

详解E2E-MFD多模态融合检测端到端算法
描述
转载自:量子位(QbitAI)
恶劣天气下,自动驾驶汽车也能准确识别周围物体了?!
西安电子科大、上海AI Lab等提出多模态融合检测算法E2E-MFD,将图像融合和目标检测整合到一个单阶段、端到端框架中,简化训练的同时,提升目标解析性能。
相关论文已入选顶会NeurlPS 2024 Oral,代码、模型均已开源。
其中图像融合是指,把不同来源(比如可见光和红外相机)的图像合并成一张,这样就能在一张图像中同时看到不同相机捕捉到的信息;目标检测即找出并识别图像中的物体。
端到端意味着,E2E-MFD算法可以一次性处理这两个任务,简化训练过程。
而且,通过一种特殊的梯度矩阵任务对齐(GMTA)技术,这两个任务还能互帮互助,互相优化。
最终实验结果显示,E2E-MFD在信息传递、图像质量、训练时间和目标检测方面均优于现有方法。
E2E-MFD:多模态融合检测端到端算法
众所周知,精确可靠的目标解析在自动驾驶和遥感监测等领域至关重要。
仅依赖可见光传感器可能会导致在恶劣天气等复杂环境中的目标识别不准确。
可见光-红外图像融合作为一种典型的多模态融合(MF)任务,通过利用不同模态的信息互补来解决这些挑战,从而促进了多种多模态图像融合技术的快速发展。
诸如CDDFuse和DIDFuse方法采用两步流程:
首先训练多模态融合网络(MF),然后再训练目标检测(OD)网络,用来分别评估融合效果。
尽管深度神经网络在学习跨模态表征能力上取得了显著进展,并带来了多模态融合的良好结果,但大多数研究主要集中在生成视觉上吸引人的图像,而往往忽略了改进下游高级视觉任务的能力,如增强的目标解析。
最近的研究开始设计联合学习方法,将融合网络与目标检测和图像分割等高级任务结合在一起。
其中,多模态融合检测(MFD)方法中MF与OD的协同已成为一个活跃的研究领域。
这种协同作用使得MF能够生成更丰富、更有信息量的图像,从而提升OD的性能,而OD则为MF提供了有价值的目标语义信息,从而准确地定位和识别场景中的物体。
通常,MFD网络采用一种级联设计,其中联合优化技术使用OD网络来引导MF网络创建便于目标检测的图像。
但是依旧存在以下问题:
1)当前的优化方法依赖于多步骤、渐进的联合方法,影响训练效率;
2)这些方法过于依赖目标检测(OD)信息来增强融合,导致参数平衡困难并易于陷入单个任务的局部最优解。
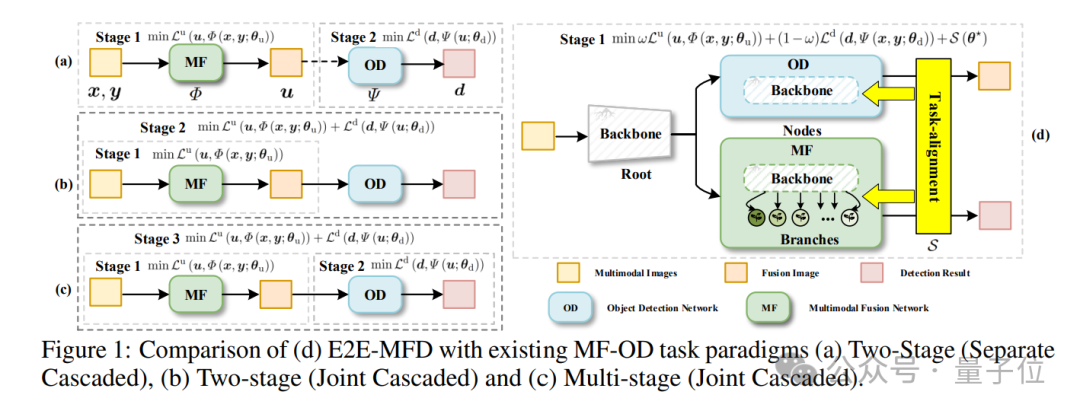
因此,寻求一个统一的特征集,同时满足每个任务的需求,仍然是一项艰巨的任务。
为此,研究提出了一种名为E2E-MFD的端到端多模态融合检测算法。
(1)这是一种高效同步联合学习的方法,将图像融合和目标检测创新性地整合到一个单阶段、端到端的框架中,这种方法显著提升了这两项任务的成果。
(2)引入了一种新的GMTA技术,用于评估和量化图像融合与目标检测任务的影响,帮助优化训练过程的稳定性,并确保收敛到最佳的融合检测权重配置。
(3)通过对图像融合和目标检测的全面实验验证,展示了所提出方法的有效性和稳健性。在水平目标检测数据集M3FD和有向目标检测数据集DroneVehicle上与最先进的融合检测算法相比,E2E-MFD表现出强大的竞争力。
其整体架构如下:
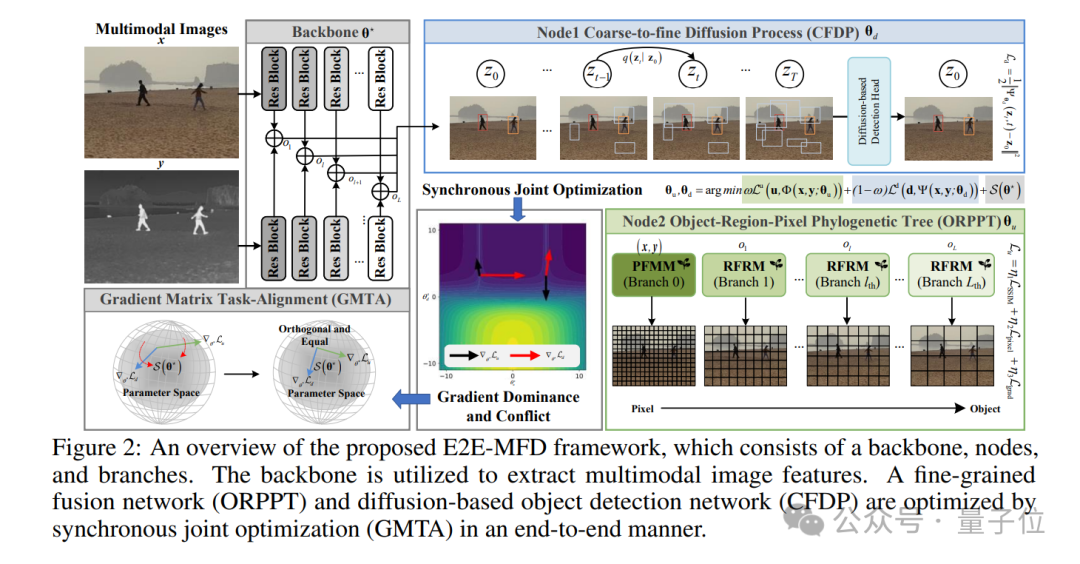
展开来说,E2E-MFD通过同步联合优化,促进来自两个领域的内在特征的交互,从而实现简化的单阶段处理。
为了协调细粒度的细节与语义信息,又提出了一种全新的对象-区域-像素系统发育树(ORPPT)概念,并结合粗到细扩散处理(CFDP)机制。
该方法受视觉感知自然过程的启发,专为满足多模态融合(MF)和目标检测(OD)的具体需求而设计。
此外,研究引入了梯度矩阵任务对齐(GMTA)技术,以微调共享组件的优化,减少传统优化过程中固有的挑战。
这确保了融合检测权重的最优收敛,增强了多模态融合检测任务的准确性和有效性。
实验
实验细节
E2E-MFD在多个常用数据集(TNO、RoadScene、M3FD 和 DroneVehicle)上进行了实验,实验运行在一张 GeForce RTX 3090 GPU上。
模型基于PyTorch框架实现,部分代码在M3FD数据集上使用了Detectron2框架,并通过预训练的DiffusionDet初始化目标检测网络。
优化器采用AdamW,批量大小为1,学习率设为2.5×10⁻⁵,权重衰减为1e-4。
模型共训练了15,000次迭代。
在DroneVehicle数据集上,实验基于MMRotate 0.3.4框架,使用预训练的LSKNet模型进行初始化,并通过12个 epoch的微调进行优化,批量大小为4。
实验结果
研究提供了不同融合方法在TNO、RoadScene和M3FD数据集上的定量结果。
模型的训练(Tr.)和测试(Te.)时间均在NVIDIA GeForce RTX 3090上统计。
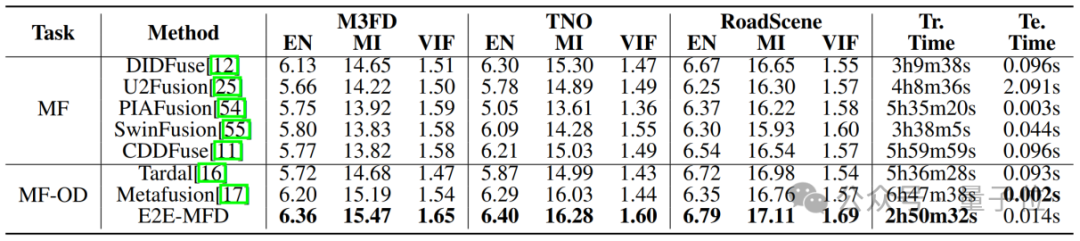
可以看出,E2E-MFD在MI指标上普遍获得了最佳度量值,表明其在信息传递方面比其他方法从两个源图像中提取了更多有用的信息。
EN值进一步显示,E2E-MFD能够生成包含清晰边缘细节且对象与背景对比度最高的图像。
较高的VIF值则表明,E2E-MFD的融合结果不仅具有高质量的视觉效果,同时在失真度方面较低。
此外,该方法的训练时间最快,表明在新的数据集上能够实现更快速的迭代更新。
生成融合图像的测试时间在所有方法中排名第三。
定性结果如下图所示,所有融合方法均在一定程度上融合了红外和可见光图像的主要特征,但E2E-MFD具备两个显著优势。
首先,它能够有效突出红外图像的显著特征,例如在M3FD数据集中,E2E-MFD捕捉到了骑摩托车的人员。
与其他方法相比,E2E-MFD展示了更高的物体对比度和识别能力。
其次,它保留了可见图像中的丰富细节,包括颜色和纹理。
在M3FD数据集中,E2E-MFD的优势尤为明显,比如能够清晰显示白色汽车的后部以及骑摩托车的人。
E2E-MFD在保留大量细节的同时,保持了图像的高分辨率,并且没有引入模糊现象。而其他方法则未能同时实现这些优势。
为了更有效地评估融合图像对下游检测任务的影响,研究在M3FD数据集上使用了YOLOv5s检测器对所有SOTA方法进行了测试,结果如表所示。
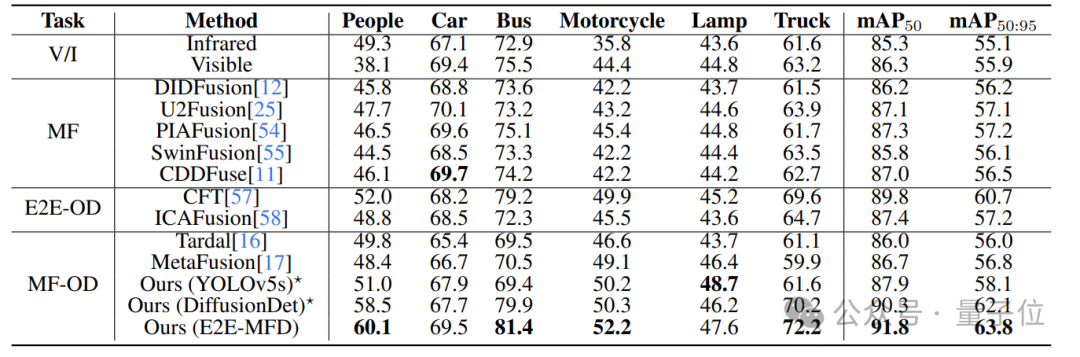
与单模态检测相比,SOTA方法在融合图像上的表现明显提升,表明良好融合的图像能够有效地支持下游检测任务。
E2E-MFD生成的融合图像在YOLOv5s检测器上表现最佳,同时在DiffusionDet检测器上也取得了出色的成绩。
即使与端到端目标检测方法(E2E-OD)相比,E2E-MFD的方法仍显示出了显著的性能提升,充分证明了其训练范式和方法的有效性。
检测结果的可视化如下图所示。
当仅使用单模态图像作为输入时,检测结果较差,常常漏检诸如摩托车和骑手等目标,尤其是在图像右侧靠近汽车和行人的区域。
几乎所有的融合方法都通过融合两种模态的信息,减少了漏检现象并提升了检测的置信度。
通过设计端到端的融合检测同步优化策略,E2E-MFD生成了在视觉上和检测上都非常友好的融合图像,尤其在处理遮挡和重叠的目标时表现出色,比如图像右侧蓝色椭圆中的摩托车和重叠的行人。
在DroneVehicle数据集上的目标检测定量结果多模态如表所示,E2E-MFD达到了最高的精度。
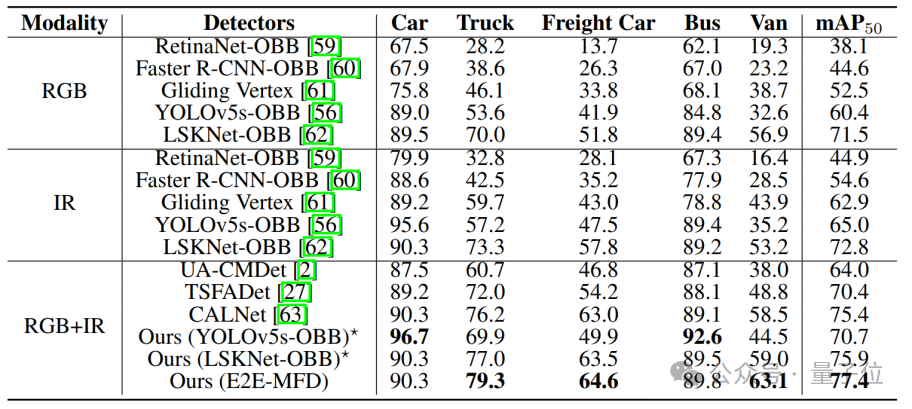
此外,使用生成的融合图像在YOLOv5s-OBB和LSKNet上进行检测时,较单一模态至少提高了5.7%和3.1%的AP值,验证了方法的鲁棒性。
这证明了融合图像的优异质量,表明它们不仅在视觉上令人满意,还为检测任务提供了丰富的信息。
小结
研究提出了多模态融合检测算法E2E-MFD,仅以单步训练过程同时完成融合和检测任务。
引入了一个系统发育树结构和粗到细扩散处理机制,来模拟在不同任务需求下,不同视觉感知中需要完成的这两项任务。
此外,研究对融合检测联合优化系统中的任务梯度进行了对齐,消除联合优化过程中两个任务的梯度优化冲突。
通过将模型展开到一个设计良好的融合网络和检测网络,可以以高效的方式生成融合与目标检测的视觉友好结果,而无需繁琐的训练步骤和固有的优化障碍。
-
E2EMail端到端加密系统2022-05-20 666
-
技术分享 |多模态自动驾驶混合渲染HRMAD:将NeRF和3DGS进行感知验证和端到端AD测试2025-03-26 4653
-
《多模态大模型 前沿算法与实战应用 第一季》精品课程简介2026-05-01 228
-
【完结】多模态与视觉大模型开发实战 - 2026必会2026-07-11 35
-
姿态融合算法是什么2019-07-19 5024
-
ADPD4000/ADPD4001:多模态传感器端数据Sheet2021-05-11 943
-
多模态MR和多特征融合的GBM自动分割算法2021-06-27 1205
-
罗德与施瓦茨成功验证10Gbps端到端(E2E)峰值下行链路IP数据吞吐量2021-10-27 2536
-
Autosar E2E介绍及其实现2023-09-22 7448
-
自主工具链助力端到端组合辅助驾驶算法验证2025-08-26 3500
-
Om AI联汇VLX发布 全球首个物理世界端侧流式多模态落地2026-07-02 716
全部0条评论

快来发表一下你的评论吧 !
