

利用SQL查询语句构建隐藏层的神经网络
人工智能
描述
我们熟知的SQL是一种数据库查询语句,它方便了开发者在大型数据中执行高效的操作。但本文从另一角度嵌套SQL查询语句而构建了一个简单的三层全连接网络,虽然由于语句的嵌套过深而不能高效计算,但仍然是一个非常有意思的实验。
在这篇文章中,我们将纯粹用SQL实现含有一个隐藏层(以及带 ReLU 和 softmax 激活函数)的神经网络。这些神经网络训练的步骤包含前向传播和反向传播,将在 BigQuery 的单个SQL查询语句中实现。当它在 BigQuery 中运行时,实际上我们正在成百上千台服务器上进行分布式神经网络训练。听上去很赞,对吧?
也就是说,这个有趣的项目用于测试 SQL 和 BigQuery 的限制,同时从声明性数据的角度看待神经网络训练。这个项目没有考虑任何的实际应用,不过最后我将讨论一些实际的研究意义。
我们先从一个基于神经网络的简单分类器开始。它的输入尺寸为 2,输出为二分类。我们将有一个维度为 2 的单隐层和 ReLU 激活函数。输出层的二分类将使用 softmax 函数。我们在实现网络时遵循的步骤将是在 Karpathy’s CS231n 指南(https://cs231n.github.io/neural-networks-case-study/)中展示的基于 SQL 版本的 Python 示例。
模型
该模型含有以下参数:
输入到隐藏层
W: 2×2 的权重矩阵(元素: w_00, w_01, w_10, w_11)
B: 2×1 的偏置向量(元素:b_0, b_1)
隐藏到输出层
W2: 2×2 的权重矩阵(元素: w2_00, w2_01, w2_10, w2_11)
B2: 2×1 的偏置向量(元素:b2_0, b2_1)
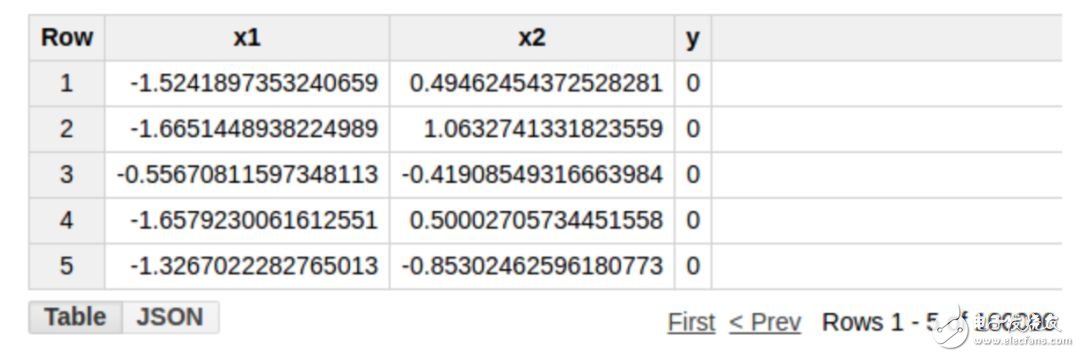
训练数据存储在 BigQuery 表格当中,列 x1 和 x2 的输入和输出如下所示(表格名称:example_project.example_dataset.example_table)
如前所述,我们将整个训练作为单个 SQL 查询语句来实现。在训练完成后,通过 SQL 查询语句将会返回参数的值。正如你可能猜到的,这将是一个层层嵌套的查询,我们将逐步构建以准备这个查询语句。我们将会从最内层的子查询开始,然后逐个增加嵌套的外层。
前向传播
首先,我们将权重参数 W 和 W2 设为服从正态分布的随机值,将权重参数 B 和 B2 设置为 0。 W 和 W2 的随机值可以通过 SQL 本身产生。为了简单起见,我们将从外部生成这些值并在 SQL 查询中使用。用于初始化参数的内部子查询如下:

请注意,表格 example_project.example_dataset.example_table 已经包含了列 x1、 x2 和 y。模型参数将会被作为上述查询结果的附加列添加。
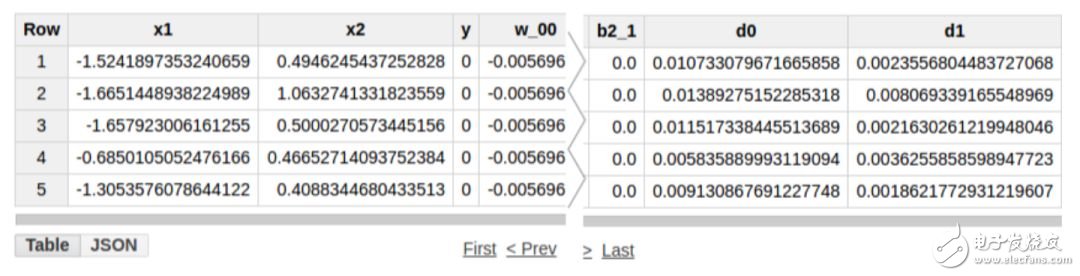
接下来,我们将计算隐藏层的激活值。我们将使用含有元素 d0 和 d1 的向量 D 表示隐藏层。我们需要执行矩阵操作 D = np.maximum(0, np.dot(X, W) + B),其中 X 表示输入向量(元素 x1 和 x2)。这个矩阵运算包括将权重 W 和输入 X 相乘,再加上偏置向量 B。然后,结果将被传递给非线性 ReLU 激活函数,该函数将会把负值设置为 0。SQL 中的等效查询为:

上面的查询将两个新列 d0 和 d1 添加到之前内部子查询的结果当中。 上述查询的输出如下所示。
这完成了从输入层到隐藏层的一次转换。现在,我们可以执行从隐藏层到输出层的转换了。
首先,我们将计算输出层的值。公式是:scores = np.dot(D, W2) + B2。然后,我们将对计算出来的值用 softmax 函数来获得每个类的预测概率。SQL 内部的等价子查询如下:

首先,我们将使用交叉熵损失函数来计算当前预测的总损失。首先,计算每个样本中正确类预测概率对数的负值。交叉熵损失只是这些 X 和 Y 实例中数值的平均值。自然对数是一个递增函数,因此,将损失函数定义为负的正确类预测概率对数很直观。如果正确类的预测概率很高,损失函数将会很低。相反,如果正确类的预测概率很低,则损失函数值将很高。
为了减少过拟合的风险,我们也将同样增加 L2 正则化。在整体损失函数中,我们将包含 0.5*reg*np.sum(W*W) + 0.5*reg*np.sum(W2*W2),其中 reg 是超参数。在损失函数中包括这一函数将会惩罚那些权重向量中较大的值。
在查询当中,我们同样会计算训练样本的数量(num_examples)。这对于后续我们计算平均值来说很有用。SQL 查询中计算整体损失函数的语句如下:

反向传播
接下来,对于反向传播,我们将计算每个参数对于损失函数的偏导数。我们使用链式法则从最后一层开始逐层计算。首先,我们将通过使用交叉熵和 softmax 函数的导数来计算 score 的梯度。与此相对的查询是:

在上文中,我们用 scores = np.dot(D, W2) + B2 算出了分数。因此,基于分数的偏导数,我们可以计算隐藏层 D 和参数 W2,B2 的梯度。对应的查询语句是:

同理,我们知道 D = np.maximum(0, np.dot(X, W) + B)。因此,通过 D 的偏导,我们可以计算出 W 和 B 的导数。我们无须计算 X 的偏导,因为它不是模型的参数,且也不必通过其它模型参数进行计算。计算 W 和 B 的偏导的查询语句如下:

最后,我们使用 W、B、W2 及 B2 各自的导数进行更新操作。计算公式是 param = learning_rate * d_param ,其中learning_rate 是参数。为了体现 L2 正则化,我们会在计算 dW 和 dW2 时加入一个正则项 reg*weight。我们也去掉如 dw_00, correct_logprobs 等缓存的列,它们曾在子查询时被创建,用于保存训练数据(x1, x2 及 y 列) 和模型参数(权重和偏置项)。对应的查询语句如下:

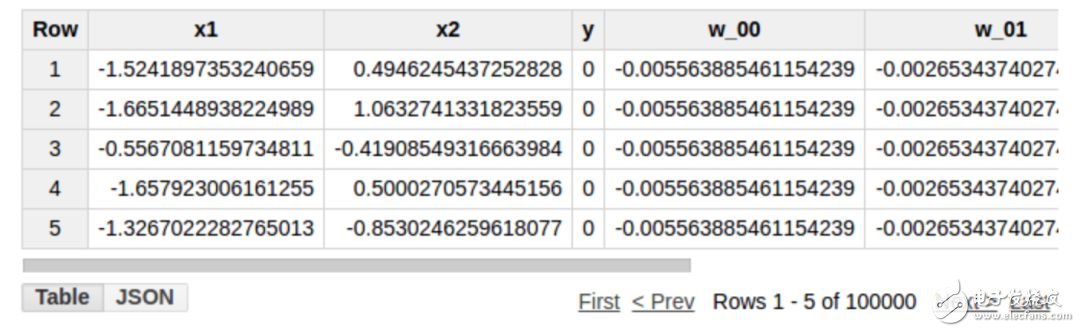
这包含了正向和反向传播的一整个迭代过程。以上查询语句将返回更新后的权重和偏置项。部分结果如下所示:
为了进行多次训练迭代,我们将反复执行上述过程。用一个简单 Python 函数足以搞定,代码链接如下:https://github.com/harisankarh/nn-sql-bq/blob/master/training.py。
因为查询语句的多重嵌套和复杂度,在 BigQuery 中执行查询时多项系统资源告急。BigQuery 的标准 SQL 扩展的缩放性比传统 SQL 语言要好。即使是标准 SQL 查询,对于有 100k 个实例的数据集,也很难执行超过 10 个迭代。因为资源的限制,我们将会使用一个简单的决策边界来评估模型,如此一来,我们就可以在少量迭代后得到较好的准确率。
我们将使用一个简单的数据集,其输入 X1、X2 服从标准正态分布。二进制输出 y 简单判断 x1 + x2 是否大于 0。为了更快的训练完 10 个迭代,我们使用一个较大的学习率 2.0(注意:这么大的学习率并不推荐实际使用,可能会导致发散)。将上述语句执行 10 个迭代得出的模型参数如下:
我们将使用 Bigquery 的函数 save to table 把结果保存到一个新表。我们现在可以在训练集上执行一次推理来比较预测值和预期值的差距。查询语句片段在以下链接中:
https://github.com/harisankarh/nn-sql-bq/blob/master/query_for_prediction.sql。
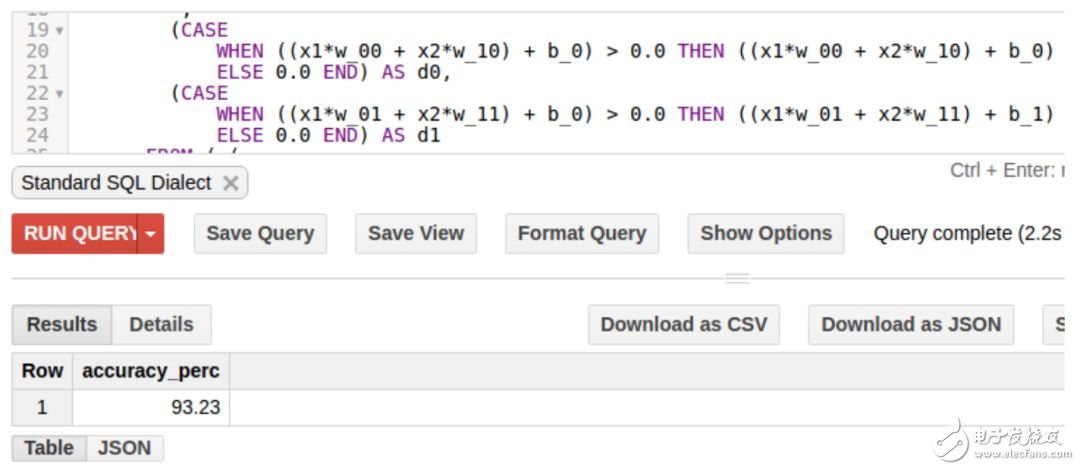
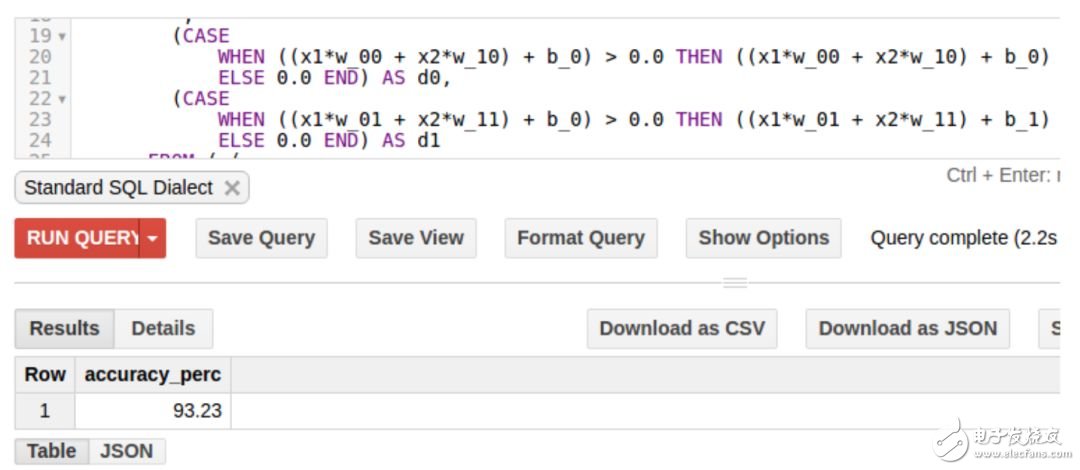
仅通过十个迭代,我们的准确率就可达 93%(测试集上也差不多)。
如果我们把迭代次数加到 100 次,准确率高达 99%。
优化
下面是对本项目的总结。我们由此获得了哪些启发?如你所见,资源瓶颈决定了数据集的大小以及迭代执行的次数。除了祈求谷歌开放资源上限,我们还有如下优化手段来解决这个问题。
创建中间表和多个 SQL 语句有助于增加迭代数。例如,前 10 次迭代的结果可以存储在一个中间表中。同一查询语句在执行下 10 次迭代时可以基于这个中间表。如此,我们就执行了 20 个迭代。这个方法可以反复使用,以应对更大的查询迭代。
相比于在每一步增加外查询,我们应该尽可能的使用函数的嵌套。例如,在一个子查询中,我们可以同时计算 scores 和 probs,而不应使用 2 层嵌套查询。
在上例中,所有的中间项都被保留直到最后一个外查询执行。其中有些项如 correct_logprobs 可以早些删除(尽管 SQL 引擎可能会自动的执行这类优化)。
多尝试应用用户自定义的函数。如果感兴趣,你可以看看这个 BigQuery 的用户自定义函数的服务模型的项目(但是,无法使用 SQL 或者 UDFs 进行训练)。
意义
现在,让我们来看看基于深度学习的分布式 SQL 引擎的深层含义。 BigQuery、Presto 这类 SQL 仓库引擎的一个局限性在于,查询操作是在 CPU 而不是 GPU 上执行的。研究 blazingdb 和 mapd 等基于 GPU 加速的数据库查询结果想必十分有趣。一个简单的研究方法就是使用分布式 SQL 引擎执行查询和数据分布,并用 GPU 加速数据库执行本地计算。
退一步来看,我们已经知道执行分布式深度学习很难。分布式 SQL 引擎在数十年内已经有了大量的研究工作,并产出如今的查询规划、数据分区、操作归置、检查点设置、多查询调度等技术。其中有些可以与分布式深度学习相结合。如果你对这些感兴趣,请看看这篇论文(https://sigmodrecord.org/publications/sigmodRecord/1606/pdfs/04_vision_Wang.pdf),该论文对分布式数据库和分布式深度学习展开了广泛的研究讨论。
-
BP神经网络与卷积神经网络的比较2025-02-12 1907
-
深度学习入门:简单神经网络的构建与实现2025-01-23 1221
-
如何构建三层bp神经网络模型2024-07-11 1818
-
PyTorch神经网络模型构建过程2024-07-10 1839
-
bp神经网络和卷积神经网络区别是什么2024-07-03 3915
-
构建神经网络模型方法有几种2024-07-02 1620
-
oracle执行sql查询语句的步骤是什么2023-12-06 2044
-
卷积神经网络层级结构 卷积神经网络的卷积层讲解2023-08-21 11085
-
如何构建神经网络?2021-07-12 2007
-
关于神经网络隐藏层节点数效率最优值实验的详细介绍2019-06-28 2014
-
AI知识科普 | 从无人相信到万人追捧的神经网络2018-06-05 3546
-
用TensorFlow写个简单的神经网络2018-03-23 5681
全部0条评论

快来发表一下你的评论吧 !
