

SegVG视觉定位方法的各个组件
描述
动机
视觉定位(Visual Grounding)旨在基于自由形式的自然语言文本表达定位图像中的目标物体。随着多模态推理系 统的普及,如视觉问答和图像描述,视觉定位的重要性愈加凸显。已有的研究大致可以分为三类:两阶段方法、单 阶段方法和基于变换器(Transformer)的方法。尽管这些方法取得了良好的效果,但在注释的利用上仍显得不 足,尤其是仅将框注释作为回归的真值样本,限制了模型的性能表现。
具体而言,视觉定位面临的挑战在于其稀疏的监督信号,每对文本和图像仅提供一个边界框标签。这与目标检测任 务(Object Detection)存在显著不同,因此充分利用框注释至关重要,将其视为分割掩膜(即边界框内的像素赋 值为1,外部像素赋值为0),可以为视觉定位提供更细粒度的像素级监督。
在本研究中,提出了一个名为SegVG的新方法,旨在将边界框级的注释转化为分割信号,以提供更为丰富的监督信 号。该方法倡导多层多任务编码器-解码器结构,学习回归查询和多个分割查询,以通过回归和每个解码层的分割来 实现目标定位。此外,为了解决由于特征域不匹配而产生的差异,研究中引入了三重对⻬模块,通过三重注意机制 更新查询、文本和视觉特征,以确保它们共享同一空间,从而提高后续的目标检测效果。
综上,SegVG通过最大化边界框注释的利用,提供了额外的像素级监督,并通过三重对⻬消除特征之间的域差异, 这在视觉定位任务中具有重要的创新意义。以下是来自论文中的相关图示,用以进一步说明视觉定位框架的不同:
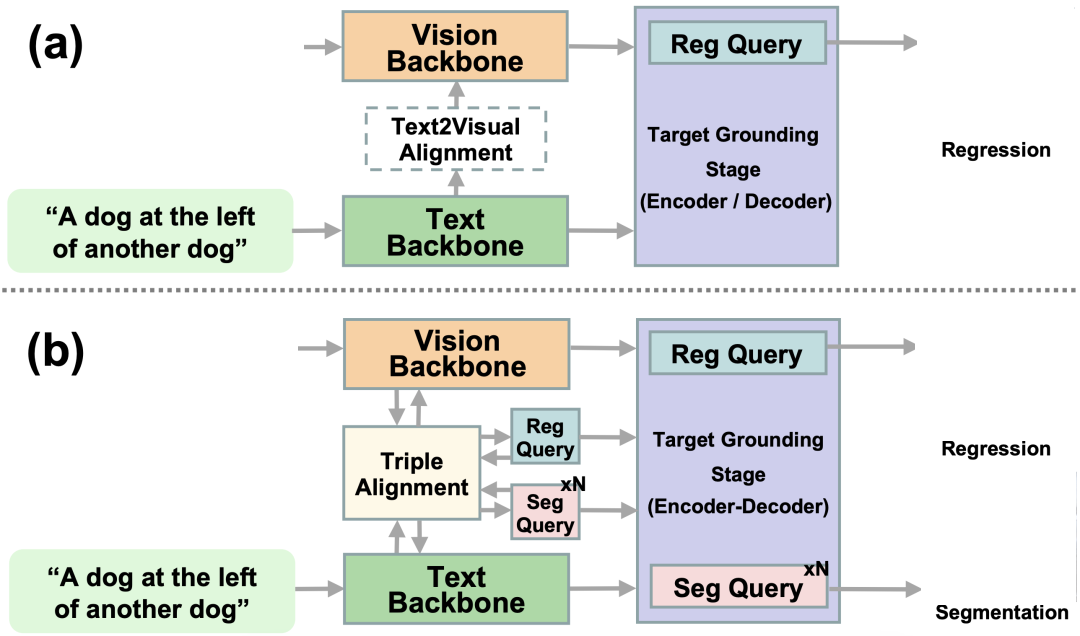
方法
在本节中,介绍了SegVG方法的各个组件,按数据流的顺序进行说明,包括⻣干网络、Triple Alignment模块以及 Multi-layer Multi-task Encoder-Decoder。
⻣干网络
SegVG方法的视觉⻣干网络和文本⻣干网络分别处理图像和文本数据。视觉⻣干网络使用的是经过Object Detection任务在MSCOCO数据集上预训练的ResNet和DETR的Transformer编码器。文本⻣干网络使用BERT的嵌入层将输入文本转换为语言Token。在Token前添加一个[CLS] 标记,并在末尾添加一个[SEP]标记,随后通过BERT层迭代处理得到语言嵌入 。
Triple Alignment
Triple Alignment模块致⼒于解决视觉⻣⼲、⽂本⻣⼲和查询特征之间的域差异。该模块利⽤注意⼒机制执⾏三⻆形特征采样,确保查询、⽂本和视觉特征之间的⼀致性。输⼊的查询 被初始化为可学习的嵌⼊,包含⼀个回归查询和多个分割查询。这⼀过程按以下⽅式进⾏:
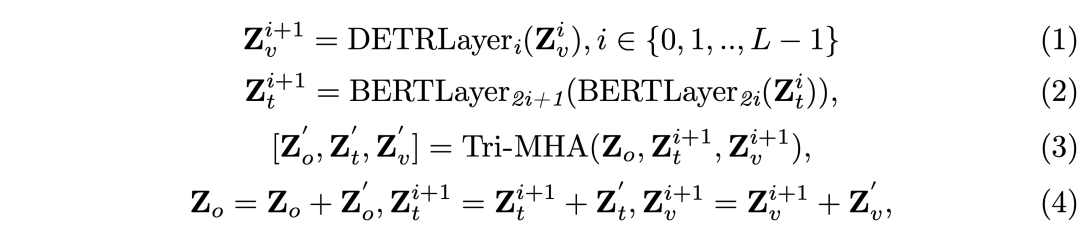
通过这种⽅式,Triple Alignmen模块能够在每⼀层迭代帮助三类特征实现有效地对⻬。
Multi-layer Multi-task Encoder-Decoder
Multi-layer Multi-task Encoder-Decoder是目标对接阶段的核心部分,旨在通过跨模态融合和目标对接同时执行边 框回归任务和边框分割任务。编码器部分融合了文本和视觉特征,每一层通过多头自注意力层(MHSA)和前馈网 络(FFN)过程实现提升。解码器部分则通过 bbox2seg范式将边框注释转化为分割掩码,分割掩码将框内的像素 标记为前景(值为1),而框外像素则标记为背景(值为0)。在每一解码层中,一个回归查询用于回归边框,多个 分割查询则用于对目标进行分割。
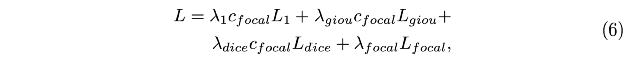
上述公式中,各种损失函数(如L1损失、GIoU损失、Focal损失和Dice损失)被结合用于驱动模型的训练过程,使 得模型在执行回归和分割任务时获得强化的反馈。
通过将分割输出的信心值转化为Focal损失因子,可以有效地强调那些难以训练的数据样本,以进一步提升模型的 性能。整体而言,SegVG方法实现了对边框注释的最大化利用,并有效解决了多模态特征间的域差异问题,为视觉 目标定位任务带来了重要的改进和提升。
实验
在实验部分,研究者对所提出的SegVG模型进行了全面的评估,涉及多个标准数据集和不同的实验设置,以验证其 有效性和优越性。
指标与数据集
研究者采用的主要评估指标是交并比(IoU)和前1准确率,以评估预测边界框与真实边界框的匹配程度。使用的标 准基准数据集包括RefCOCO、RefCOCO+、RefCOCOg-g、RefCOCOg-umd以及Refer It Game等。
实施细节
研究中对数据输入进行了特别配置,使用640x640的图像大小,以及最大文本⻓度设定为40。当图像大小调整时, 会保持原始宽高比。模型的训练过程采用AdamW优化器,及其学习率和权重衰减参数。
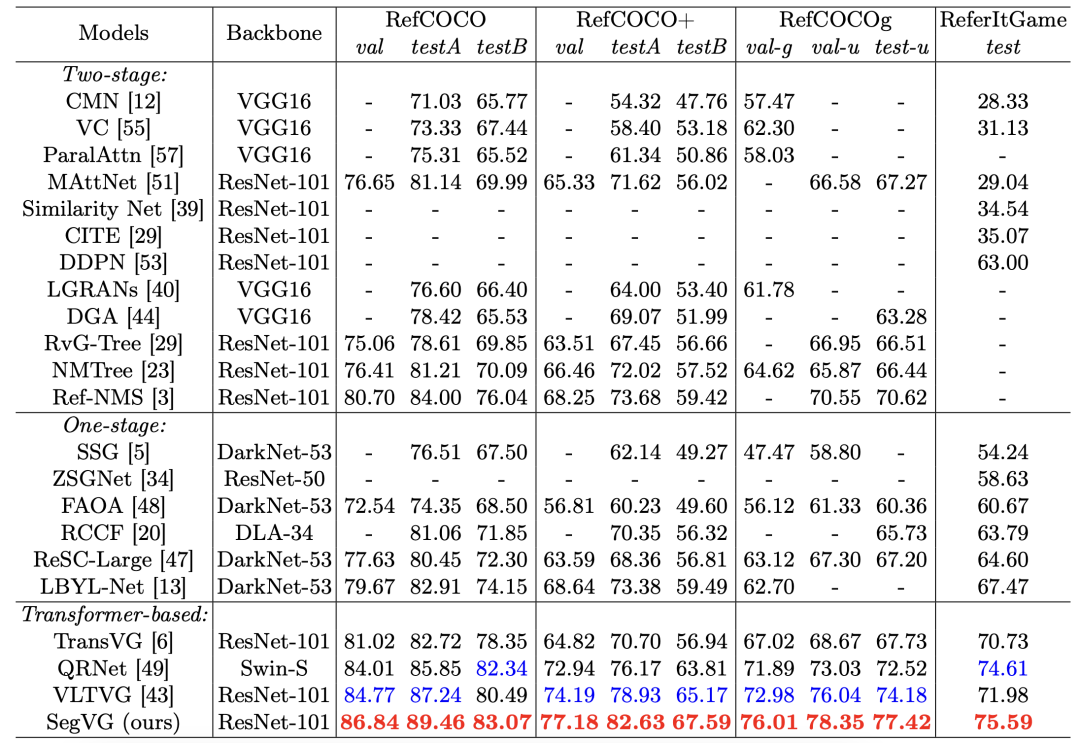
定量结果在定量实验中,SegVG模型在所有基准数据集中表现出色。例如,在RefCOCO+数据集上,其预先训练模型在各个 子集上相较于之前的最先进模型取得了显著提升,分别达到了2.99%、3.7%和2.42%的错误率下降。在RefCOCOg 数据集上,SegVG同样取得了+3.03%、+2.31%和+3.24%的改善。这些结果证明了结合Triple Alignment和Multi- layer Multi-task Encoder-Decoder后,模型在目标定位和准确性上的提升。
消融研究
进一步分析通过控制变量法对各个模块的有效性进行消融研究。研究显示,加入Triple Alignment模块后,可以有 效消除查询、文本及视觉特征之间的领域差异,进而促进后续的目标定位。此外,通过加入Multi-layer Multi-task 监督,能够迭代充分利用注释信息,从而增强查询表示的学习能力。

计算开销比较
研究者还对不同Transformer模型的参数数量和GFLOPS进行了比较,以评估SegVG的计算开销。结果表明,SegVG的计 算成本处于合理范围,符合实际应用需求。

定性结果
在定性分析中,通过对比不同模型在目标检测中的表现,SegVG在初始解码层阶段就能准确识别目标位置,相较于 对比模型VLTVG而言,表现更加稳健。具体案例中,SegVG成功定位复杂背景下的目标,显示了其在多任务优化时 的高度有效性。
-
基于labview机器视觉的图像定位2017-03-31 12381
-
视觉定位,旋转平移的问题:2019-09-01 3956
-
【HarmonyOS HiSpark AI Camera】视觉定位2020-11-23 782
-
视觉定位方案求助,谢2021-10-05 3167
-
基于视觉信标的仓储物流机器人定位方法2017-11-28 1218
-
用于移动机器人听觉和视觉一体的定位方法2017-12-18 1208
-
基于GEME-3000主控制器和计算机视觉组件实现自动化定位系统的设计2020-04-25 2647
-
医疗器械视觉定位应用2020-05-22 3140
-
融合3D场景几何信息的视觉定位算法2020-11-13 6236
-
基于计算机视觉的客机舱门识别与定位方法2021-06-22 1348
-
【技术干货】光伏组件生产全流程AI视觉检测方案来了!2023-01-13 3013
-
六自由度视觉定位2023-04-20 2035
-
机器视觉检测与机器视觉定位的区别与应用2023-05-30 2134
-
激光焊接视觉定位引导方法2024-05-28 1599
-
一种将NeRFs应用于视觉定位任务的新方法2024-10-28 1368
全部0条评论

快来发表一下你的评论吧 !
