

完整QDR-IV设计高性能网络系统详解
通信网络
描述
流媒体视频、云服务和移动数据推动了全球网络流量的持续增长。为了支持这种增长,网络系统必须提供更快的线路速率和每秒处理数百万个数据包的性能。在网络系统中,数据包的到达顺序是随机的,且每个数据包的处理需要好几个存储动作。数据包流量需要每秒钟访问数亿万次存储器,才能在转发表中找到路径或完成数据统计。
数据包速率与随机存储器访问速率成正比。如今的网络设备需要具有很高的随机访问速率(RTR)性能和高带宽才能跟上如今高速增长的网络流量。其中,RTR是衡量存储器可以执行的完全随机存储(读或写)的次数,即随机存储速率。该度量值与存取处理过程的处理位数无关。RTR是以百万次/每秒(MT/s)为单位计量的。
相比于高性能网络系统需要处理的随机流量的速率,当今高性能DRAM能够处理的要少一些。QDR-IV SRAM旨在提供同类最佳的RTR性能,以满足苛刻的网络功能要求。图1量化了QDR-IV相比于其它类型的存储器在RTR性能方面的优势。即使与最高性能的存储器相比,QDR-IV仍能提供两倍于后者的RTR性能,因此,它是那些需要执行要求苛刻的操作-如更新统计数据、跟踪数据流状态、调度数据包、进行表查询-的高性能网络系统的理想选择。
在本系列的第一部分中,我们将探讨两种类型的QDR-IV存储器、时钟、读/写操作和分组操作。
图1. QDR-IV性能对比
不同类型的QDR-IV:XP和HP
QDR-IV 有两种类型。HP在较低频率下工作,而且不使用分组操作。 XP面向最高性能的应用,可以使用分组操作方案,并在较高频率下工作。
QDR-IV的读写时延由运行速度决定。表1定义了工作模式和每个模式所支持的频率。

表1. 工作模式
QDR-IV SRAM具有两个端口,即端口A和端口B。由于可以独立访问这两个端口,所以对存储器阵列进行的任何读/写访问组合均可得到最大的随机数据传输速率。在QDR-IV中,对每个端口进行访问时需要使用双倍数据速率的通用地址总线(A)。端口A的地址在输入时钟(CK)的上升沿上被锁存,而端口B的地址在输入时钟(CK)的下降沿上或在CK#的上升沿上被锁存。控制信号(LDA#、LDB#、RWA#和RWB#)以单倍数据速率(SDR)工作,并用于确定执行读操作还是写操作。两个数据端口(DQA和DQB)均配备了双倍数据速率(DDR)接口。该器件具有2字突发的架构。器件的数据总线带宽为 × 18或 × 36。
QDR-IV SRAM包括指定为端口A和端口B的两个端口。因为对两个端口的访问是独立的,所以对于对存储器阵列的读/写访问的任何组合,随机事务速率被最大化。 对每个端口的访问是通过以双倍数据速率(即时钟的两个边沿)运行的公共地址总线(A)。 端口A的地址在输入时钟(CK)的上升沿锁存,端口B的地址在CK的下降沿或CK#的上升沿锁存。 控制信号(LDA#,LDB#,RWA#和RWB#)以单数据速率(SDR)运行,它们决定是执行读操作还是写操作。 两个数据端口(DQA和DQB)都配有双倍数据速率(DDR)接口。 该器件采用2字突发架构。 它提供×18和×36数据总线宽度。
QDR-IV XP SRAM器件具有一个组切换选项。分组操作一节描述了如何使用组切换,让器件能够以更高的频率和RTR工作。
时钟信号说明
CK/CK#时钟与以下地址和控制引脚相关联:An-A0、AINV、LDA#、LDB#、RWA#以及RWB#。CK/CK#时钟与地址和控制信号中心对齐。
DKA/DKA#和DKB/DKB#是与输入写数据相关联的输入时钟。这些时钟与输入写数据中心对齐。
根据QDR-IV SRAM器件的数据总线宽度配置,表2显示了输入时钟与输入写数据之间的关系。为了确保指令和数据周期的正确时序,并确保正确的数据总线返回时间,DKA/DKA#和DKB/DKB#时钟必须符合各自数据表中给出的CK to DKx斜率 (tCKDK)。
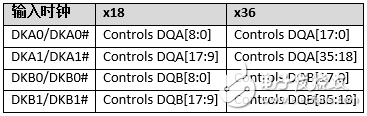
表2. 输入时钟与写数据之间的关系
QKA/QKA#和QKB/QKB#是与读取数据相关联的输出时钟。这些时钟与输出读取数据边沿对齐。
QK/QK#是数据输出时钟,由内部锁相环(PLL)生成。它与CK/CK#时钟同步,并符合各自数据表中给出的CK to QKx斜率 (tCKQK)。
根据QDR-IV SRAM器件的数据总线带宽的配置情况,表3显示了输出时钟与读取数据之间的关系。
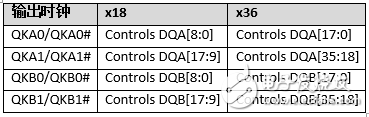
表3. 输出时钟与读取数据之间的关系
读/写操作
读和写指令由控制输入(LDA#、RWA#、LDB#和RWB#)和地址输入驱动。在输入时钟(CK)的上升沿上对端口A控制输入进行采样。在输入时钟的下降沿上对端口B控制输入进行采样。 表4显示的是端口A和端口B的读/写操作条件。
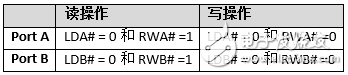
表4. 端口A和端口B的读/写条件
如图2 和图3 所示,对于QDR-IV HP SRAM,端口A的读取数据在CK的上升沿后整五个读取延迟(RL)时钟周期后才从DQA 引脚上输出;对于QDR-IVXP SRAM,则需要八个读延迟(RL)时钟周期。CK信号的上升沿发生,同时读取指令发出,经过指定的RL时钟周期后才可获取数据。
对于QDR-IV HP SRAM,端口A的写入数据在CK的上升沿后整三个写入延迟(WL)时钟周期才传输至DQA 引脚;对于QDR-IV XP SRAM,则需要五个写延迟(WL) 时钟周期。CK信号的上升沿发生,同时写入指令发出,经过指定的RL时钟周期后才可获取数据。
对于QDR-IV HP SRAM,端口B的读取数据在CK的上升沿后整五个RL 时钟周期才从DQB引脚上输出;对于QDR-IV XP SRAM,则需要八个RL 时钟周期。CK信号的上升沿发生,同时读取指令发出,经过指定的RL时钟周期后才可获取数据。
对于QDR-IV HP SRAM,端口B的写入数据在CK的上升沿后整三个WL 时钟周期才传输至DQB引脚;对于QDR-IV XP SRAM,则需要五个WL 时钟周期。CK信号的上升沿发生,同时写入指令发出,经过指定的RL时钟周期后才可获取数据。
QVLDA/QVLDB 信号表示相应端口上的有效输出数据。在总线上驱动第一个数据字的半周期前置位QVLDA 和QVLDB信号,并在总线上驱动最后一个数据字的半周期前取消置位它们。最后数据字后的数据输出是三态的。
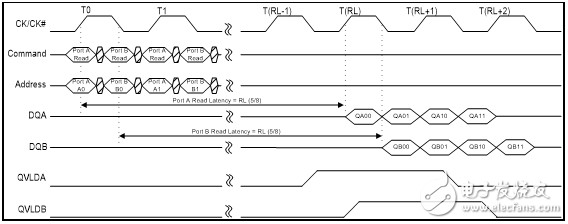
图2. 读取时序
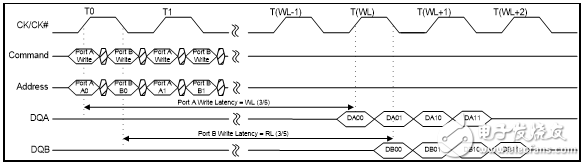
图3. 写时序
旨在实现高速运行的分组操作
QDR-IV XP SRAM 的设计是为了支持频率更高的八组模式(最大工作频率 = 1066 MHz),而QDR-IV HP SRAM 则支持频率较低的无分组模式(最大工作频率 = 667 MHz)。
QDR-IV XP 中较低的三个地址引脚(A2、A1 和A0)选择了在读或写期间将要访问的组。唯一的分组限制是在每个时钟周期内该组仅能被访问一次。QDR-IV XP SRAM 的组访问规则要求在端口B 上访问的组地址与在端口A 上访问的组地址不相同。
如果不符合分组限制,那么由于在时钟的上升沿时已经对读/写操作进行采样,在端口A 上则不会限制读/写操作,但会禁止端口B 上的读/写操作。QDR-IV HP SRAM 并没有任何分组限制。
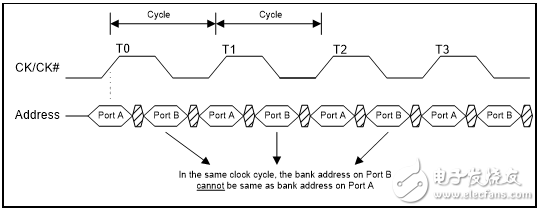
图4. QDR-IV XP SRAM – 写/读操作
在相同的时钟周期内,端口B上的组地址与端口A上的组地址不相同
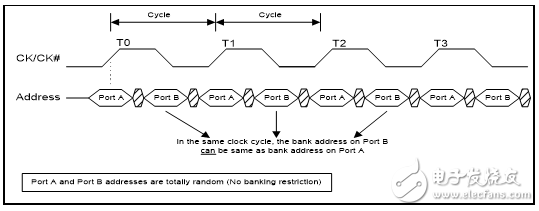
图5. QDR-IV HP SRAM –写/读操作
QDR-IV XP SRAM 上的分组限制可作为某些应用的一个优点,在这些应用中,存储器中的每一组都有不同的用途,并且都不能在同一个时钟周期中被访问两次。一个网络路由器能够在QDR-IV XP SRAM 的每一组内储存不同的路由表便是一个实例。如果在同一个时钟周期内特定的路由表仅能被访问一次,则有可能实现高TRT (随机数据传输速率)。在该情况下,工作频率为1066 MHz 时,可获得的最高随机数据传输速率为2132 MT/s。
分组限制不会影响到数据传输速率的另一种情况是使用物理层上的多个端口进行设计,通过每一个端口可以直接访问存储器中一组。这些端口将被复用到QDR-IV XP SRAM 的端口A 和端口B。在该设计中,因为每一个组都连接了物理层上不同的端口,因此任何一个组都不能在同一个时钟周期内被访问两次。
不过,如果第一次访问某一组是通过当前时钟周期的下降沿上端口B 进行的,并且第二次访问则是通过下一个时钟周期的上升沿上端口A 进行的,那么可以在一个时钟周期内再次对同一组进行访问。如图6所示,在进行写操作期间,端口B 和端口A 都可以在一个时钟周期内访问组Y。同样,在进行读操作期间,端口B 和端口A 可以在一个时钟周期内访问组X。
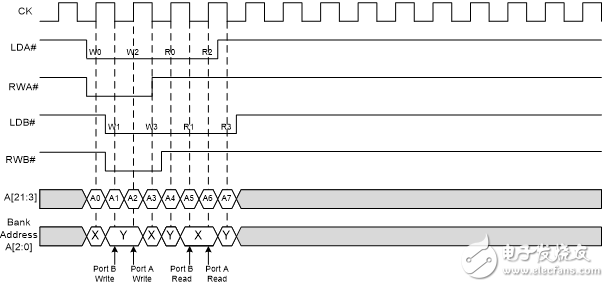
图6. 在一个时钟周期对同一个存储器组进行访问
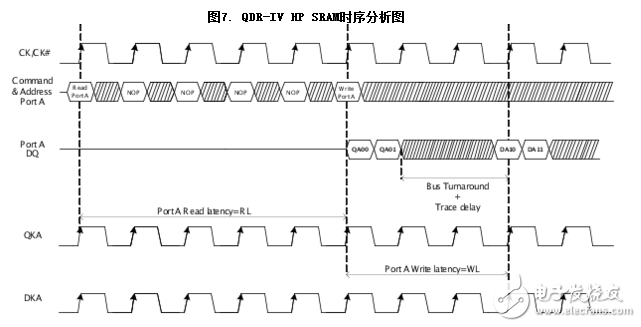
总线转换时间非常重要,其决定了读和写指令间是否需要额外的间隔来避免在同一个I/O 端口上发生总线冲突。
想象下QDR-IV HP SRAM 中端口A 先后收到写指令和读指令。从CK 信号的上升沿(与初始化写指令周期相对应)算起,在整整三个时钟周期后向DQA 引脚提供写数据。读数据则将在下一个周期发送,因为 DQ从CK 信号的上升沿(与初始化读指令的周期相应)算起五个时钟周期后才能获得数据。此外,为符合总线转换时间和传输时延(从ASIC/FPGA 到QDR IV 存储器),还有两个额外周期。因此,启动写指令后,可以立即启动读指令。
在其他情况下,如果先启动读指令后启动写指令,那么发送读指令经过三个时钟周期后,才能发送写指令。这是因为,从在时钟信号CK 的上升沿上对读指令进行采样算起,经过五个周期后可获得DQA 引脚上的读数据,并且从在时钟信号CK 的上 升沿上对写指令进行采样算起,在整三个时钟周期内向DQA 引脚提供写数据。否则,将会发生总线冲突。因此,发送写指令后的最小时钟周期应该为RL – WL + 1(RL:读时延;WL:写时延;这两个时延的单位为时钟周期数)。另外一个时钟周期用于正确捕获数据并补偿总线转换时延(通常为一个时钟周期)。
如果传输时延大于总线转换时延,那么‘读到写’指令间的间隔为:
“读到写”指令间的时间周期 = 读时延 – 写时延 + 1 + 传输时延
请参考图7。发送读指令经过四个时钟周期后,将发送端口A 的写指令。这样是为了避免因读/写时延、总线转换时间和传输时延间的差别而导致的总线冲突。
总线翻转
QDR-IV 器件支持总线翻转以降低切换噪声和I/O功耗。在存储事务处理中,存储器控制器和QDR-IV都可以选择应用总线翻转。
由于QDR-IV 器件的POD 信令模式为I/O 信号提供了到VDDQ 的高压终端选项,所以信号转为高电平逻辑状态不会耗电。因此,总线翻转对于POD I/O 信号是一个很重要的性能。QDR-IV 会保证翻转地址和数据总线的数据完整性。
使用芯片配置寄存器来启用或禁用地址和数据总线翻转功能。
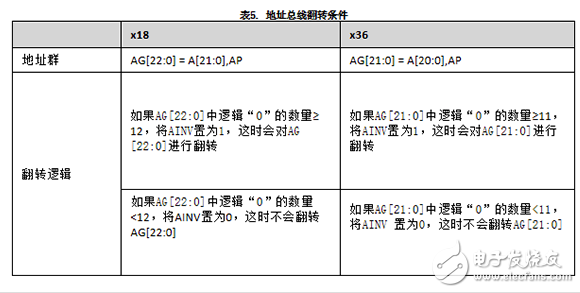
地址总线翻转
AINV 是双倍数据速率信号,每次将地址发送给存储器器件时都会更新该信号。AINV 引脚指示是否对地址总线(An –A0)和AP 进行了翻转。AINV 是高电平有效信号。当AINV = 1 时,将翻转地址总线;当AINV = 0 时,不翻转地址总线。AINV 引脚的功能由存储器控制器控制。
地址总线和地址奇偶位都被视为地址组(AG)。
表5显示的是AG 定义以及x18 和x36 QDR-IV 选项的AINV 设置条件。
x36器件示例
不进行地址总线翻转:
假设要访问的地址分别为22’h 000199和22’h 3FFCFF。17个地址引脚需要在第一个和第二个地址的逻辑状态间进行切换,如下表所示(红色单元格显示)。这样会增大地址引脚上的切换噪声、I/O电流以及串扰。

进行地址总线翻转:
根据表5显示,第一个地址组(22‘h 000199)满足翻转逻辑条件。因此,存储器控制器发送第一个地址组前,它会将地址组从22’h 000199翻转为22’h 3FFE66,并将AINV引脚置为1。由于不需要翻转第二个地址组,所以存储器控制器可以将其直接发送,并将AINV设置为0。
下表显示的是地址总线翻转的结果。在这种情况下,只有5个地址引脚需要切换逻辑(红色单元格显示)。切换位的总数降低为5,所以降低了由于同时切换输出(SSO)而引起的噪声、I/O电流以及串扰。

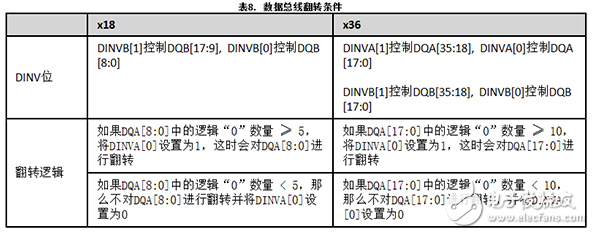
数据总线翻转
数据总线翻转在数据线路中也类似,但翻转位由存储器控制器在存储器写操作期间生成,并且翻转位由QDR-IV存储器中的翻转逻辑在存储器读操作期间生成。
DINVA和DINVB引脚指示了是否翻转相应的DQA和DQB引脚。DINVA和DINVB均为高电平有效信号。当DINV = 1时,将翻转数据总线;当DINV = 0时,不翻转数据总线。
DINVA[1]和DINVA[0]相互独立并控制与其相应的DQA组。DINVA[0]控制DQA[17:0](对于x36的配置)或DQA[8:0](对于x18的配置)。DINVA[1]控制DQA[35:18](对于x36的配置)或DQA[17:9](对于x18的配置)。同样,DINVB[0]控制x36配置中的DQB[17:0]或x18配置中的DQB[8:0]。DINVB[1]控制x36配置中的DQB[35:18]或x18配置中的DQA[17:9]。
表8显示的是DINV位说明以及x18和x36 QDR-IV选项的DINVA设置条件。
注意:可以对DINVA[1]、DINVB[0]以及DINVB[1]使用相同的翻转逻辑,以便控制相应的DQ组。
x18器件的示例
不进行数据总线翻转:
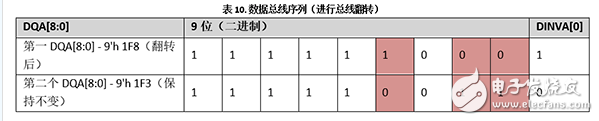
假设需要分别发送DQA[8:0]上的9’h 007和9’h 1F3。6个数据引脚需要在第一个和第二个DQA[8:0]位的逻辑状态之间进行切换,如下表所示(红色单元格显示)。这样会增大数据引脚上的切换噪声、I/O电流以及串扰。

进行数据总线翻转:
根据表8,第一个DQA[8:0]满足翻转逻辑条件。因此,存储器控制器发送第一个DQA[8:0]前,它会将引脚地址从9’h 007翻转为9’h 1F8,并将DINVA[0]引脚设置为1。由于第二个DQA[8:0]不需要翻转,所以存储器控制器可以直接发送它,并将DINVA[0]设置为0。
表10显示的是数据总线翻转的结果。在这种情况下,只有3个数据引脚需要切换逻辑(红色单元格显示)。切换位的总数降低为3,所以降低了SSO的噪声、I/O电流以及串扰。
地址奇偶校验
QDR-IV只有一条地址总线,但其以双倍数据速率和高频率运行。因此,地址奇偶校验输入(AP)和地址奇偶校验错误标志输出(PE#)引脚提供了片上地址奇偶校验功能,以便能够确保地址总线完整性。地址奇偶校验功能是可选的;可以使用配置寄存器来启用或禁用它。
通过该AP引脚可以在各地址引脚(An到A0)上进行偶校验。设置AP值,使AP和An-A0中逻辑“1”的总数为偶数。
对于数据总线宽度为x18的器件,设置AP值,使A[21:0]和AP中逻辑“1”的总数为偶数。
对于数据总线宽度为x36的器件,设置AP值,使A[20:0]和AP中逻辑“1”的总数为偶数。
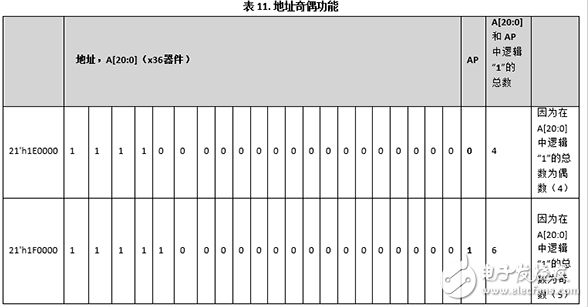
器件的示例
以数据总线宽度为x36的器件的21’h1E0000和21’h1F0000地址为示例。表11显示的是如何为每个地址设置AP值。
当发生奇偶错误时,在配置寄存器4、5、6和7中(请查看相关数据手册,了解有关配置寄存器的更多信息)记录第一个错误的完整地址以及端口A/B错误位和地址翻转位。端口A/B错误位表示发生地址奇偶错误的端口:0表示端口A,1表示端口B。持续锁存该信息,直到向配置寄存器3中的地址奇偶错误清除位写入1来清除该信息为止。
通过两个计数器,可以表示是否发生了多个地址奇偶错误。端口A错误计数是端口A地址上奇偶错误数量的运行计数器。同样,端口B错误计数是端口b地址上奇偶错误数量的运行计数器。每个计数器独立计数到最大值(3),然后将停止计数。这些计数器均是自由运行的;对配置寄存器3的地址奇偶错误清除位写入1,可将其复位。
检测到地址奇偶错误后,写操作就会被忽略,以防止损坏存储器。但是,如果输入地址错误,仍会继续执行读操作,但存储器会发送出假数据。
PE#为低电平有效信号,表示地址奇偶错误。检测到地址奇偶错误后,PE#信号在8个周期(QDR-IV XP SRAM)或5个周期(QDR-IV HP SRAM)内被设置为0。它将保持置位状态,直到通过配置寄存器清除了错误为止。处理完地址翻转便表示完成了地址奇偶检查。
PE#转为低电平后,会停止存储器操作,并使用配置寄存器将PE#复位为高电平。此外,由于发生AP错误的写操作也被阻止,所以需要向存储器重新编写数据。
校正训练序列
存储器控制器和QDR IV较高的工作频率意味着数据有效窗口很窄。QDR-IV器件支持“校正训练序列”,它可通过减少字节通道之间的偏差扩大这个窗口,从而在控制器读取存储器的数据时,增加时序余量。校正训练序列是赛普拉斯的QDR-IV SRAM的初始化过程的一部分。该训练序列通常被那些不支持内置校正功能的应用使用。
训练序列如图8所示:
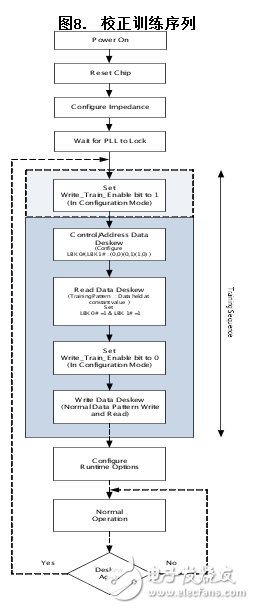
校正训练序列是初始化过程的一部分。对序列进行加电和复位后,在配置模式下进行操作的过程中,控制器必须立即设置选项控制寄存器中的Write_Train_Enable位(位的位置:7)。通过该操作,控制器可以避免在进行训练序列前再次进入配置模式。设置该位不会影响到校正训练序列,直到进行读取数据校正训练为止。
通过以下三个步骤,可以实现校正过程:
1.控制/地址校正
2.读取数据校正
3.写入数据校正
控制/地址校正
根据需要校正的信号,将LBK0#和LBK1#设为它们相应的位值。请查看表12,了解环回信号的映射情况。39个输入信号被环回到端口A上的数据引脚。根据LBK0#和LBK1#的状态,一次将13个输入信号映射到DQA0-DQA12。
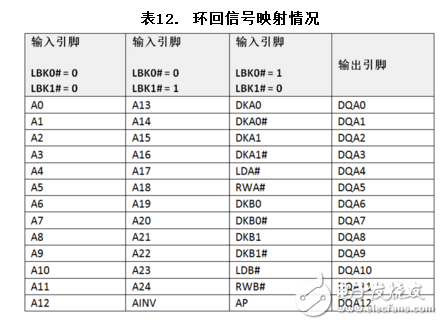
DKA0、DKA0#、DKA1、DKA1#、DKB0、DKB0#、DKB1和DKB#1等时钟输入都是自由运行的,并应在训练序列中持续运行。
通过使用输入时钟(CK/CK#)可在上升沿和下降沿上对每个输入引脚进行采样。在输出时钟(QKA/QKA#)的上升沿上采样的输出值即为在输入时钟的上升沿上所采样的值。在输出时钟(QKA/QKA#)的下降沿上采样的输出值即为在输入时钟的下降沿上所采样的翻转值。在这种模式下,数据翻转无效,在进行地址/控制环回训练过程中,CFG#信号将为高电平。
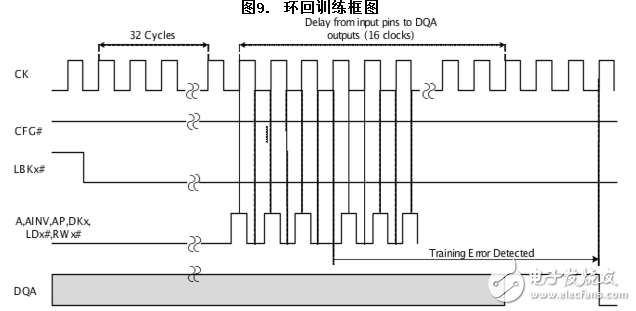
如图9所示,如果地址/控制信号未校正,DQA 上的信号(应在训练期间保持高电平)将变为低电平。该信号转换应由驱动信号的模块捕获,控制器则会对信号相应进行校准。
读取数据校正
在该阶段,地址、控制和数据输入时钟都已经得到了校正。在读取数据校正过程中,用于写入存储器内的训练数据模型是一个常量值(D00,D01,D20,D21),如下面的波形框图中显示。在此训练序列中,LBK0#和LBK1#均被设置为1。
配置选择控制寄存器时,Write_Train_Enable 位将被设置为1。第一个和第二个数据突发均在同一个数据总线上被采样的,但第二个数据突发则在写到存储器内前完成采样的。Write_Train_Enable 位不会对读取数据周期产生任何影响。
将数据模型写到存储器内后,标准的读指令允许控制器访问这些数据,并会校正QK/QK#信号。当 Write_Train_Enable = 1 时,在写入过程中,DINVA/DINVB 将被忽略,在读取过程中,它将始终切换。
如下面的读取数据校正框图中所示,写入到存储器内的数据(D00、D01、D20、D21)全为1,相应的读取数据(Q00、Q01、Q20、Q21)则在1 和0 间切换。控制器必需捕捉到这些切换数据并进行验证。否则,控制器需要一个精确的校准来确认读取数据校正。
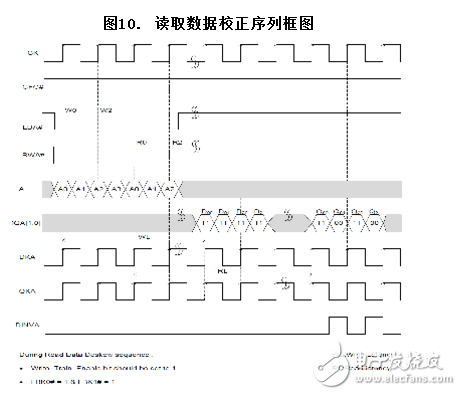
在读数据校正序列中:
l设置Write_Train_Enable位为1
lLBK0# = 1 及LBK1# = 1
写数据校正
此时,地址、控制、时钟和数据输出都已经得到了校正。执行写入数据校正序列前,先再次进入配置模式,然后通过将相应位设置为0来禁用Write_Train_Enable。
在正常工作模式下,使用读指令后,通过使用存储器的写指令可校正写数据。所校正的读取数据路径用于确认器件是否已经正确地接收到写入数据。这样使处理器/FPGA能够校正下列与DK/DK#输入数据时钟有关的信号:DQA、DINVA、DQB和DINVB。
纠错码(ECC)
系统设计人员必需依赖片外纠错或冗余等技术提高可靠性。这些技术会增加PCB空间或处理时间方面的开销。QDR-IV是一个单芯片解决方案,引入了片上纠错码(ECC),从而节省了空间和成本,降低了设计复杂性。此外,它还降低了QDR-IV存储器阵列的总软失效率(SER)。该特性可应用于数据总线宽度为x18和x36的选项,并在SRAM中始终被启用。ECC保护提供了单比特纠错(SEC)。
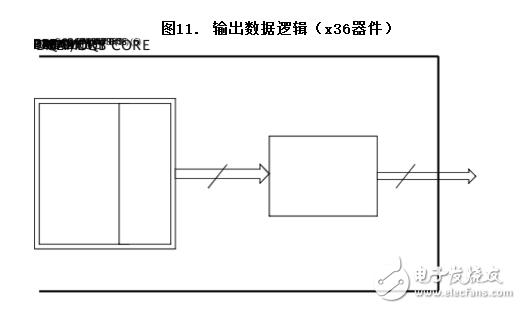
QDR-IV从输入数据生成ECC奇偶校验位,并将它们存储在存储器阵列中。存储器阵列包含用于存储ECC奇偶校验的额外位。但是,不会将这些额外的内部校验位用于外部引脚。
例如,图11显示的是x36器件的输出数据逻辑框图。36数据位需要6个ECC校验位;存储器内核会将42位(36个数据位 + 6个 ECC校验位)传输到ECC逻辑内。因此,ECC逻辑会提供已纠正的36位输出数据。
无ECC位的QDR/DDR SRAM的SER故障率(FIT)通常为200 FIT/Mb。但带有ECC时,该数值将为0.01 FIT/Mb,提高了4个数量级。
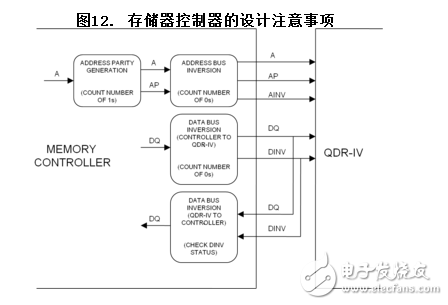
QDR-IV存储器控制器的设计建议
本节提供一些存储器控制器启用QDR-IV的地址奇偶校验和总线翻转功能的设计建议。
存储器控制器首先要根据地址总线生成地址奇偶。然后,需要在地址总线和地址奇偶位上进行地址翻转。
对于数据总线转换,将数据发送给QDR-IV前,存储器控制器需要计算每个DQ总线上的逻辑“0”的数量,以便生成相应的DINV位(取决于数据总线翻转条件)。
将数据发送给存储器控制器时,QDR-IV使用相同的数据总线翻转逻辑。为了识别QDR-IV的接收数据,控制器仅要检查相应DINV位的状态。如果控制器接收DINV = 1,需要翻转相关的数据总线;否则,保持接收到的数据位不变。
图12显示的是存储器控制器的设计注意事项。
- 相关推荐
- 热点推荐
- 网络系统
-
LTM4632为三个电源轨提供完整的高性能稳压器解决方案2023-01-06 1914
-
如何用NILabVIEW建立一个完整的无线传感器网络系统?2021-06-07 1666
-
采用QDR-IV SRAM的网络流量管理统计计数器IP设计2019-07-17 1501
-
用于DDR、QDR和QDR-IV SRAM的完整高性能稳压器解决方案2019-05-06 2186
-
LTM4632高性能稳压器解决方案的多方面应用2019-04-16 4433
-
采用QDR-IV SRAM设计统计计数器IP2018-09-23 4073
-
神经网络系统辨识程序2018-01-04 1521
-
使用QDR-IV设计高性能网络系统2017-12-06 925
-
如何为网络交流管理和其他计数器应用提供高效统计计数器的软IP2017-09-16 4280
-
用于DDR、QDR和QDR-IV SRAM的超薄型三路输出µmodule稳压器2017-05-08 710
-
车载网络系统硬件及其驱动的设计2010-07-13 390
-
什么是网络系统环境2009-12-28 1381
-
智能小区的网络系统设计2009-05-29 807
全部0条评论

快来发表一下你的评论吧 !
