

使用语义线索增强局部特征匹配
描述
来源:3D视觉工坊
1. 导读
视觉匹配是关键计算机视觉任务中的关键步骤,包括摄像机定位、图像配准和运动结构。目前最有效的匹配关键点的技术包括使用经过学习的稀疏或密集匹配器,这需要成对的图像。这些神经网络对两幅图像的特征有很好的总体理解,但它们经常难以匹配不同语义区域的点。本文提出了一种新的方法,通过将语义推理结合到现有的描述符中,使用来自基础视觉模型特征(如DINOv2)的语义线索来增强局部特征匹配。因此,与学习匹配器不同,学习描述符在推理时不需要图像对,允许使用相似性搜索进行特征缓存和快速匹配。我们提出了六个现有描述符的改编版本,在相机定位方面的性能平均提高了29%,在两个现有基准中与LightGlue和LoFTR等现有匹配器的准确性相当。
2. 引言
视觉匹配关系对于相机姿态估计、同步定位与地图构建(SLAM)以及运动恢复结构(SfM)等重要高级视觉任务至关重要。最近,用于在图像对之间寻找视觉匹配关系的流程正在发生变化,更偏向于采用提供不同类型上下文聚合的方法,如学习的稀疏匹配器或密集对应关系网络。这些方法依赖于从两个视角收集信息,以调节特征,从而更好地预测对应关系。尽管它们已被证明在下游任务中能提供更好的结果,但需要对每对图像都运行一次,因此在诸如SfM流程等大型任务中使用成本高昂,在这些任务中,单张图像将与其他具有相似视点的图像多次匹配。虽然传统的单视图流程可以为单个图像预先提取特征,并使用高效的相似性搜索(如互最近邻MNN),但其表现不如上下文聚合方法。
本文提出了一种方法,通过语义调节关键点描述符,以找到更好且更一致的对应关系,同时保持单视图提取和缓存的优势。基础模型(如DINOv2和SAM)可以提取包含场景中语义概念理解的特征,以补充局部纹理模式。通过冻结主干网络并针对特定任务训练新层,这些特征可以适应于各种任务,例如图像分类、实例检索、视频理解、深度估计、语义分割和语义匹配。为了捕捉场景和对象的意义,DINOv2等模型已经发展出对局部纹理变化具有强大不变性的能力。然而,这些特征的高度不变性在识别图像之间的像素级匹配时会降低其敏感性。相反,它们可以为区域之间的一致性提供基础,这可用于过滤视觉上相似但语义上不同的区域之间的连接。
在本文中,我们提出了一种有效的技术,不是依赖于双视图上下文聚合,而是利用来自大型视觉模型(LVM)的高级特征理解,来语义调节基于纹理的对应关系。
3. 效果展示
利用语义信息改善视觉匹配关系。该图示展示了使用互最近邻(MNN)对基础描述符XFeat和我们的方法(采用语义条件,如图右上角所示)进行匹配的过程。正确匹配用绿色表示,错误匹配用红色表示。我们还可以通过使用语义或纹理特征,在图像中找到给定查询点(左下角红点)的128个最接近的匹配项,来评估描述符的可解释性和一致性。颜色越暖表示相似性越高。请注意,在水槽区域附近,使用条件特征后的相似性排名有所提升。
4. 主要贡献
本文的关键技术贡献是一种新颖的学习方法,用于将语义上下文整合到局部特征中,从而在匹配过程中实现高效的相似性搜索,并显著提高匹配准确性。实验结果表明,我们的方法在室内环境中的相机姿态估计和视觉定位任务中,显著提升了各种检测和描述技术的性能。
5. 方法
我们阐述了本研究方法的主要概念,详细说明了如何将语义感知添加到局部描述符中,以及为训练该描述符所设计的监督方法。整体训练和推理阶段的方案如图2所示。推荐课程:面向三维视觉的Linux嵌入式系统教程[理论+代码+实战]。
所提策略首先提取两组描述符:一组是使用现成的局部特征方法获得的纹理特征,另一组是来自用于上下文信息的局部视觉模型(LVM)(如本文所选的DINOv2)。为此,我们采用了一种提取传统、以纹理为中心特征的基础方法,以及一种提取以语义为中心特征的基础方法。在基础提取之后,我们使用自注意力推理模块对特征进行细化。为了找到匹配的图像对,我们使用为每幅图像独立提取的两组纹理和语义特征,通过语义条件计算相似度矩阵,以找到相互匹配项。
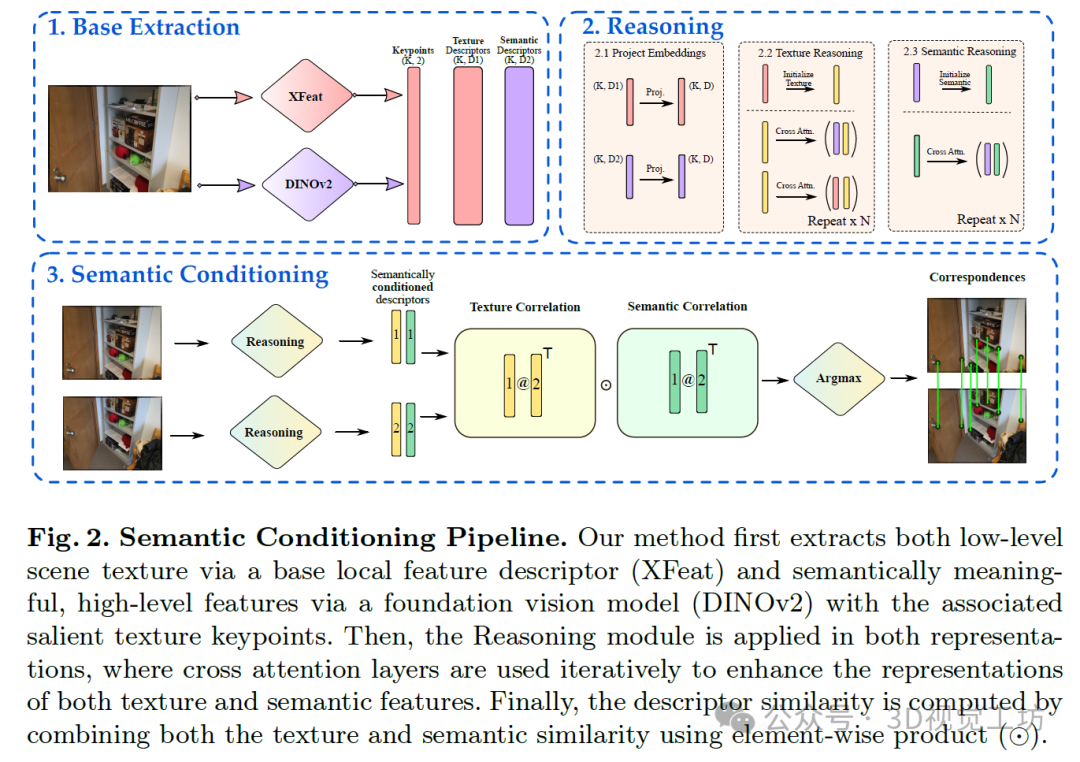
在训练过程中,基础提取器的参数保持不变(冻结),我们仅优化初始投影和描述符推理的权重,如图2所示。我们冻结权重是因为每个基础提取器可能有更适合其的特定训练策略。通过使用冻结的、现成的提取器,我们可以容纳更多方法。DINOv2也根据[11]进行了冻结,该文献将其用作多个任务的骨干网络。
6. 实验结果
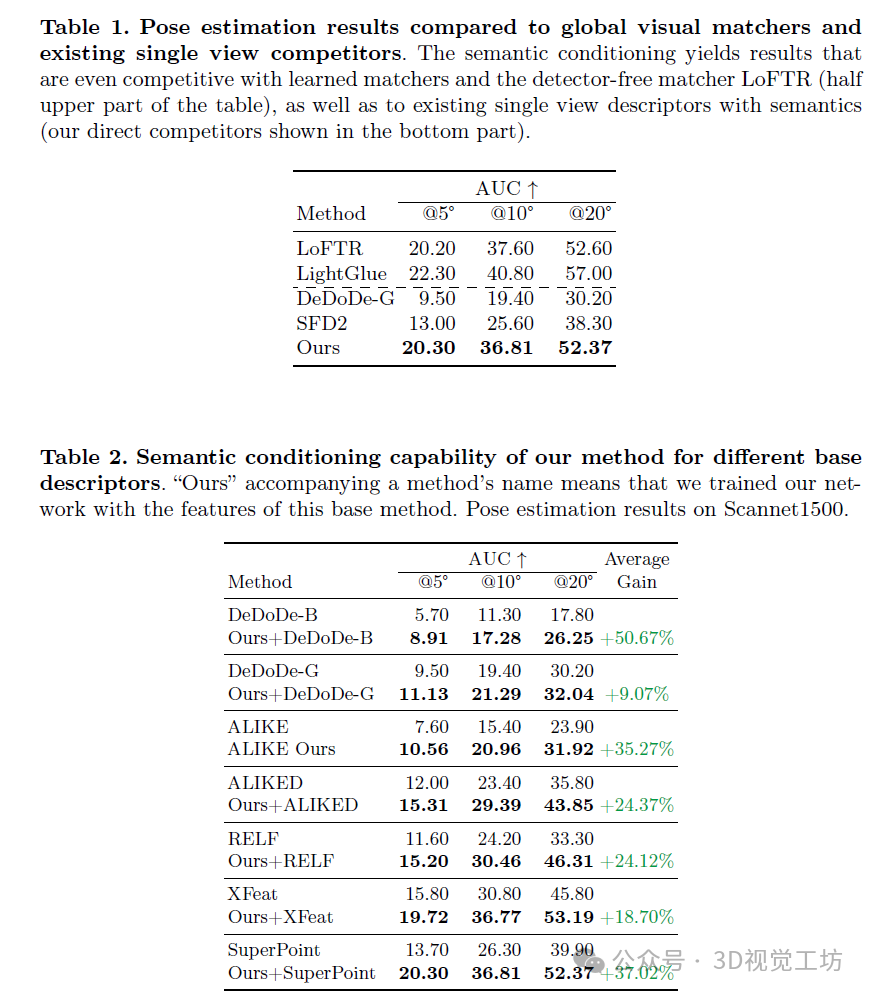
定量配准结果如表1和表2所示。表1中包含了双视图上下文聚合方法,如Light-Glue和LoFTR,以及其他也利用语义信息的描述符,如DeDoDe-G和SFD2。值得注意的是,即使仅进行单视图提取,SuperPoint与语义条件相结合也能与LightGlue(没有任何配对视图感知)相比产生具有竞争力的结果。表2描述了我们设计的利用语义信息提高现有描述符匹配能力的策略。我们可以注意到,当与我们所提出的语义条件相结合时,所有基线均取得了显著改进。尽管其中许多方法(如DeDoDe、SFD2、ALIKE和ALIKED)仅使用MegaDepth数据集中的室外图像进行训练,但在不重新训练特征提取器或DINOv2骨干网络的情况下,我们仍可将它们的室内位姿估计结果提高至少24%。这一结果表明,所提取的视觉线索本身并不优于这些描述符的原始版本,但通过语义信息的辅助,其条件得到了改善。
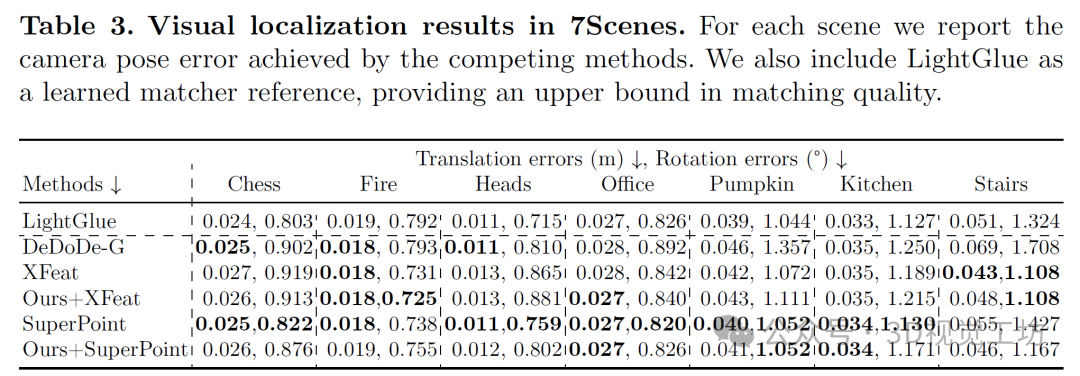
视觉定位基准测试结果如表3所示。一个有趣的观察结果是,我们的方法能够在多种情况下减少XFeat的错误。对于SuperPoint,我们的方法未能提供有意义的改进。我们推测,由于XFeat的骨干网络较小,它提供的特征更简洁、冗余更少,因此不易过拟合,且能最大程度地利用语义信息。在考虑不同阈值内定位相机的百分比时,我们实现了最高的正确定位相机平均百分比。从更严格的阈值(1◦、1厘米至500厘米、10◦)来看,LightGlue是黄金标准但匹配成本高昂,正确定位了66.97%的相机。紧随其后的是我们的方法(以SuperPoint为基础纹理检测器):66.95%,SuperPoint:66.88%,XFeat:66.36%,DeDoDe-G:64.44%。这表明,语义信息可以增加模糊区域的对应点数量,如图3所示。
7. 总结 & 未来工作
本研究工作引入了一种基于学习的视觉特征描述技术,该技术能够利用图像中存在的语义线索。我们设计了一个执行信息聚合的网络,该网络利用语义特征来细化和调整现成的描述符,从而提高室内视觉匹配的准确性。在相机位姿估计方面,我们的方法性能优于现有的探索语义线索的最先进模型,并且即使与最近的学习匹配器(如LightGlue)相比也颇具竞争力,而我们仅使用单幅图像进行特征提取,并使用最近邻搜索进行匹配。通过大量实验,我们证明了我们的方法可以将六种不同基础描述符的位姿估计结果平均提高25%。改进后的描述符可以在大规模结构从运动恢复(SfM)重建中使用单视图进行图像提取,因为最近邻(MNN)匹配比数千对图像运行学习匹配器要快得多。
-
基于RGM的鲁棒且通用的特征匹配2023-11-27 1701
-
深度学习—基于军事知识图谱的作战预案语义匹配方法研究2021-11-11 2668
-
借助局部实体特征的事件触发词抽取方法2021-05-26 1177
-
RGPNET:复杂环境下实时通用语义分割网络2020-12-10 1419
-
如何使用语义感知来进行图像美学质量评估的方法2018-11-16 1340
-
基于局部轮廓特征的类圆对象识别方法2017-12-19 1035
-
基于行为特征的语义工作流修正算法2017-12-14 996
-
基于纹理特征匹配的快速目标分割方法2017-12-07 958
-
基于SVM的局部潜在语义分析算法研究2017-12-06 757
-
基于局部特征匹配的目标跟踪研究2011-12-06 753
-
基于局部特征和整体特征融合的面部表情识别2010-06-22 610
-
基于OWL属性特征的语义检索研究2010-02-11 976
-
基于改进局部不变特征的兴趣点匹配2010-02-10 552
-
一种基于SIFT描述子的特征匹配新算法2009-12-07 812
全部0条评论

快来发表一下你的评论吧 !
