

TensorFlow的框架结构解析
人工智能
描述
TensorFlow是谷歌的第二代开源的人工智能学习系统,是用来实现神经网络的内置框架学习软件库。目前,TensorFlow机器学习已经成为了一个研究热点。由基本的机器学习算法入手,简析机器学习算法与TensorFlow框架,并通过在Linux系统下搭建环境,仿真手写字符识别的TensorFlow模型,实现手写字符的识别,从而实现TensorFlow机器学习框架的学习与应用。
机器学习是一门多领域交叉的学科,能够实现计算机模拟或者实现人类的学习行为,重构自己的知识结构从而改善自身的性能。2016年初,AlphaGo以大比分战胜李世石,AI的概念从此进入人们的视野,而机器学习就是AI的核心,是使计算机具有智能的根本途径。TensorFlow是谷歌的第二代人工智能学习系统,是用来制作AlphaGo的一个开源的深度学习系统。
1机器学习
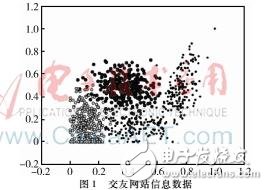
可以举一个简单的例子来说明机器学习的概念,使用k近邻算法改进交友网站的配对效果[1]。比如说你现在想要在交友网站上认识一个朋友,而交友网站上拥有每个注册用户的两个信息(玩视频游戏所耗时间的百分比和每年获取的飞行常客里程数),你想知道你会对哪些人比较感兴趣,这时候就可以使用机器学习算法建立一个简单的模型。可以将一些自己认为有魅力的人、魅力一般的人、不喜欢的人的这两个信息(玩视频游戏所耗时间的百分比和每年获取的飞行常客里程数)输入机器学习算法建立一个模型,如图1所示。当你想知道一个用户是不是你感兴趣交友的人时,输入信息,计算机通过这个模型进行计算,可以给你一个预测答案,这就是一种经典的监督学习算法。
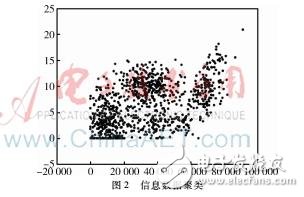
机器学习算法有很多种类,上述例子说明的监督学习算法只是其中的一类。如果换种方式去实现这个结果,你有一堆如上的数据,但是并不对这些数据进行分类,让算法按照数据的分散方式来观察这些数据,发现数据形成了一些聚类,如图2所示,而通过这种方法,能够把这些数据自动地分类,这就是一种无监督学习算法。
机器学习的算法有很多,再比如用学习型算法来判断你需要多少训练信息,用什么样的更好的近似函数能够反映数据之间的关系,使得用最少的训练信息获得更准确的判断。
机器学习就是当机器想要完成一个任务,通过它不断地积累经验,来逐渐更好、差错减少地完成一个任务。
2TensorFlow的框架
2.1TensorFlow输入张量
TensorFlow的命名来源于本身的运行原理。Tensor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算。用MNIST机器学习[23]这个例子来解释一个用于预测图片里面的数字的模型。
首先要先获得一个MNIST数据集,如图3所示,这个数据集能够在TensorFlow官网上进行下载。每一个MNIST数据单元由一张包含手写数字的图片和一个对应的标签两部分组成。把这些图片设为“xs”,把这些标签设为“ys”。MNIST数据集拥有60 000行的训练数据集(mnist.train)和10 000行的测试数据集(mnist.test)。


每一张图片包含28×28个像素点。可以用一个数字数组来表示这张图片:把这个数组展开成一个向量,长度是784。在MNIST训练数据集中,mnist.train.images(训练数集中的图片)是一个 [60 000, 784] 的张量,如图4所示,第一个维度数字用来对应每张图片,第二个维度数字用来索引每张图片中的像素点。在此张量里的每一个元素,都表示为某张图片里的某个像素的介于0和1之间的强度值。
相对应的标签是从0到9的数字,用来描述给定图片里表示的数字。每个数字对应着相应位置1,如标签0表示为[1,0,0,0,0,0,0,0,0,0],因此mnist.train.labels是一个 [60 000, 10] 的数字矩阵,如图5所示。
如上述的这两个数组都是二维数组,都是TensorFlow中的张量数据[4],而这些数据就以流的形式进入数据运算的各个节点。而以机器算法为核心所构造的模型就是数据流动的场所。TensorFlow就是一个是文件库,研究人员和计算机科学家能够借助这个文件库打造分析图像和语音等数据的系统,计算机在此类系统的帮助下,将能够自行作出决定,从而变得更加智能。
2.2TensorFlow代码框架
TensorFlow是一个非常灵活的框架,它能够运行在个人计算机或者服务器的单个或多个CPU和GPU上,甚至是移动设备上。
可以从上面举例的MNIST机器学习来分析TensorFlow的框架。首先,要构建一个计算的过程。MNIST所用到的算法核心就是softmax回归算法,这个算法就是通过对已知训练数据同个标签的像素加权平均,来构建出每个标签在不同像素点上的权值,若是这个像素点具有有利的证据说明这张图片不属于这类,那么相应的权值为负数,相反若是这个像素拥有有利的证据支持这张图片属于这个类,那么权值是正数。
因为输入往往会带有一些无关的干扰量,于是加入一个额外的偏置量(bias)。因此对于给定的输入图片x它代表的是数字i的证据,可以表示为:
evidencei=∑jWi,jxj+bi(1)
其中Wi,j表示权值的矩阵,xj为给定图片的像素点,bi代表数字i类的偏置量。
在这里不给出详细的推导过程,但是可以得到一个计算出一个图片对应每个标签的概率大小的计算方式,可以通过如下的代码来得到一个概率分布:
y=softmax(Wx+b)(2)
建立好一个算法模型之后,算法内输入的所有可操作的交互单元就像式(2)中的图片输入x,为了适应所有的图片输入,将其设置为变量占位符placeholder。而像权重W和偏置值b这两个通过学习不断修改值的单元设置为变量Variable。
train_step=tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
TensorFlow在这一步就是在后台给描述计算的那张图里面增添一系列新的计算操作单元用来实现反向传播算法和梯度下降算法。它返回一个单一的操作,当运行这个操作时,可以用梯度下降算法来训练模型,微调变量,不断减少成本,从而建立好一个基本模型。
建立好模型之后,创建一个会话(Session),循环1 000次,每次批处理100个数据,开始数据训练,代码如下:
sess= tf.InteractiveSession()
for i in range(1000):
batch_xs,batch_ys=mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
TensorFlow通过数据输入(Feeds)将张量数据输入至模型中,而张量Tensor就像数据流一样流过每个计算节点,微调变量,使得模型更加准确。
通过这个例子,可以管中窥豹了解TensorFlow的框架结构,TensorFlow对于输入的计算过程在后台描述成计算图,计算图建立好之后,创建会话Session来提交计算图,用Feed输入训练的张量数据,TensorFlow通过在后台增加计算操作单元用于训练模型,微调数据,从而完成一个机器的学习任务[5]。
- 相关推荐
- 热点推荐
- 人工智能
- 机器学习
- tensorflow
-
扬杰科技推出基于GPP芯片和框架结构的带散热片PB系列整流桥产品2020-07-23 2384
-
hadoop框架结构的说明介绍2018-10-15 3415
-
深度学习框架TensorFlow&TensorFlow-GPU详解2018-12-25 4299
-
请问数据驱动的自动化测试框架结构是怎么构成的?2021-04-15 2167
-
RK3399图显系统的软件框架结构是怎样的?2022-03-07 1552
-
嵌入式系统中的USB控制器与框架结构2009-05-06 1909
-
TensorFlow实战之深度学习框架的对比2017-11-16 5368
-
机器学习框架Tensorflow 2.0的这些新设计你了解多少2018-11-17 3808
-
国产框架超越 PyTorch 和 TensorFlow?2021-04-09 3401
-
Tensorflow Lite 使用与优化2022-01-25 659
-
常规自动化程序框架结构2022-02-22 869
-
深度学习框架PyTorch和TensorFlow如何选择2023-02-02 1587
-
深度学习框架tensorflow介绍2023-08-17 3736
-
TensorFlow与PyTorch深度学习框架的比较与选择2024-07-02 2833
-
汽车框架结构焊接技术探析2025-02-27 869
全部0条评论

快来发表一下你的评论吧 !
