

一种将NeRFs应用于视觉定位任务的新方法
描述
来源:3D视觉工坊
0. 这篇文章干了啥?
视觉定位旨在估计在已知环境中捕获的给定图像的旋转和位置,大致可以分为绝对姿态回归(APR),场景坐标回归(SCR)和分层方法(HM)。APR将地图嵌入到高级姿态特征中,并使用多层感知器(MLP)预测6自由度姿态;它们对于大规模场景来说速度很快,但由于隐式3D信息表示,精度有限。与APR不同,SCR对像素进行3D坐标回归以直接构建2D-3D匹配,并使用PnP和RANSAC估计姿态。尽管在室内环境中具有很高的精度,但SCR无法扩展到室外大规模场景。HMs不使用端到端的2D-3D匹配预测,而是采用全局特征在数据库中搜索参考图像,然后建立提取的查询关键点和参考图像之间的对应关系;这些2D-2D匹配被提升为2D-3D匹配,并用于使用PnP和RANSAC的绝对姿态估计,就像SCR一样。由于精度高和灵活性强,HMs最近被广泛使用。然而,2D关键点存储的巨大内存成本损害了它们在实际应用中的效率。
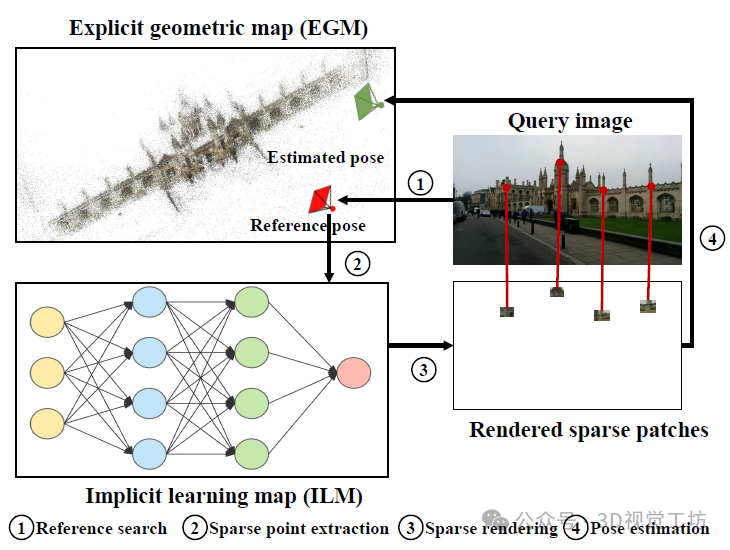
这篇文章旨在找到一种高效准确的大规模视觉定位任务的解决方案。为了实现这一目标,作者采用了一种混合地图的方法,仅通过渲染有用的稀疏像素来实现NeRFs的高效定位。混合地图由两部分组成:显式几何地图(EGM)和隐式学习地图(ILM)。EGM包含稀疏的3D点以及它们在参考图像上的2D观测。ILM是由NeRFs表示的隐式地图。在测试时,参考图像的2D观测提供先验的稀疏像素位置和相机姿态作为NeRFs的输入。NeRFs返回每个稀疏像素的RGB值。为了提高精度,为每个像素渲染一个具有恒定大小的补丁。这些渲染的补丁进一步用于使用PnP和RANSAC进行绝对姿态估计的2D-3D匹配。
2. 摘要
视觉重定位是自动驾驶、机器人技术和虚拟/增强现实的关键技术。经过数十年的探索,绝对姿态回归(APR)、场景坐标回归(SCR)和分层方法(HMs)已成为最流行的框架。然而,尽管 APR 和 SCR 具有较高的效率,但在大规模室外场景中精度有限;HMs 具有较高的精度,但需要存储大量用于匹配的 2D 描述符,导致效率低下。在本文中,我们提出了一种高效且准确的框架,称为 VRS-NeRF,用于稀疏神经辐射场的视觉重定位。具体来说,我们引入了显式几何地图(EGM)用于 3D 地图表示和隐式学习地图(ILM)用于稀疏补丁渲染。在这个定位过程中,EGP 提供了稀疏 2D 点的先验信息,ILM 利用这些稀疏点使用稀疏 NeRF 渲染补丁进行匹配。这使我们能够丢弃大量的 2D 描述符以减小地图大小。此外,仅为有用的点渲染补丁,而不是整个图像中的所有像素,可以显著减少渲染时间。这个框架继承了 HMs 的精度,但丢弃了它们的低效率。对 7Scenes、CambridgeLandmarks 和 Aachen 数据集的实验表明,我们的方法比 APR 和 SCR 具有更好的准确性,并且与 HMs 的性能相近,但效率更高。
3. 效果展示
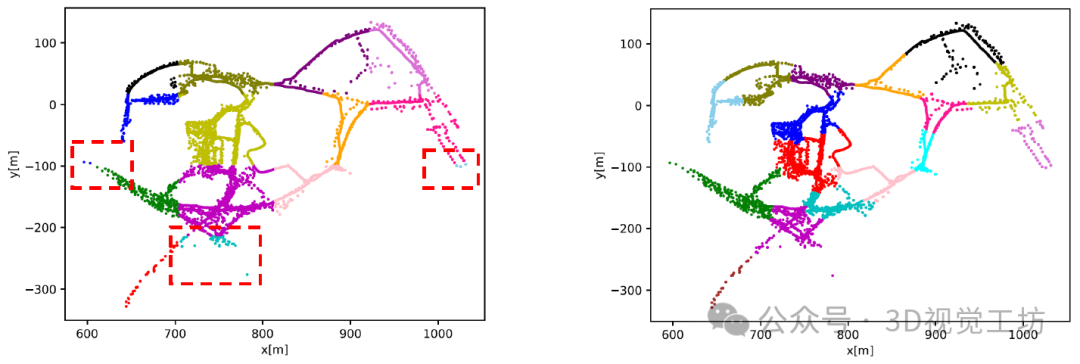
亚琛数据集上场景划分的可视化。场景的统一划分导致了不平衡的片段(左),在参考姿势上的聚类给出了更平衡的结果(右)。
渲染图像的可视化。可视化了来自7 scenes(上图)、Cambridge landmarks(中图)和Aachen(下图)数据集的渲染和地面实况图像。
匹配的可视化。可视化了来自7 scenes(顶部)、Cambridge landmarks(中间)和Aachen(底部)数据集的查询图像(左)和参考图像(右)之间的匹配。
4. 主要贡献
(1)提出了一种混合方法,结合显式几何地图和隐式学习地图进行视觉定位,使定位系统高效且准确。
(2)仅为有用的稀疏关键点渲染补丁,而不是渲染图像,避免了耗时的渲染过程。
(3)采用基于聚类的策略进行场景划分,使NeRFs能够在大规模室外环境中工作。
5. 基本原理是啥?
借助EGM和ILM,VRS-NeRF能够在线渲染有用的像素,而不是依赖离线2D描述符进行匹配,从而使定位系统更加高效。为了使当前的NeRFs在大规模场景中工作,VRS-NeRF采用了基于聚类的策略来自适应自动地将场景划分为较小的场景。
6. 实验结果
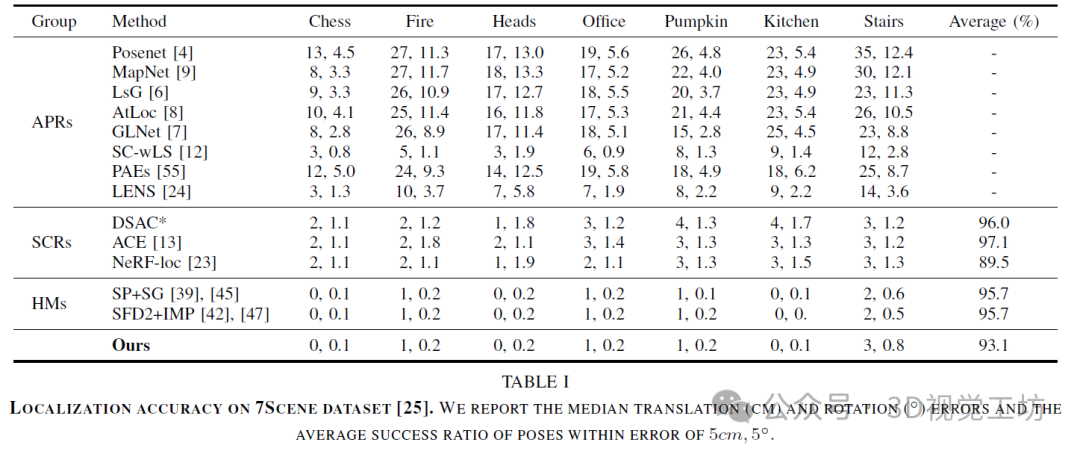
将VRS-NeRF与之前的APRs和HMs进行比较。APRs给出了最大的误差,因为它们在定位过程中与图像检索具有相似的行为,导致姿态精度有限。由于大多数APRs只报告中位误差,因此它们的成功率不可用。SCRs由于其显式的三维坐标回归,获得比APRs高得多的准确性。HMs在中位误差方面实现了最佳准确性。然而,由于依赖稀疏关键点,它们对无纹理区域的鲁棒性较差,因此其报告的准确性比某些SCRs,如DSAC*和ACE稍差一些。尽管VRS-NeRF用于定位稀疏补丁,但其在中位误差方面的表现接近于HMs,并且在中位误差方面明显优于APRs和SCRs。与HMs类似,VRS-NeRF也对无纹理区域敏感。由于EGM继承了HMs的优点,它优于以前的方法LENS和NeRF-loc,它们分别将NeRFs引入了APRs和SCRs。
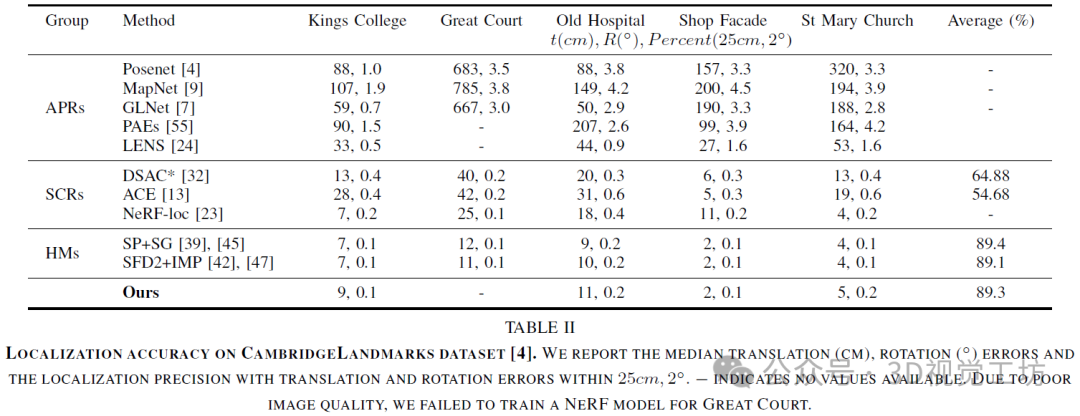
剑桥地标数据集上先前方法和VRS-NeRF的结果。报告中位平移(厘米)和旋转(°)误差以及误差阈值为25厘米,2°内的姿势成功率。由于缺少嵌入的三维信息,APRs的误差比SCRs大2倍以上。SCRs在中位平移和旋转误差方面报告了令人满意的准确性。然而,它们在25厘米,2°误差阈值内的成功率远远低于HMs。即使是最先进的DSAC*和ACE也无法达到与HMs相当的准确性。这些比较揭示了SCRs在户外场景中的准确性并不如预期那样高。HMs仍然是中位误差和成功率方面最准确的方法。由于VRS-NeRF也保留了显式的几何信息作为显式几何图,其结果与HMs一样准确,并且比APRs和SCRs准确得多。与先前基于NeRF的LENS和NeRF-loc相比,VRS-NeRF也实现了显着更好的准确性。
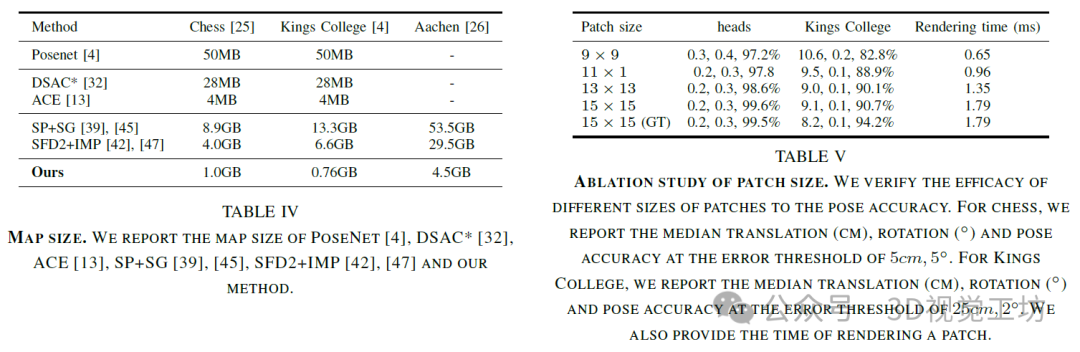
地图大小和时间分析。地图大小。在表IV中,展示了APRs,SCRs,HMs和VRS-NeRF的地图大小。对于APRs和SCRs,地图大小是模型大小。对于HMs,地图大小是局部描述符,全局描述符和三维点的总和。由于VRS-NeRF舍弃了局部描述符并引入了NeRFs,VRS-NeRF的地图大小是全局描述符,三维点和NeRFs的总和。APRs和SCRs都是内存有效的,因为它们将地图压缩到神经网络中,以损失准确性为代价。由于存储了2D描述符,HMs的地图大小较大。SFD2+IMP的地图大小比SP+SG小,因为SFD2具有较小的2D描述符维度。通过舍弃2D描述符,VRS-NeRF显著减小了地图大小。
消融研究,探讨了不同补丁大小对姿势准确性的影响。表V显示,随着补丁大小从8×9增加到15×15,姿势准确性也增加。在国王学院这样的户外场景中,这一点更为明显,因为查询和参考图像的视角和照明变化较大。然而,对于室内场景,由于查询和参考图像之间的变化很小,增加补丁大小的改进并不明显。此外,随着补丁大小的增加,渲染一个补丁所需的时间也会增加。因此,最终的解决方案是在准确性和效率之间取得平衡。对于没有查询和参考图像之间大变化的室内场景,作者建议使用较小的补丁大小以提高效率。对于查询和参考图像之间有大视角,照明变化的室外场景,较大的补丁大小可以带来更好的准确性。
7. 总结 & 未来工作
这篇文章提出了一种将NeRFs应用于视觉定位任务的新方法。具体来说,引入了显式几何地图(EGM)和隐式学习地图(ILM),以提供稀疏关键点和渲染补丁,以建立查询和渲染图像之间的稀疏匹配。通过从EGM提供的稀疏点进行稀疏渲染,VRS-NeRF避免了耗时的全图像渲染。通过NeRFs表示的ILM,VRS-NeRF舍弃了消耗内存的2D描述符。因此,VRS-NeRF更加高效。然而,与最先进的方法相比,在大规模亚琛数据集上的准确性仍然有限。作者希望这项工作可以成为一个基线,更多的研究人员可以在将来使其变得更好。
-
一种降低VIO/VSLAM系统漂移的新方法2024-12-13 1732
-
一种无透镜成像的新方法2024-07-19 1628
-
一种产生激光脉冲新方法2023-12-07 1559
-
一种产生激光脉冲的新方法2023-11-20 2423
-
一种改善微波模块增益指标温度特性的新方法2023-10-25 488
-
一种复制和粘贴URL的新方法2020-12-21 5135
-
Abacus展示了一种用于深度学习的新方法的技术2020-07-22 5899
-
一种在金上生成硫醇封端的SAM的新方法2019-10-30 1230
-
目前微通道面临的限制,突破硅技术的一种新方法2018-12-18 5378
-
PC机与单片机串行通信的一种新方法2017-09-04 1062
-
一种设计同步时序逻辑电路的新方法2017-02-07 1167
-
一种级数混合运算产生SPWM波新方法2017-01-07 791
-
一种标定陀螺仪的新方法2016-08-17 4292
-
一种均匀直线阵列干扰抑制的新方法2009-10-24 833
全部0条评论

快来发表一下你的评论吧 !
