

关于 Unicode 所有开发者都应该知道的前五件事 并用来防止欺诈
描述
2017年11月 BBC 报道了一个假冒 WhatsApp 的新闻。假应用似乎与官方应用属于同一个开发者名下。原来这些骗子通过在开发者名字中加入 Unicode 的非打印空格(nonprintable space),绕开验证。在 Google Play 维护人员发现之前,下载假应用超过 100 万人。
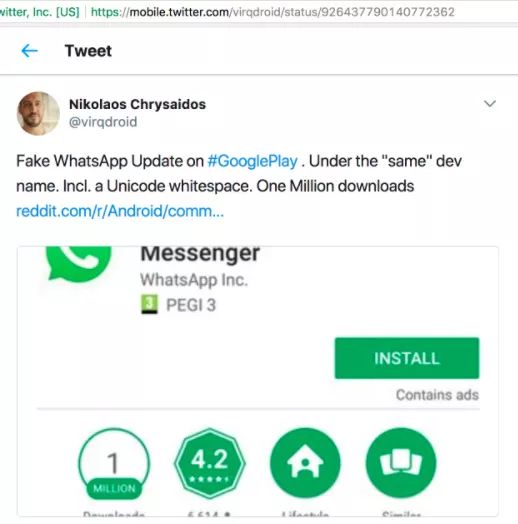
Unicode 是极其有价值的标准,使得电脑、智能手机和手表,在全球范围内以同样的方式显示同样的消息。不幸的是,它的复杂性使其成为了骗子和恶作剧者的金矿。如果像 Google 这样的巨头都不能抵御 Unicode 造成的基本问题,那对小一点的公司来说,这可能就像是必输的战役了。然而,大多数这些问题都是围绕着几个漏洞利用的。以下是关于 Unicode 所有开发者都应该知道的前五件事,并用来防止欺诈。
1. 很多 Unicode 代码点是不可见的
Unicode 中有一些零宽度代码点,例如零宽度连接器(U+200D)和零宽度非连接器(U+200C),它们都暗示了连字符工具。零宽度代码点对屏幕显示没有可见的影响,但是它们仍会影响字符串比较。这也是假 WhatApp 应用的骗子能这么长时间不被发现的原因。这些字符大多数都在一般标点符号区(从 U+2000 到 U+206F)。一般来说,没有理由允许任何人在标识符中使用这个区的代码点,所以它们是最不易过滤的。但是该区域外也有部分其他不可见的特别代码,比如蒙古文元音分隔符(U+180E)。
一般来说,用 Unicode 对唯一性约束做简单的字符串比较,这很危险的。有一个可能的解决方法,限制允许用作标识符及其他任何能被骗子滥用的数据的字符集。不幸的是,这并非该问题的彻底解决方法。
2. 很多代码点看起来很相似
Unicode 努力覆盖全世界书写语言中的所有符号,必然有很多看起来相似的字符。人类甚至无法把它们区分开来,但是电脑能毫不费力地识别出差别。对这个问题的一种令人惊讶的滥用是拟态(Mimic)。拟态是一项有趣的应用,将软件开发所使用的常见符号,例如冒号和分号,替换成相似的 Unicode 字符。这能在代码编译工具中制造混乱,留下一脸懵逼的开发者。

相似符号带来的问题,远不止是简单的恶作剧。花哨的叫法是 homomorphic attacks(同态攻击)。利用这些漏洞,会导致严重的安全问题。在 2017 年 4 月,一位安全研究员通过混合不同字符集中的字母,成功地注册了一个看起来与 apple.com 非常相似的域名,甚至为它拿到了 SSL 证书。各大浏览器都愉快地显示了 SSL 挂锁,将该域名列为安全域名。
与混合可见字符和不可见字符相似,没有道理允许标识符,尤其是域名,使用混合字符集名。大多数浏览器已经采取了行动,将混合字符集域名显示为十六进制的 unicode 值以对其进行处罚,这样用户就不会轻易地被迷惑。如果你向用户显示标识符,比如说在搜索结果中,考虑类似的方法来避免混淆。但是,这也不是完美的解决方法。某些域名可以轻易地用一个非拉丁字符集中的单单一个区来构建,比如 ap.com 或者 chase.com。
Unicode 协会出版了一张易混淆字符表,可能作为自动检查潜在诈骗的好参考。另一方面,如果你想找一个快速创造疑惑的方法,看看 Shapecatcher 吧。它是一个奇妙工具,列举了视觉上像图画的 Unicode 符号。
3. 规范化并不那么规范
规范化对像用户名这样的标识符来说非常重要,帮助人们用不同的方法输入值,但是用一致的方法来处理。规范标识符的一个常见方法是把所有字符都转变成小写,确保 JamesBond 和 jamesbond 是一样的。
因为有如此多的相似字符和交叉集,不同的语言或者 unicode 处理库,可能应用不同的规范化策略。如果在若干地方进行了规范化,会潜在地带来安全风险。简单来说,不要假设小写转换在应用软件中的不同部分是一样的。来自 Spotify 的 Mikael Goldmann 在他们的一名用户发现了一个盗用账户的方法后,于 2013 年针对这个问题写了一份事件分析。攻击者可以注册其他人用户名的变体,比如 BIGBIRD,会转换成标准的账户名 bigbird。该应用软件的不同层对单词的规范化不同,使得人们能够注册模仿账号,而重置目标账户的密码。
4. 屏幕显示长度和内存大小无关
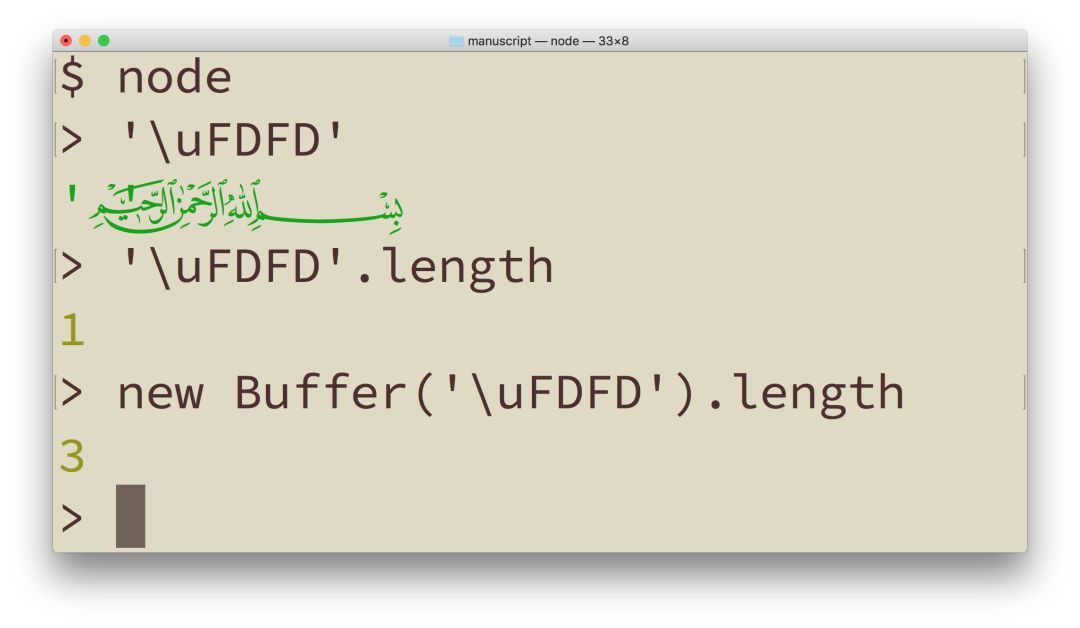
使用基础拉丁字符集和大多数欧洲字符集时,一段文本在屏幕或者纸上所占的空间大致与符号数成比例,大致与文本的内存大小成比例。这也是 EM 和 EN 成为流行长度单位的原因。但使用 Unicode 时,像这样任何种类的假设都会变得危险。有像 Bismallah Ar-Rahman Ar-Raheem (U+FDFD)这样可爱的字符,单单一个字符就比大多数英文单词都要长,能够轻易地超过网页上假定的视觉外框。这意味着基于字符串字符长度的任何种类的自动换行,或者文本中断算法都能轻易被愚弄。大多数终端程序要求固定宽度的字体,所以在这些程序中显示的话,你会看到右引号完全标在了错误的位置上。
该问题一种滥用是 zalgo 文本生成器,它在一段文本周围加上垃圾,让这些东西占据了更多的垂直空间。
当然了,整个不可见代码点的问题导致屏幕长度和内存大小无关。所以与输入区恰好合适的东西可能长到能摧毁一个数据库区。过滤不可见字符来规避问题还不够,因为还有很多不占用它们自己空间的其他例子。
混合占据前一个字母上的空间的拉丁字符(比如 U+036B 和 U+036C),这样你能在一行文本行中写多行文本(Nu036BOu036C 产生 NͫOͬ)。吟诵标记是用来示意吟唱希伯来圣经经文的语调的。这些吟诵标记能够在同样的视觉空间中无限堆叠,意味着他们能被轻易地滥用,将大量信息编写进屏幕上的一个字符空间。Martin Kleppe 用吟诵标记为浏览器编码了 Conway’s Game of Life 的实现。看看该页面的源代码吧,你会感到震惊的。
5. Unicode 远不止是被动数据
有些代码点是用来影响输出字符的显示方式的,意味着用户不仅可以复制粘贴数据,也能键入处理指令。一个常见恶作剧是,使用右到左覆盖(U+202E)来转变文本方向。例如,用谷歌地图搜索 Ninjas。该查询字符串实际上转换了搜索单词的方向,尽管页面上的搜索区域显示着“ninjas”,但是实际上搜索的是“sajnin”。
这种漏洞利用非常流行,XKCD 漫画网站上有一张相应漫画。

混合数据和处理指令——可有效执行的代码——不是个好主意,尤其是如果用户可以直接键入。这对任何在页面显示中包括的用户键入来说都是大问题。大多数网页开发者知道通过移除 HTML 标签来清理用户键入,但是也需要注意键入中的 Unicode 控制字符。这是个应对任何脏话或者内容过滤器的简单方法——只要把单词倒转过来,在开始加上右到左覆盖。
右到左(Right-to-left)hack 可能无法嵌入恶意代码,但是如果你不小心的话,它能扰乱内容或者翻转整个页面。抵御这个问题,常见方法是把用户提供的内容放进一个输入区域或者文本区域,这样处理指令不会影响页面。
处理指令对显示的另一个特别问题是字型变换选取器。为了避免为每种颜色的 emoji 创造单独的代码,Unicode 允许使用字型变换选取器来混合基本符号和颜色。白旗,字型变换选取器和彩虹正常会产生彩虹颜色的旗。但是并不是所有变换都可行。在 2017 年 1 月,iOS unicode 处理中的一个 bug 允许恶作剧者,仅仅发送一条特制信息就远程导致 iPhone 瘫痪。该信息包括白旗,字型变换选取器和一个零。iOS CoreText 陷入了恐慌模式,想要挑出正确的变换,导致了 OS 的瘫痪。这个恶作剧在直接信息,群聊甚至分享联系人名片中都奏效。这个问题也影响了 iPad,甚至部分 MacBook。该恶作剧针对的目标人群,面对系统崩溃,无能为力。
相似的 bug 每几年就发生一次。在 2013 年,出现了一个阿拉伯字符处理 bug,它能使 OSX 和 iOS 崩溃。所有这些 bug 都深深埋藏在 OS 文本处理模块里,所以典型客户端应用开发者根本无法躲开它们。
-
2016关于物联网应该知道的7件事2016-08-10 1262
-
[原创]每天做好一件事2010-05-31 412
-
什么叫做“每天6件事”,如何落实“每天6件事”2012-04-21 7239
-
调节 PID 都应该学习labview哪方面的内容2013-09-22 3669
-
15 年代码经验,总结出提升 10 倍效率的三件事!2017-10-14 2525
-
嵌入式驱动开发者设计前都应该了解的5个知识2017-12-06 2639
-
每一个嵌入式驱动开发者设计前都应该了解的5个窍门2017-12-18 2038
-
移动开发者应该知道的 8 个盈利技巧2012-08-01 822
-
更新iOS 10之前应该知道的六件事2017-01-06 891
-
整理了所有数据专家都应该会的七款Python工具2018-01-15 4753
-
硬件工程师都应该掌握防反接电路,你都Get到了吗?2020-02-03 5869
-
GitHub重向伊朗开发者打开大门2021-01-12 2543
-
关于MIMO技术您应该知道的10件事2021-06-16 1094
-
为ADAS构建时需要考虑的6件事说明2021-09-22 1090
-
关于隔离器件,你需要知道的三件事2022-10-28 869
全部0条评论

快来发表一下你的评论吧 !
