

数据挖掘Apriori算法报告
编程实验
描述
一、关联算法简介
关联规则的目的在于在一个数据集中找出项之间的关系,也称之为购物蓝分析 (market basketanalysis)。例如,购买鞋的顾客,有10%的可能也会买袜子,60%的买面包的顾客,也会买牛奶。这其中最有名的例子就是“尿布和啤酒”的故事了。关联规则的应用场合。在商业销售上,关联规则可用于交叉销售,以得到更大的收入;在保险业务方面,如果出现了不常见的索赔要求组合,则可能为欺诈,需要作进一步的调查。在医疗方面,可找出可能的治疗组合;在银行方面,对顾客进行分析,可以推荐感兴趣的服务等等。Apriori algorithm是关联规则里一项基本算法。
二、关联算法的基本原理
该算法的基本思想是:首先找出所有的频集,这些项集出现的频繁性至少和预定义的最小支持度一样。然后由频集产生强关联规则,这些规则必须满足最小支持度和最小可信度。然后使用第1步找到的频集产生期望的规则,产生只包含集合的项的所有规则,其中每一条规则的右部只有一项,这里采用的是中规则的定义。一旦这些规则被生成,那么只有那些大于用户给定的最小可信度的规则才被留下来。为了生成所有频集,使用了递推的方法

三、关联算法的C++简单实现
(1)算法数据:
对给定数据集用Apriori算法进行挖掘,找出其中的频繁集并生成关联规则。对下面数据集进行挖掘:
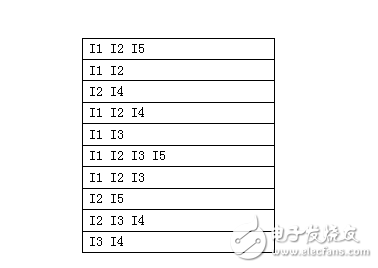
对于数据集,取最小支持度minsup=2,最小置信度minconf=0.8。
(2)算法步骤:
① 首先单趟扫描数据集,计算各个一项集的支持度,根据给定的最小支持度闵值,得到一项频繁集L1。
② 然后通过连接运算,得到二项候选集,对每个候选集再次扫描数据集,得出每个候选集的支持度,再与最小支持度比较。得到二项频繁集L2。
③ 如此进行下去,直到不能连接产生新的候选集为止。
④ 对于找到的所有频繁集,用规则提取算法进行关联规则的提取。
(3)C++算法的简单实现
①首先要在工程名文件夹里自己定义date.txt文档存放数据,然后在main函数中用FILE* fp=fopen(“date.txt”,“r”);将数据导入算法。
②定义int countL1[10];找到各一维频繁子集出现的次数。
定义char curL1[20][2];实现出现的一维子集。
由于给出的数据最多有4个数,所以同样的我们要定义到4维来放数据。
int countL2[10]; //各二维频繁子集出现的次数
char curL2[20][3]; //出现的二维子集
int countL3[10]; //各三维频繁子集出现的次数
char curL3[20][4]; //出现的三维子集
char cur[50][4];
③定义int SizeStr(char* m) 得到字符串的长度。实现代码如下:
int SizeStr(char* m)
{
int i=0;
while(*(m+i)!=0)
{
i++;
}
return i;
}
④比较两个字符串,如果相等返回true,否则返回false
bool OpD(char* x,char* y)
{
int i=0;
if(SizeStr(x)==SizeStr(y))
{
while(*(x+i)==*(y+i))
{
i++;
if(*(x+i)==0 && *(y+i)==0)
return true;
}
}
return false;
}
⑤通过void LoadItemL1(char **p) 得到所有1元的字串和各自出现的次数
void LoadItemL1(char **p)
{
int i,j,n=0,k=0;
char ch;
char* s;
int f;
memset(cur,0,sizeof(cur));
for(i=0;i《20;i++)
{
curL1[i][0]=0;
curL1[i][1]=0;
}
for(j=0;j《10;j++)
countL1[j]=0;
for(i=0;i《10;i++)
for(j=0;j《4;j++)
{
ch=*(*(p+i)+j);
if(ch==0)
break;
cur[n][0]=ch;
n++;
}
curL1[0][0]=cur[0][0];
curL1[0][1]=cur[0][1];
k=0;
for(i=0;i《50;i++)
{
if(cur[i]==0)
break;
s=cur[i];
f=1;
for(j=0;j《=k;j++)
{
if(OpD(s,curL1[j]))
{
f=0;
break;
}
}
if(f==1)
{
++k;
curL1[k][0]=cur[i][0];
curL1[k][1]=cur[i][1];
}
}
for(i=0;i《20;i++)
for(j=0;j《50;j++)
{
char* m;
m=curL1[i];
if(*m==0)
break;
if(OpD(m,cur[j]))
countL1[i]++;
}
printf(“L1: \n ”);
printf(“项集 支持度计数\n”);
for(i=0;i《10;i++)
{
if(curL1[i]==0)
break;
if(countL1[i]》=2)
printf(“{I%s}: %d\n”,curL1[i],countL1[i]);
}
}
⑥通过void SubItem2(char **p) 得到所有的2元子串
void SubItem2(char **p)
{
int i,j,k,n=0;
char* s;
memset(cur,0,sizeof(cur));
for(i=0;i《20;i++)
{
curL2[i][0]=0;
curL2[i][1]=0;
curL2[i][2]=0;
}
for(i=0;i《10;i++)
countL2[i]=0;
for(k=0;k《10;k++)
{
s=*(p+k);
if(SizeStr(s)《2)
continue;
for(i=0;i《SizeStr(s);i++)
for(j=i+1;j《SizeStr(s);j++)
{
if(*(s+j)==0)
break;
*(cur[n]+0)=*(s+i);
*(cur[n]+1)=*(s+j);
*(cur[n]+2)=0;
*(cur[n]+3)=0;
n++;
}
}
}
⑦通过void LoadItemL2(char **p) 得到各个2元频繁子串出现的次数
void LoadItemL2(char **p)
{
int k,i,j;
char* s;
int f;
SubItem2(p);
curL2[0][0]=cur[0][0];
curL2[0][1]=cur[0][1];
curL2[0][2]=cur[0][2];
k=0;
for(i=0;i《50;i++)
{
if(cur[i]==0)
break;
s=cur[i];
f=1;
for(j=0;j《=k;j++)
{
if(OpD(s,curL2[j]))
{
f=0;
break;
}
}
if(f==1)
{
++k;
curL2[k][0]=cur[i][0];
curL2[k][1]=cur[i][1];
curL2[k][2]=cur[i][2];
}
}
for(i=0;i《20;i++)
for(j=0;j《50;j++)
{
s=curL2[i];
if(*s==0)
break;
if(OpD(s,cur[j]))
countL2[i]++;
}
printf(“L2: \n”);
printf(“项集 支持度计数\n”);
for(i=0;i《10;i++)
{
if(curL2[i]==0)
break;
if(countL2[i]》=2)
printf(“{I%c,I%c}: %d\n”,curL2[i][0],curL2[i][1],countL2[i]);
}
}
⑧通过定义void SubItem3(char **p) 得到所有3元的子串
void SubItem3(char **p)
{
char *s;
int i,j,h,m;
int n=0;
memset(cur,0,sizeof(cur));
for(j=0;j《20;j++)
{
curL3[j][0]=0;
curL3[j][1]=0;
curL3[j][2]=0;
curL3[j][3]=0;
}
for(i=0;i《10;i++)
countL3[i]=0;
for(m=0;m《10;m++)
{
s=*(p+m);
if(SizeStr(s)《3)
continue;
for(i=0;i《SizeStr(s);i++)
for(j=i+1;j《SizeStr(s);j++)
{
for(h=j+1;h《SizeStr(s);h++)
{
if(*(s+h)==0)
break;
*(cur[n]+0)=*(s+i);
*(cur[n]+1)=*(s+j);
*(cur[n]+2)=*(s+h);
*(cur[n]+3)=0;
n++;
}
}
}
}
⑨同样我们要得到得到各个3元频繁子串出现的次数
void LoadItemL3(char** p)
{
int k,i,j;
char* s;
int f;
SubItem3(p);
curL3[0][0]=cur[0][0];
curL3[0][1]=cur[0][1];
curL3[0][2]=cur[0][2];
curL3[0][3]=cur[0][3];
k=0;
for(i=0;i《50;i++)
{
if(cur[i]==0)
break;
s=cur[i];
f=1;
for(j=0;j《=k;j++)
{
if(OpD(s,curL3[j]))
{
f=0;
break;
}
}
if(f==1)
{
++k;
curL3[k][0]=cur[i][0];
curL3[k][1]=cur[i][1];
curL3[k][2]=cur[i][2];
curL3[k][3]=cur[i][3];
}
}
for(i=0;i《20;i++)
for(j=0;j《50;j++)
{
s=curL3[i];
if(*s==0)
break;
if(OpD(s,cur[j]))
countL3[i]++;
}
printf(“L3: \n”);
printf(“项集 支持度计数\n”);
for(i=0;i《10;i++)
{
if(curL3[i]==0)
break;
if(countL3[i]》=2)
printf(“{I%c,I%c,I%c}: %d\n”,curL3[i][0],curL3[i][1],curL3[i][2],countL3[i]);
}
}
⑩定义void LoadItemL4(char** p) 得到各个3元子串出现的次数
void LoadItemL4(char** p)
{
int i;
char* s;
int j=0;
for(i=0;i《10;i++)
{
s=*(p+i);
if(SizeStr(s)==4)
j++;
}
printf(“四维子集出现的次数: %d\n”,j);
printf(“没有四维的频繁子集,算法结束! \n”);
}
11通过void Support(char* w,int g) 得到关联规则,并输出结果
void Support(char* w,int g)
{
int i,j,k,n=0;
char* s;
float c=0.8,d=0;
memset(cur,0,sizeof(cur));
s=w;
for(i=0;i《SizeStr(s);i++)
{
*(cur[n]+0)=*(s+i);
*(cur[n]+1)=0;
*(cur[n]+2)=0;
*(cur[n]+3)=0;
n++;
}
for(i=0;i《SizeStr(s);i++)
for(j=i+1;j《SizeStr(s);j++)
{
if(*(s+j)==0)
break;
*(cur[n]+0)=*(s+i);
*(cur[n]+1)=*(s+j);
*(cur[n]+2)=0;
*(cur[n]+3)=0;
n++;
}
for(i=0;i《10;i++)
{
if(SizeStr(cur[i])==1)
{
for(j=0;j《10;j++)
{
if(OpD(cur[i],curL1[j]))
{
d=countL3[g]/(float)countL1[j];
if(d》=c)
printf(“{I%s}: %f”,curL1[i],d);
break;
}
}
}
if(SizeStr(cur[i])==2)
{
for(j=0;j《10;j++)
{
if(OpD(cur[i],curL2[j]))
{
d=countL3[g]/(float)countL2[j];
if(d》=c)
printf(“{I%c,I%c}: %f \n”,curL2[j][0],curL2[j][1],d);
break;
}
}
}
}
}
12最后通过main函数完成整过程序
int main(int argc, char* argv[])
{
int i=0,j=0,k;
char buf[10][6];
char* p[10];
char ch;
memset(buf,0,sizeof(buf));
FILE* fp=fopen(“date.txt”,“r”);
if(fp==NULL)
return 0;
ch=fgetc(fp);
while(ch!=EOF)
{
if(ch==0xa || ch==0xd)
{
i++;
ch=fgetc(fp);
j=0;
continue;
}
buf[i][j]=ch;
j++;
ch=fgetc(fp);
}
for(k=0;k《10;k++)
{
*(p+k)=buf[k];
}
LoadItemL1(p);
LoadItemL2(p);
LoadItemL3(p);
LoadItemL4(p);
printf(“产生关联规则: \n”);
printf(“非空子集: 置信度:\n”);
for(i=0;i《10;i++)
{
if(curL3[i]!=0 && countL3[i]》=2)
Support(curL3[i],i);
}
return 0;
}
(4)程序输出结果:
四、学习心得体会
关联算法基本原理学习思路简单,只需一步一步找出频集。再通过支持度算出可信度,如对于A—》C,support=support({A,C}),confidence= support({A,C})/support({A})。其中频繁子集的任何子集一定是频繁的,子集频繁父亲一定频繁。相对较难的的部分在于C++代码的实现部分依次实现各个频繁子集,完成整个程序。这学期在商务智能课中学习了数据挖掘的10大算法,数据挖掘十分经典,掌握好一个简单的算法要下很功夫,在今后的工作中一定可以用到,我很庆幸这学期能选到这个课,在这之前听说过数据挖掘但一直没有机会接触,原理容易理解但没接触到以前就没有想过这样考虑问题,学习这个课程以后无论是知识面,智力上都是一个跳跃。还有也提醒我要多复习C++问题的思考,这学期一直忙于网页编程,忘记了上学期说要复习C++数据结构的学习。希望以后还有机会能选到老师的课。
-
Python的Apriori算法和FP-Growth算法是什么2020-06-04 1668
-
从五个方面让你了解人工智能算法中的Apriori2018-07-05 2786
-
十大经典数据挖掘算法—Apriori2018-02-04 4495
-
Matlab关于Apriori算法设计2018-02-02 5562
-
简介Apriori算法并解析该算法的具体策略和步骤,给出Python实现代码2018-01-31 6534
-
数据挖掘常用的十大算法2017-12-29 27708
-
基于关联规则挖掘算法的用电负荷能效研究(ECALT和APRIORI算法)2017-10-30 1161
-
数据挖掘Apriori算法的改进2013-08-19 1164
-
关联规则Apriori算法的改进2011-05-13 994
-
基于关联规则的Apriori-Partition算法的可视化2010-01-15 1111
-
一种新的改进的Apriori算法2009-12-25 1101
-
Apriori算法的一种优化方法2009-04-10 1122
全部0条评论

快来发表一下你的评论吧 !
