

手机芯片带宽性能的影响因素有哪些,优化测试方向方法详解
控制/MCU
描述
手机的带宽吞吐性能是影响手机总体性能的一个重要指标,目前几乎所有第三方的手机评测软件都有对这一项指标的单独测试。但这些测试基本上都存在一些问题,并不能全面真实地反映手机的带宽吞吐性能。文章从硬件的角度深入分析了CPU、Cache、DDR等模块的实现方式对带宽测试软件的影响,并结合最常用的ARM系列CPU做了对比,最后提出了新的带宽吞吐性能评价方式。
0引言
随着智能手机的快速普及,2015年全球的出货量已达14亿台。这其中大半部分都是Android系统的手机,它们的核心操作系统基本一样,但硬件平台就各有不同了。对手机硬件性能的评测成为了业界以及用户所关注的重点。相应的,第三方的手机测评软件就应运而生了。这些测评软件往往将纷繁复杂的各项硬件性能转化为一个个清晰明了的数字,让消费者以最直观的方式了解一部手机的性能水平。由于其使用的简便性和直观性,不光是手机的最终消费者经常使用它作为手机选择的参考,不少方案厂商也利用这些测评软件作为手机芯片选择的依据。
现代的手机主控芯片都是多核系统,运算能力越来越强,但内存性能却提升有限。因此内存性能往往成为系统性能的瓶颈,对内存带宽吞吐性能的测试也显得尤为重要。本文将分析目前带宽性能测试软件的一些局限性,结合硬件设计探讨影响带宽性能测试的因素,最后提出对带宽性能测试优化的方向。
1 CPU测试带宽的局限性
手机的主控芯片是个复杂的SoC(System on Chip),有多个主设备可以访问DDR(内存),DDR控制器的复杂程度也越来越高,它可以协调均衡各个主设备的访问。但除了CPU,其他的主设备第三方用户是不方便直接用软件来控制的,如视频编解码模块,这些模块都需要专门的驱动程序来控制,而驱动程序都是由硬件厂商提供,第三方用户不了解其中的细节。因此一般是利用统计CPU访问DDR的速度来评估芯片总的带宽吞吐性能。这就带来一个问题,可能CPU全速运行测试程序所需要的带宽也达不到DDR能提供的理论带宽,这时带宽吞吐性能受限于CPU发读写命令的能力,而不是受限于DDR。
例如,以ARM cortexA9 CPU做仿真实验,在CPU访存接口上挂一个理想的32位DDR模型(有访问请求立即响应,没有延时),CPU频率为1 008 MHz时,测得数据拷贝带宽为2 140 MB/s。而手机上一般会配置540 MHz 32位DDR,能提供的理论带宽为4 320 MB/s,已经远超cortex-A9的带宽吞吐能力了,这种情况下带宽性能测试得到的只是CPU的访存性能,而不是DDR的总体带宽性能。
2 Cache对带宽吞吐测试的影响
现在的带宽吞吐性能评测软件都是利用统计CPU访问DDR的速度来评估芯片总的带宽吞吐性能,这就需要考虑CPU Cache的影响。
为了加快访问数据的速度,现代多核处理器通常包含私有缓存(L1 Cache)和末级共享缓存(L2 Cache)[3]。L1 Cache大小通常有几十KB,L2 Cache通常有数百KB到几MB。CPU对数据的访问都会经过Cache再到DDR。不同的Cache行为实现会导致CPU对DDR访问量的巨大差异。
目前手机主控芯片几乎都是采用ARM Cortex系列的CPU,下面就以ARM cortex系列最常用的CPU(A5,A7,A9,A53)来分析不同的Cache配置对CPU访存性能的影响。
2.1对连续地址的写操作
CPU对连续地址的写入速度是反映带宽性能的重要指标,软件上对应memset操作,用C语言描述如下:
int *dst;
for(int i=0;i
*dst= value
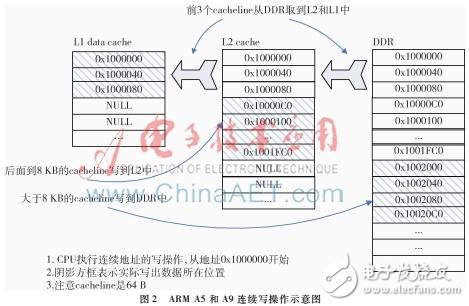
实际上由于Cache的存在,数值并不是直接写到DDR中。对于ARM cortexA5和cortexA9 CPU,这一过程如图1所示。
L1 data Cache一般都配置为write back + write allocate。但ARM对所有系列CPU的L1 Cache都做了优化:检测到连续地址3次Cache line的write操作,即自动切换为write through + write no allocate。所以可以看到在图中L1 data Cache只有前3个Cache line(0x1000000~0x1000040)的数据从DDR中读取出来了,后面的数据就直接写入L2 Cache了。
CortexA5和cortexA9的L2 Cache 依然是write back+write allocate。但没有类似于L1 Cache那样的自动切换到write through + write no allocate的机制。所以每次从L1 data Cache有数据写到L2 Cache,都应该从DDR中读取相应地址的一个Cache line大小的数据分配到L2 Cache中,再对这个分配好的Cache line做写操作。但实际上由于L1 data Cache每次对L2 Cache的写操作都是一个Cache line的大小,即整个Cache line都被重写了,因此也不用关心DDR中对应这个Cache line地址的数据是什么了。这里L2 Cache就直接分配了一个Cache line来存放L1 data Cache写过来的数据,没有再去读DDR。
ARM cortexA7和cortexA53的情况又有所不同,如图2。
CortexA7和cortexA53的L1 data Cache 实现机制与前面一样,但L2 Cache的实现不同。虽然同样是write back + write allocate,但其有个自动检测机制,检测到连续地址的127次Cache line的write操作可以自动切换到write through+write no allocate。如图2所示,地址0x1002000之后的数据就直接写到DDR中了。
根据上面的分析,对于CPU向外写数据的操作,在小于一定大小的情况下,实际上并不会操作DDR,而是在操作L2 Cache。表1是两款手机CPU 同频下的memset性能对比,它们的CPU分别使用了ARM cortexA7和cortexA9。

从表中数据可以看出,在size小于10 KB时,cortexA9性能好于cortexA7,此时都是对L2 Cache的访问,性能决定于CPU的指令发射能力以及流水线的乱序执行能力,这些能力cortexA9都强于cortexA7。在10 KB100 KB时,cortexA9的性能逐渐被cortexA7反超,因为此时cortexA9也开始有访问DDR的操作了,size越大访问DDR占比越大,最后几乎完全是对DDR的访问了。这时性能主要由DDR的性能决定。
2.2对连续地址的读操作
CPU对连续地址的读取速度也是反映带宽性能的重要指标,可用C语言描述如下:
int *src;
for(int i=0;i
value = *(src + i);
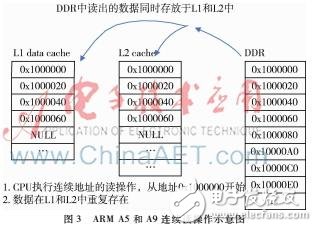
cortexA5和cortex-A9的L2 Cache是非exclusive模式,即L1不命中时,从DDR读取回来的Cache line会保存在L2 Cache中。如图3。
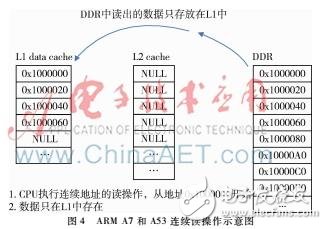
CortexA7和cortexA53的L2 Cache是exclusive模式,即L1不命中时,从DDR读取回来的Cache line不会保存在L2 Cache中。只有当被改写过的Cache line从L1 Cache刷出来时才会存到L2 Cache中。如图4。
以上两种实现方式各有利弊。做重复读取性能测试时,如果数据量小于L1 data Cache size,exclusive模式和非exclusive模式性能相当。当数据量大于L1 data Cache size,且小于L2 Cache size时,非exclusive模式性能较好。当数据量大于L2 Cache size时,exclusive模式性能略好,如果除了读操作还有其他的写操作,那么exclusive模式性能优势就更明显了,因为这种模式下读操作占用了较少的L2 Cache,可以分配给其他操作使用。
-
手机芯片好坏对手机有什么影响2024-02-19 7151
-
5G手机芯片排名2023-09-01 11241
-
黑莓CPU:88CP930M-BGR1手机芯片测试架2011-03-11 0
-
长期收购手机芯片2020-12-07 0
-
高价收购手机芯片 长期回收手机芯片2021-12-03 0
-
本土手机芯片痛在哪2014-03-26 1550
-
测试手机芯片带宽性能及优化测试方法2018-01-02 12445
-
什么是手机芯片 2021年手机芯片性能排行榜网2021-12-08 12813
-
手机芯片是什么 手机芯片的价格2021-12-10 12803
-
手机芯片的作用2021-12-20 14300
-
全球手机芯片性能排行表2022-01-02 33933
-
手机芯片什么组成2021-12-30 13942
-
手机芯片由什么物质组成2022-01-04 11698
-
各大手机芯片的性能排名是怎样的2022-01-05 9625
-
手机芯片的历史与发展2024-09-20 3738
全部0条评论

快来发表一下你的评论吧 !
