

苹果Siri深度学习语音合成技术揭秘
便携设备
描述
Siri 是一个使用语音合成技术与人类进行交流的个人助手。从 iOS 10 开始,苹果已经在 Siri 的语音中用到了深度学习,iOS 11 中的 Siri 依然延续这一技术。使用深度学习使得 Siri 的语音变的更自然、流畅,更人性化。
介绍
语音合成,也就是人类声音的人工产品,被广泛应用于从助手到游戏、娱乐等各种领域。最近,配合语音识别,语音合成已经成为了 Siri 这样的语音助手不可或缺的一部分。
如今,业内主要使用两种语音合成技术:单元选择 [1] 和参数合成 [2]。单元选择语音合成技术在拥有足够高质量录音时能够合成最高质量的语音,也因此成为商业产品中最常用的语音合成技术。另外,参数合成能够提供高度可理解的、流畅的语音,但整体质量略低。因此,在语料库较小、低占用的情况下,通常使用参数合成技术。现代的单元选择系统结合这两种技术的优势,因此被称为混合系统。混合单元选择方法类似于传统的单元选择技术,但其中使用了参数合成技术来预测选择的单元。
近期,深度学习对语音领域冲击巨大,极大的超越了传统的技术,例如隐马尔可夫模型。参数合成技术也从深度学习技术中有所收益。深度学习也使得一种全新的语音合成技术成为了可能,也就是直接音波建模技术(例如 WaveNet)。该技术极有潜力,既能提供单元选择技术的高质量,又能提供参数选择技术的灵活性。然而,这种技术计算成本极高,对产品而言还不成熟。为了让所有平台的 Siri 语音提供最佳质量,苹果迈出了这一步,在设备中的混合单元选择系统上使用了深度学习。
苹果深度语音合成技术工作原理
为个人助手建立高质量的文本转语音(TTS)系统并非简单的任务。首先,第一个阶段是找到专业的播音人才,她/他的声音既要悦耳、易于理解,又要符合 Siri 的个性。为了覆盖各种人类语音,我们首先在录音棚中记录了 10-20 小时的语音。录制的脚本从音频簿到导航指导,从提示答案到笑话,不一而足。通常来说,这种天然的语音不能像录制的那样使用,因为不可能录制助手会说的每一句话。因此,单元选择 TTS 系统把记录的语音切片成基础元件,比如半音素,然后根据输入文本把它们重新结合,创造全新的语音。在实践中,选择合适的音素并组合起来并非易事,因为每个音素的声学特征由相邻的音素、语音的韵律所决定,这通常使得语音单元之间不相容。图 1 展示了如何使用被分割为半音素的数据库合成语音。
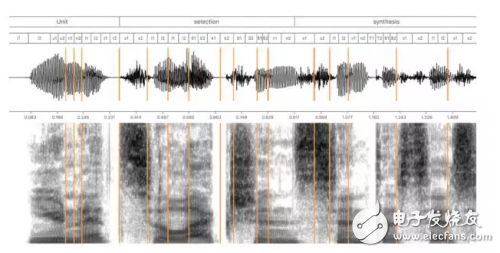
图 1:展示了使用半音素进行单元选择语音合成。合成的发音是「Unit selection synthesis」,图的顶部是使用半音素的标音法。相应的合成波形与光谱图在图下部分。竖线划分的语音段是来自数据集的持续语音段,数据集可能包含一个或多个半音素。
单元选择 TTS 技术的基本难题是找到一系列单元(例如,半音素),既要满足输入文本、预测目标音韵,又要能够在没有明显错误的情况下组合在一起。传统方式上,该流程包含两部分:前端和后端(见图 2),尽管现代系统中其界限可能会很模糊。前端的目的是基于原始文本输入提供语音转录和音韵信息。这包括将包含数字、缩写等在内的原始文本规范化写成单词,并向每个单词分配语音转录,解析来自文本的句法、音节、单词、重音、分句。要注意,前端高度依赖语言。
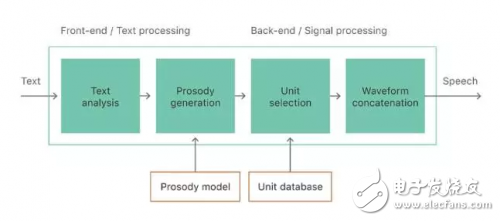
图 2:文本转语音合成流程。
使用由文本分析模块创建的符号语言学表征,音韵生成模块预测音调、音长等声学特征的值。这些值被用于选择合适的单元。单元选择的任务极其复杂,所以现代的合成器使用机器学习方法学习文本与语音之间的一致性,然后根据未知文本的特征值预测其语音特征值。这一模块必须要在合成器的训练阶段使用大量的文本和语音数据进行学习。音韵模型输入的是数值语言学特征,例如音素特性、音素语境、音节、词、短语级别的位置特征转换为适当的数值形式。音韵模型的输出由语音的数值声学特征组成,例如频谱、基频、音素时长。在合成阶段,训练的统计模型用于把输入文本特征映射到语音特征,然后用来指导单元选择后端流程,该流程中声调与音长的合适度极其重要。
与前端不同,后端通常是语言独立的。它包括单元选择和波形拼接部分。当系统接受训练时,使用强制对齐将录制的语音和脚本对齐(使用语音识别声学模型)以使录制的语音数据被分割成单独的语音段。然后使用语音段创建单元数据库。使用重要的信息,如每个单元的语言环境(linguistic context)和声学特征,将该数据库进一步增强。我们将该数据叫作单元索引(unit index)。使用构建好的单元数据库和指导选择过程的预测音韵特征,即可在语音空间内执行 Viterbi 搜索,以找到单元合成的最佳路径(见图 3)。
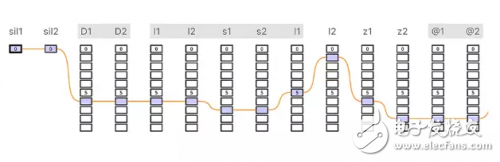
图 3. 使用 Viterbi 搜索在栅格中寻找单元合成最佳路径。图上方是合成的目标半音素,下面的每个框对应一个单独的单元。Viterbi 搜索找到的最佳路径为连接被选中单元的线。
该选择基于两个标准:(1)单元必须遵循目标音韵;(2)在任何可能的情况下,单元应该在单元边界不产生听觉故障的情况下完成拼接。这两个标准分别叫作目标成本和拼接成本。目标成本是已预测的目标声学特征和从每个单元抽取出的声学特征(存储在单元索引中)的区别,而拼接成本是后项单元之间的声学区别(见图 4)。总成本按照如下公式计算:
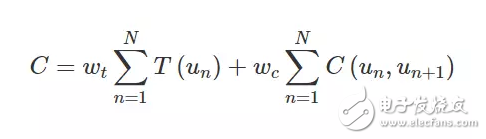
其中 u_n 代表第 n 个单元,N 代表单元的数量,w_t 和 w_c 分别代表目标成本和拼接成本的权重。确定单元的最优顺序之后,每个单元波形被拼接,以创建连续的合成语音。
图 4. 基于目标成本和拼接成本的单元选择方法。
Siri 新声音背后的技术
因为隐马尔可夫模型对声学参数的分布直接建模,所以该模型通常用于对目标预测 [5][6] 的统计建模,因此我们可以利用如 KL 散度那样的函数非常简单地计算目标成本。然而,基于深度学习的方法通常在参数化的语音合成中更加出色,因此我们也希望深度学习的优势能转换到混合单元选择合成(hybrid unit selection synthesis)中。
Siri 的 TTS 系统的目标是训练一个基于深度学习的统一模型,该模型能自动并准确地预测数据库中单元的目标成本和拼接成本(concatenation costs)。因此该方法不使用隐马尔可夫模型,而是使用深度混合密度模型(deep mixture density network /MDN)[7][8] 来预测特征值的分布。MDS 结合了常规的深度神经网络和高斯混合模型(GMM)。
常规 DNN 是一种在输入层和输出层之间有多个隐藏层的人工神经网络。因此这样的深度神经网络才能对输入特征与输出特征之间的复杂和非线性关系建模。通常深度神经网络使用反向传播算法通过误差的传播而更新整个 DNN 的权重。相比之下,GMM 在使用一系列高斯分布给定输入数据的情况下,再对输出数据的分布进行建模。GMM 通常使用期望最大化(expectation maximization /EM)算法执行训练。MDN 结合了 DNN 和 GMM 模型的优点,即通过 DNN 对输入和输出之间的复杂关系进行建模,但是却提高概率分布作为输出(如下图 5)。
图 5:用于对声音特征的均值和方差建模的深度混合密度网络,输出的声学均值和方差可用于引导单元选择合成
对于 Siri 来说,我们使用了基于 MDN 统一的目标和拼接模型,该模型能预测语音目标特征(频谱、音高和音长)和拼接成本分布,并引导单元的搜索。因为 MDN 的分布是一种高斯概率表分布形式,所以我们能使用似然度函数作为目标和拼接成本的损失函数:
其中 x_i 是第 i 个目标特征,μ_i 为预测均值,而 (σ_i)^2 为预测方差。在实际的成本计算中,使用负对数似然函数和移除常数项将变得更加方便,经过以上处理将简化为以下简单的损失函数:
其中 w_i 为特征权重。
当我们考虑自然语言时,这种方法的优势将变得非常明显。像元音那样,有时候语音特征(如话音素)相当稳定,演变也非常缓慢。而有时候又如有声语音和无声语音的转换那样变化非常迅速。考虑到这种变化性,模型需要能够根据这种变化性对参数作出调整,深度 MDN 的做法是在模型中使用嵌入方差(variances embedded)。因为预测的方差是依赖于上下文的(context-dependent),所以我们将它们视为成本的自动上下文依赖权重。这对提升合成质量是极为重要的,因为我们希望在当前上下文下计算目标成本和拼接成本:
其中 w_t 和 w_c 分别为目标和拼接成本权重。在最后的公式中,目标成本旨在确保合成语音(语调和音长)中再现音韵。而拼接成本确保了流畅的音韵和平滑的拼接。
在使用深度 MDN 对单元的总成本进行评分后,我们执行了一种传统的维特比搜索(Viterbi search)以寻找单元的最佳路径。然后,我们使用波形相似重叠相加算法(waveform similarity overlap-add/WSOLA)找出最佳拼接时刻,因此生成平滑且连续合成语音。
-
CES热门技术:语音识别2012-02-06 3912
-
苹果手机Siri背后隐藏的恐怖,细思极恐!2017-03-17 21797
-
智能语音助手难敌口音 谷歌Home与Siri谁靠谱2017-05-23 2370
-
【NXP LPC54110试用申请】学习语音识别与处理2017-07-13 2723
-
苹果将把Siri与Salesforce整合2018-10-14 3434
-
语音合成技术简介,深度学习技术对合成技术发展的影响2018-10-18 10276
-
Siri经历了什么样的演变2019-06-21 4774
-
苹果新发布论文来阐释语音助手的设计想法2020-02-12 1240
-
苹果新论文发布,揭示了Siri语音技术的秘密2020-04-24 1412
-
VOI611嵌入式深度学习语音识别芯片的数据手册免费下载2021-03-26 1531
-
苹果Siri语音助手将迎来重磅升级?ChatGPT带动下,AI技术应用加速!2023-04-29 5317
-
基于深度学习的语音合成技术的进展与未来趋势2023-09-16 2487
-
深度学习在语音识别中的应用及挑战2023-10-10 1865
-
语音合成技术在智能驾驶中的创新与应用2024-02-01 1628
-
苹果iOS 18.2公测版发布,Siri与ChatGPT深度融合2024-11-07 2171
全部0条评论

快来发表一下你的评论吧 !
