接,最后一层能产生43个结果(可能的标签总数),使用SoftMax作为激活函数。这个网络使用附带Adam优化器的迷你批次随机梯度下降算法进行训练。我们编写了高度模块化的基础代码,这使得我们能够_动态_创建模型,示例代码片段如下:

ModelConfig包含了模型的相关信息,比如:
模型的函数(例如:EdLeNet)
模型的名称
输入的格式(例如:灰度等级为[32,32,1]),
卷积层的配置[过滤器大小、起始深度、层数],
完全连接层的大小(例如:[120,84])
种类的数量
dropout(丢弃)百分比值[p-conv,p-fc]
ModelExecutor负责_训练_、_评估_、_预测_,以及生成_激活_映射的可视化效果。
为了更好地隔离模型,并确保它们不是全部都在相同的Tensorflow图下,我们使用下面这个比较有用的结构:

这样,我们就能为_每个_模型创建单独的图,并确保没有混入变量、占位符。这为我解决了很多麻烦。
我们实际上是以卷积深度为16开始的,但在深度为32的时候获得了更好的结果并最终确定了这个值。我们还比较了彩色与灰度图像、标准和归一化的图像,最后发现灰度图往往优于彩色图。不幸的是,我们在3x3或5x5的模型上最高勉强达到了93%的测试准确率,而后来一直没有达到这个准确率。你可以在下图中看到针对不同模型配置的一些指标图。
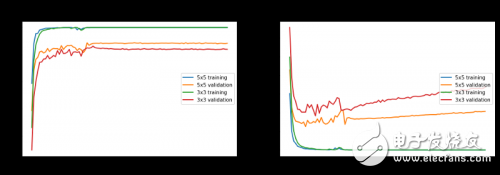
在颜色归一化图像上的模型性能
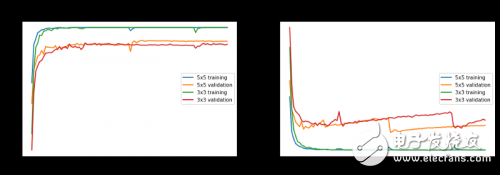
在灰度归一化图像上的模型性能
Dropout(丢弃)算法
为了提高模型的可靠性,我们需要使用dropout算法,这个算法是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。这样可以防止模型过度拟合。Dropout算法最早是由深度学习领域的先驱Geoffrey Hinton提出来的。要更好地理解背后地动机,务必阅读一下这篇论文。
在论文中,作者根据层类型的不同应用不同概率值进行丢弃。因此,我决定采用类似的方法,定义两个级别的dropout,一个用于卷积层,另一个用于完全连接层:
此外,随着进入到更深层次的网络,作者逐渐开始采用更积极的dropout值。所以我也决定这样:
这样做的原因是,我们把网络看作是一个漏斗,当我们深入到层中时,希望逐渐收紧它:我们不想在开始的时候丢弃太多的信息,因为其中的一些相当有价值。此外,在卷积层中应用MaxPooling的时候,我们已经失去了一些信息。
我们尝试过不同的参数,但最终结果是_p-conv = 0.75_和_p-fc = 0.5_,这使得我们可以使用3x3的模型在归一化灰度图上实现97.55%的测试集准确率。有趣的是,我们在验证集上的准确率达到了98.3%以上:

引入dropout算法后,在灰度归一化图像上的模型性能
上面的图表显示,这个模型更为_平滑_。我们已经在测试集上实现了准确率超过93%这个目标分数。下面,我们将探索一些用于处理每一个点的技术。
直方图均衡化
直方图均衡化是一种计算机视觉技术,用于增强图像的对比度。由于一些图像受到了低对比度(模糊、黑暗)的影响,因此我们将通过应用OpenCV的对比度限制自适应直方图均衡来提高可视性。
我们再次尝试了各种配置,并找到了最好的结果,**测试精度达到了97.75%**,在3x3的模型上使用以下dropout值:_p-conv = 0.6_,_p-fc = 0.5_。
尽管做了直方图均衡化,但有些图像仍然非常模糊,并且有些图像似乎是失真的。在我们的测试集中没有足够的图像示例来改进模型的预测。另外,虽然97.75%的测试准确率已经相当不错,但我们还有另外一个杀手锏:数据增强。
#p#数据增强
#e#
数据增强
我们在早些时候曾经发现,43个种类的数据明显不平衡。然而,它似乎并不是一个棘手的问题,因为即使这样,我们也能够达到非常高的准确度。我们也注意到测试集中有一些图像是失真的。因此,我们将使用数据增强技术来尝试:
扩展数据集,并在不同的照明条件和方向上提供其他图片
提高模型的通用性
提高测试和验证的准确性,特别是对失真的图像
我们使用了一个名为imgaug的库来创建扩展数据。我们主要应用仿射变换来增强图像。代码如下:
虽然种类数量的不平衡可能会在模型中引入偏差,但我们决定在现阶段不解决这个问题,因为这会导致数据集数量的增加,延长训练时间。相反,我们决定为每个种类增加10%的图像。我们的新数据集如下。
图像的分布当然不会发生显著的变化,但是我们确实对图像应用了灰度化、直方图均衡化,以及归一化等预处理步骤。我们训练2000次,附加dropout算法(_p-conv = 0.6_,_p-fc = 0.5_),并在测试集上达到**97.86%的准确率:**
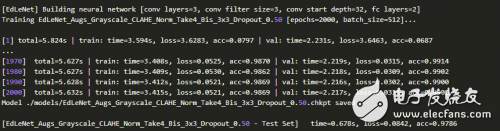
这是迄今为止最好的结果!!!
但是,看看训练集上的损失指标,0.0521,我们很有可能还有一些改进的空间。未来,我们将执行更多的训练次数,我们会报告最新成果的。
结论
本文探讨了如何将深度学习应用于分类交通标志,其中包含了各种预处理和归一化技术,以及尝试了不同的模型架构。我们的模型在测试集上达到了接近98%的准确率,在验证集上达到了99%的准确率。
- 相关推荐
- 热点推荐
- 深度学习
-
TF之LoR:基于tensorflow实现手写数字图片识别准确率2018-12-19 2528
-
基于RBM实现手写数字识别高准确率2018-12-28 2870
-
请问谁做过蚁群算法选择图像特征,使识别准确率最高?2019-02-17 3358
-
交通标志结构的有限元优化设计2009-09-15 850
-
实用交通标志自动识别方法2009-10-31 885
-
自然场景下交通标志的自动识别算法2010-02-21 697
-
三角形交通标志的智能检测方法2010-02-23 890
-
公路交通标志标线设置指南2010-11-04 1359
-
基于线性CCD视觉信息的道路交通标志识别系统2016-04-28 841
-
最新人脸识别算法不看脸也能准确工作2016-08-10 1513
-
交通标志牌检测算法2017-11-15 955
-
使用深度学习算法识别交通标志实现98%准确率2017-11-22 1245
-
基于颜色的图像快速分割的交通标志检测2017-11-29 785
-
基于优化CNN结构的交通标志识别算法2017-12-06 1080
-
ai人工智能回答准确率高吗2024-10-17 10310
全部0条评论

快来发表一下你的评论吧 !
