

学习模型指导驾驶过程分为五步
汽车电子
描述
与人类用双眼去观察路面、用手去操控方向盘类似,无人车用一排摄像机去感知环境,用深度学习模型指导驾驶。大体来说,这个过程分为五步:
记录环境数据
分析并处理数据
构建理解环境的模型
训练模型
精炼出可以随时间改进的模型
如果你想了解无人车的原理,那这篇文章不容错过。
记录环境数据
一辆无人车首先需要具备记录环境数据的能力。
具体来说,我们的目标是得到左右转向角度的均匀分布。这倒也不难操作,可以以顺时针和逆时针方向在测试场地内绕圈的方式实现。这种训练有助于减少转向偏差,避免长时间驾驶后汽车从道路一边慢慢漂移到道路另一边的尴尬情境。
此外,以慢速(例如每小时10英里)行驶也有助于在转弯时记录平滑的转向角,在这里驾驶行为被分类为:
直线行驶:0<=X<0.2
小转弯:0.2<=X<0.4
急转:X>=0.4
恢复到中心
其中,X为转向角,r为旋转半径(单位为米),计算转向角的公式为X=1/r。上面提到的“恢复到中心”在数据记录过程中很重要,它帮助车辆学会在即将撞上,马路崖子时回到车道中心。这些记录数据保存在driving_log.csv中,其中每一行都包含:
文件路径到镜头前中央相机图像
文件路径到前左相机图像
文件路径到前右相机图像
转向角
在记录环境数据的过程中,我们需要记录约100000个转向角的图像,以便提供足够的数据训练模型,避免因样本数据不足导致的过拟合。通过在数据记录过程中定期绘制转向角直方图,可以检查转向角是否为对称分布。
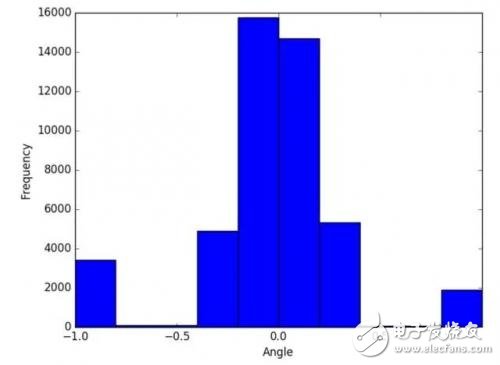
分析处理数据
第二步是为构建模型分析和准备刚刚记录的数据,此时的目标是为模型生成更多的训练样本。
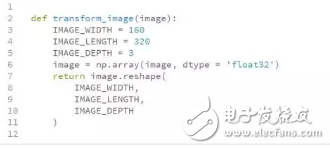
下面这张图片由前中央相机拍摄,分辨率为320*160像素,包含红色、绿色和蓝色的channel。在Python中,可以将其表示为一个三维数组,其中每个像素值的范围在0到255之间。
司机视线以下的区域和两边的车道标志一直是自动驾驶技术中研究的重点。这两部分可以使用Keras中的Cropping2D裁剪图像,减少输入到模型中的噪声。
我们可以用开源的计算机视觉库OpenCV从文件中读取图像,然后沿垂直轴翻转,生成一个新的样本。
OpenCV非常适合自动驾驶汽车用例,因为它是用C++语言编写的。像倾斜和旋转这样的其他图像增强技术,也有助于产生更多的训练样本。
此外,还需要通过乘以-1.0翻转其转向角。
之后,可以用Numpy开源库将图像重新塑造成一个三维数组,方便下一步的建模。
构建理解环境的模型
图像数据搞定后,我们需要为无人车构建理解环境信息的深度学习模型,从记录的图像中提取特征。
具体来说,我们的目标是将包含153600像素的输入图像映射到包含单个浮点值的输出。英伟达之前提出的模型的每一层都提供了特定的功能,作为基础架构效果应该不错。
英伟达模型相关论文地址:https://arxiv.org/pdf/1604.07316v1.pdf
之后,我们需要将三维数组规范化为单位长度,防止模型中较大的值偏差。注意我们将其除以255.0,因为这是一个像素的最大可能值。
还要适当减少人类视野以下的车前场景和车前上方图像的像素,以减少噪音。
之后,我们需要将车道标记等三维数组进行卷积,提取关键特征,这些信息对于预测转向角至关重要。

我们想让开发的模型能够驾驭任何道路类型,因此需要用dropout减少过拟合。
最后,我们需要将转向角输出为float。
-
汽车驾驶员操作特性考核仿真系统的研究2009-12-02 2468
-
汽车驾驶过程图片处理,求指导2016-01-07 4468
-
无人驾驶电子与安全2017-02-22 4933
-
什么是驾驶员监控系统?2019-09-16 9135
-
电路(第五版)学习指导与习题分析.邱关源_罗先觉2016-08-08 2553
-
无人车学会开车的原理和过程分析2018-01-06 6436
-
自动驾驶科普:无人车能够上路的五个过程详解2018-07-16 3477
-
基于驾驶过程注意力的问题设计全新的超宽显示屏应用的八大原则2019-03-19 1575
-
电路习题第五版学习指导与习题分析下载2020-12-21 1694
-
基于深度学习的疲劳驾驶检测算法及模型2021-03-30 1680
-
基于迁移学习的驾驶分心行为识别模型2021-04-30 1441
-
慕课嵌入式开发及应用(第五章.进一步学习指导)2021-11-03 1020
-
电路学习指导与习题分析2022-04-18 949
-
深度学习模型训练过程详解2024-07-01 4809
-
强化学习会让自动驾驶模型学习更快吗?2026-01-31 1080
全部0条评论

快来发表一下你的评论吧 !
