

浅谈鳍式场效晶体管( finFET)寄生提取的复杂性和不确定性
嵌入式设计应用
描述
鳍式场效晶体管(简称 finFET)的推出标志着 CMOS 晶体管首次被看作是真正的三维器件。由于源漏区以及与其周围连接的三维结构方式(包括本地互连和接触通孔),导致了复杂性和不确定性。
结果,器件建模不得不快速改进。UC Berkeley Device Group 的 BSIM Group开发出了一种名为BSIM-CMG(通用多栅极)的模型,用以表示存在于 finFET内部的电阻和电容。为了帮助缓解有关向finFET工艺转变的担忧,晶圆厂做了非常大的努力来提供器件和寄生精度数据,以及保存用于先前工艺的使用模型。
虽然我们有BSIM-CMG作为表示finFET设计参数的通用方式,但各个晶圆厂会增加或减少标准模型的组件,以便能够更准确地代表其周围的寄生效应。这种定制化受到多方面的推动, 包括各家晶圆厂使用各自的器件和寄生参数模型来与硅验证结果匹配,以及使用电子设计自动化(EDA)工具来预测硅片上的结果。
此外,在高级工艺节点,晶圆厂希望他们的工艺、他们使用科学的场解算器(field solver )为这些工艺建立的“黄金(1340.40, -1.60, -0.12%)”模型以及EDA厂商开发并且被设计人员用于该领域的提取工具的输出结果之间拥有更紧密的联系。在28纳米节点,晶圆厂希望商用提取工具的误差率保持在标准模型的5-10%以内。对于 finFET 工艺,晶圆厂要求平均准确度误差保持在标准模型的2%以内,三西格玛标准偏差仅为6-7%。
由于FinFET相互作用的复杂性,要想满足晶圆厂对于EDA厂商的寄生提取工具和晶圆厂的标准模型结果一致性的要求,三维场解算器(3d field solver)必不可少。设计人员将首次能够看到场解算器(field solver)结果,而这直到目前为止主要用于工艺特性鉴定,而非设计。所幸的是,该使用模型在进行寄生提取时不会发生变化,因为这些工具将自动在场解算器和启发式方法之间转换。
传统上来说,场解算器(field solver)用于生产是不切实际的,因为它们需要太多的运算时间(也就是太慢)。在明导,我们开发出了Calibre“xACT3D”提取工具来解决这一问题。由于采用自适应网格技术来加速计算,该工具的速度要快上一个数量级或更多。它还拥有一个可扩展架构,能在现代化的计算环境中充分利用多个 CPU。因此,它能够轻松的在一个32位CPU的机器上对一个版图设计执行场解算器(field solver)计算方案,这些版图设计包括小到一些小的单元(cell),大到拥有数百万个晶体管的大模块。
然而,对于全芯片而言,我们需要处理数十亿晶体管的设计,还包括顶层的数千万条导线(nets)。从周转时间角度来看,仅仅使用快速场解算器是不切实际的。我们需要智能技巧和启发式方法,首先针对复杂结构运用场解算器(field solver)技巧,然后再针对普通的几何图形改用查找表的方式。对高层次中的绕线转换到查找表法是可行的,因为在布线网格中进行电场建模与在之前节点中看到的相似。事实上,第一代 finFET器件使用的是晶圆厂在平面工艺中采用的20纳米互连法。
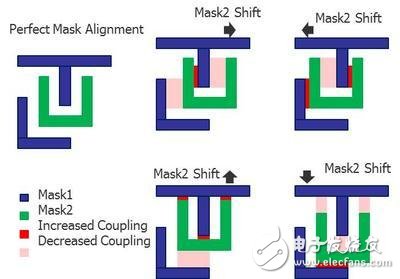
图1:双重成像(DP)的光罩可能存在的未对准情况要求设计人员评估更多寄生参数提取的corners,以验证集成电路的时间选择和性能。
考虑顶级互连提取时,我们需要更高效的计算方法,因为必须计算的寄生参数有所增加。此外,鉴于双重成像(DP)和多重成像(MP)在制造中(20纳米节点起步)发挥越来越重要的作用,互连corners的数量也将显著增多。在28纳米节点,可能存在5个互连corners,但在16纳米节点,我们会看到11至15个corners。应对计算需求增加的一个传统方法是使用更多CPU,并提升计算机core运算的可扩展性。我们正在这样做,但我们还在执行先进的multi-corner分析技术,以实现更高效的计算。过去,我们估计每增加一个corner,运行时间将增加一倍(与单个corner相比)。现在,我们可以并行处理多个corners,使每增加一个corner而增加的总体周转时间仅为10%。这意味着15个corners现在所需的运行时间仅为单个corner的2.5倍。通过采用先进的multi-corner分析以及利用更多的 CPU之间的平衡,我们可以使设计人员的周转时间与28纳米或20纳米一样甚至更短。
最近向finFET工艺的快速转变给EDA 行业带来了挑战,要求该行业真正快速地拿出应对复杂新问题的有效解决方案。还有更多工作要做,但可以说的是,与之前工艺节点开发过程中的同一阶段相比,我们现在在finFET工艺上拥有更多的EDA工具和晶圆厂的硅验证之间的对比数据。
-
科技云报到:数字化转型,从不确定性到确定性的关键路径2024-11-16 1409
-
芯片Signoff是通过什么机制去控制偏差带来的不确定性风险的?2023-06-28 4728
-
MOSFET和鳍式场效应晶体管的不同器件配置及其演变2023-02-24 13781
-
大数据分析学习的挑战:复杂性、不确定性及涌现性2022-11-17 4065
-
深部目标姿态估计的不确定性量化研究2022-04-26 1990
-
基于RFID技术的供应链管理项目存在哪些不确定性?2021-05-28 1963
-
傅里叶变换与不确定性看了就知道2020-12-30 2555
-
测试系统不确定性分析2019-09-18 1430
-
N5531S TRFL不确定性2019-02-19 1883
-
是否可以使用全双端口校准中的S11不确定性来覆盖单端口校准的不确定性?2018-12-29 2962
-
去嵌入和不确定性是否使用了正确的设置2018-09-27 3066
-
如何用不确定性解决模型问题2018-09-07 6126
-
鳍式场效晶体管集成电路设计与测试2018-05-25 6317
-
基于云模型可靠性数据不确定性评价2018-01-17 1137
全部0条评论

快来发表一下你的评论吧 !
