

存储对计算机系统会产生哪些影响
存储技术
描述
最近工作中,经历了很多项目问题的调试,把这些问题归总起来,其中和存储有关的,独占一半。而存储对计算机系统造成的影响又可分为两块:一是系统功能的稳健性;二是程序的执行效率。
存储器结构
1.1 存储器层次结构
由于访问速度、成本、功耗等指标的制约,计算机系统中的存储往往不是作为一个单一的大块存在,而是被设置成一个多级的层次结构。作为一个程序员,需要理解存储器层次结构,因为它对应用程序的性能有着巨大的影响。
图1中展示了一个典型 计算机系统的存储层级结构。和金字塔模型很像,越靠近金字塔顶端的存储器,离CPU越近,访问更便利且访问速度快,但同时它们的容量也越来越小;反之越靠近底层,存储容量越大,访问速度却越来越慢。
最高层的L0,是CPU寄存器,CPU可以在一个时钟周期内访问他们;接下来是一个或多个小型到中型的基于SRAM的高速缓存存储器,可以在几个CPU时钟周期内访问它们;然后是一个大的基于DRAM的主存,可以在几十到几百个时钟周期内访问它们;接下来是慢速但容量很大的本地磁盘;最后,甚至有些系统会通过网络访问其远程服务器上的磁盘。
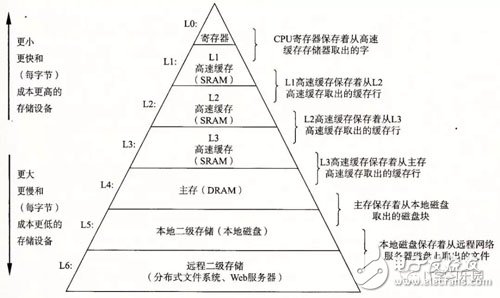
图1 存储器层次结构
高速缓存可以存在一级或多级,甚至不存在于一些低性能的单片机中。TI C64X架构中设计有2级的高速缓存,其数据和代码的存取机制在本订阅号之前的文章“TI C6000 数据存储处理与性能优化”中有过描述。
1.2 存储器的访问
一个编写良好的计算机程序常常具有良好的局部性(locality)。
局部性通常有两种不同的形式:时间局部性和空间局部性。
时间局部性:在一个具有良好时间局部性的程序中,被访问过一次的内存位置很可能在不远的将来再被多次访问 。
空间局部性:在一个具有良好空间局部性的程序中,如果一个内存位置被访问 了一次,那么程序很可能在不远的将来访问 附近的一个内存位置。
例如对一个二维数组求和:
for (i=0; i《M; i++)
for(j=0; j《N; j++)
sum += data_tab[i][j];
其中,sum在循环迭代中被多次访问,它具有良好的时间局部性,但因其为标量,因此没有空间局部性。对二维数组data_tab而言,其元素在存储中顺序存储,因此有好的空间局部性,但由于其每个元素只访问一次,因此时间局部性很差。
另外,假设把上面第三行替换成:
sum += data_tab[j][i];
由于二维数组是按行依次存储,则每次循环对内存访问的步长由1变为N,空间局部性变差。像这样看上去对程序很小的改动对它的局部性有很大的影响。
存储类型
2.1 随机访问存储器(RAM)
上电使用,掉电存储内容丢失。
静态RAM(SRAM):存储单元具有双稳态特性,上电就能保持它的值,对光和电噪声等干扰不敏感。它使用晶体管多,因而密集度低,更贵,功耗更大。
动态RAM(DRAM):对每个位存储为对一个电容的充电,因漏电的原因需要不断刷新来保持存储值。
SDRAM(Synchronous DRAM):用与驱动内存控制器相同的外部时钟信号的上升沿,来作为控制信号。
DDR SDRAM(Double Data-Rate Synchronous DRAM):通过使用两个时钟沿作为控制信号,从而使DRAM的速度翻倍。它是用提高有效带宽的很小的预缓冲区的大小来划分的,如DDR(2位)、DDR2(4位)、DDR3(8位)。
表1 SRAM与DRAM性能比较


2.2 非易失性存储器
非易失性存储器,即使在关电后仍能保存着它们的信息。由于历史的原因,它们也被整体成称为ROM(Read Only Memory),但很多ROM类型是即可以读也可以写的。
PROM(Programble ROM):只能被编程一次,PROM的每个存储器单元有一种熔丝,只能用高电流熔断一次。
EPROM(Erasable Programble ROM):可擦写可编程,对它的编程是通过一种把1写入EPROM的特殊设备来完成的。
EEPROM(Electrically Erasable Programble ROM):电子可擦除,不需要一个物理上独立的编程设备,因此可以直接在芯片上编程,能被编程的次数可以达到10e5次。
闪存(flash):基于EEPROM的一类非易失性存储器。对它写数据必须先将芯片中对应的内容清空,然后再写入,也就是通常说的“先擦后写 ”。
NAND flash:对它的操作以“块 ”为基本单位,因此要修改一个字节,必须重写整个数据块。它的容量大,适合做大量数据的存储。
NOR flash:对它的操作以“字 ”为基本单位。它的容量相对较小,成本大,一般用来存储程序。
2.3 磁盘
磁盘由盘片构成,它是广为应用的保存大量数据的存储设备。不过从磁盘上读信息的时间为毫秒级,比从DRAM读慢了10万倍,比从SRAM读慢了100万倍。
栈和堆
3.1 栈(stack)
栈是一个“后进先出”的存储空间,程序运行中,代码“过程 ”涉及到的返回地址、过程参数、需要保存的寄存器信息都被压入栈中,过程中声明的临时变量也是在栈中开辟存储。
过程的形式多样:函数、方法、子例程、中断处理函数等。当过程需要的存储空间超出寄存器能够存放的大小时,就会在栈上分配空间,这部分空间称为过程的栈帧。
通常,栈底位于高地址,随着数据的压入,栈向低地址方向增长,而栈指针指向栈顶。将栈指针减少一个适当的量,可以为没有指定初始值的数据,在栈上分配空间;类似的,可以通过增加栈指针来释放空间。因为栈的位置取决于.stack段分配在什么地方,所以栈的实际地址是在连接时决定的。
假设过程P调用过程Q时,相关的控制和数据信息添加到栈尾,当Q返回时,这些信息会释放掉。如果存在多级调用(包括递归调用),较早的栈帧也会累积下来,直到它对应的过程结束。

图2 通用的栈帧结构
栈空间的大小可以在链接命令文件中,使用-stack选项进行设定。在对TI C64X架构芯片进行编程时,如果用户没有自己设定,系统默认栈的尺寸为1KB。注意:编译器在编译期间和运行期间都不进行对栈溢出的检查,因此对栈空间的管理上需格外小心。
3.2 堆(heap)
堆是用于动态内存分配的一个存储区域,动态分配的对象不是可直接寻址的,它们总是用指针来访问。动态内存分配器将堆视为一组不同大小的块的集合来维护。每个块就是一个连续的虚拟内存片,要么是已分配的,要么是空闲的。一个已分配的块保持已分配状态,直到他被释放,这种释放要么是应用程序显式执行的,要么是内存分配器自身隐式执行的。
C标准库提供一个称为malloc程序包的显式分配器,程序通过调用malloc函数来从堆中分配块。malloc函数返回一个指针,指向大小至少为size字节的内存块,这个块会为可能包含在这个块内的任何数据对象类型做对齐。与malloc相对应的是free程序包,用于释放已分配的内存块。
下图直接截取深入理解计算机系统这本书中,用一个16字的小堆来展示的malloc和free是如何管理堆空间的:


程序使用动态内存分配的最重要原因是,经常直到程序实际运行时才知道某些数据结构的大小。
堆位于段.sysmem中,可分配动态存储池的大小,仅仅受限于系统中实际的存储容量。 堆空间的大小可以在链接命令文件中,使用-heap选项进行设定。在对TI C64X架构芯片进行编程时,如果用户没有自己设定,系统默认堆的尺寸为1KB。
C编程中常见的与内存有关的错误
在我们项目的调试中,死机现象被认为是最让人头疼的问题,因为这类问题往往很难复现,而即便是找到了复现的规律,也很难通过跟踪调试来断定问题所属的区域。由软件造成死机的因素,可大致分为两类:内存操作错误和线程阻塞。
线程阻塞也有很多表现方式,如高优先级线程堆积、程序陷入异常处理流程、死循环等等。所幸的是,线程阻塞要么很好复现,要么被追踪到一次就能立马找出症结所在,可面对内存错误造成的死机就不那么容易解决了。《深入理解计算机系统》这本书中也讲到:与内存有关的错误,属于那些最令人惊恐的错误,因为他们在时间和空间上,经常在举措无缘一段距离之后才表现出来,将错误的数据选择错误的位置,你的程序可能在最终失败之前运行了好几个小时,其实程序终止的位置距离处的位置已经很远了。
内存操作错误为什么会造成死机?举个简单的类比:一套性能完整的代码就好比是一幢设计建造完好的房子,而内存操作错误就像是突然拆除或篡改了支撑房屋结构或运转的关键部位,这一突发错误完全超出设计意料之外,引发一连串的恶果也就在所难免。下面是一些常见的内存错误操作的例子(真实的情况远不止这些,更多情况可参考《深入理解计算机系统》这本书):
4.1 数组越界
int data_tab[100];
int i;
for(i=0; i《=100; i++)
{
data_tab[i] = i;
}
这个例子中data_tab占100个int型长度,但循环却进行了101次。C对于数组应用不进行任何边界检查,而且局部变量和状态信息(例如保存的寄存器值和返回地址)存放在栈中,这两种情况结合到一起就能导致严重的程序错误,对越界数组元素的写操作,会破坏存储在栈中的状态信息。
另一种情况是data_tab[]是全局数组,这样的越界将引起对数组尾部其它存储内容的修改,倘若被篡改的存储区域刚好涉及到代码的关键流程判断,意味着异常流程的出现。
4.2 间接引用坏指针
scanf(“%d”, &val);
错误写成:
scanf(“%d”, val);
在这种情况下,scanf将val的内容解释为一个地址,并试图将一个字节写到这个位置。在最好的情况下,程序立即异常终止,在最糟糕的情况下,val的内容对应于内存的某个合法的读写区域,于是我们就覆盖了这块内存,就通常会在相当长的一段时间以后,造成灾难性的令人困惑的后果。
4.3 误解指针运算
int *search(int *p, int val)
{
while(*p && *p != val)
p += sizeof(int) // should be p++
return p;
}
这种错误是忘记了指针的算术操作是以它指向的对象的大小为单位来进行的。假设这里int占四个字节,原本扫描每个int变成了每四个int扫描一次。
4.4 引用不存在的变量
int *stackref()
{
int val;
int *p;
p = &val;
return p;
}
这个函数返回一个指针,指向栈里的一个局部变量。尽管p仍指向一个合法的内存地址,是它已经不再指向一个合法的变量了。要知道,局部变量val在函数返回时,将会被释掉。
4.5 引用空闲堆块中的数据
int *heapref()
{
int *x, *y;
x = (int *)malloc(sizeof(int));
。。。
free(x);
y = x;
。。。
return y;
}
这里y错误的引用已经被释放的堆块的数据和指针x。申请的堆块一旦被释放,虽然之前指向该堆块的指针x并没有变化,但它指向的区域数据已经不再有效了。
4.6 引起内存泄漏
void leak(int n)
{
x = (int *)malloc(n*sizeof(int));
return;
}
这个函数中分配了一个堆块,但没释放就返回。如果经常调用leak,那么渐渐的堆里就会充满了垃圾,最糟糕的情况下会占用整个内存地址空间。内存泄漏是缓慢、隐性的杀手。
-
计算机系统结构2014-05-09 3088
-
深入理解计算机系统之虚拟存储器讲解2019-06-25 1753
-
什么是计算机系统、计算机硬件和计算机软件?2021-07-22 2375
-
什么是计算机系统?硬件和软件哪个更重要?2021-07-26 1914
-
计算机系统中的软件系统2021-09-13 1957
-
嵌入式计算机系统概述2021-12-22 1731
-
详解单芯片微型计算机系统2022-01-19 2008
-
计算机系统概论2009-04-11 1095
-
基于EDA平台的计算机系统结构课程实践2009-12-05 668
-
微型计算机系统2010-03-03 798
-
什么是计算机系统的容错性2010-01-08 1793
-
浅析计算机系统的组成2023-05-09 2344
-
计算机系统由什么两部分组成 计算机系统的层次结构2024-02-01 6597
-
计算机系统的组成和功能2024-07-24 4150
-
存储器在微型计算机系统中的作用2024-08-22 5355
全部0条评论

快来发表一下你的评论吧 !
