

关于多语言及跨语言的语音识别技术叙述
人工智能
描述
在大多数传统的自动语音识别(automatic speech recognition,ASR)系统中,不同的语言(方言)是被独立考虑的,一般会对每种语言从零开始训练一个声学模型(acoustic model,AM)。这引入了几个问题。第一,从零开始为一种语言训练一个声学模型需要大量人工标注的数据,这些数据不仅代价高昂,而且需要很多时间来获得。这还导致了资料丰富和资料匮乏的语言之间声学模型质量间的可观差异。这是因为对于资料匮乏的语言来说,只有低复杂度的小模型能够被估计出来。大量标注的训练数据对那些低流量和新发布的难以获得大量有代表性的语料的语言来说也是不可避免的瓶颈。第二,为每种语言独立训练一个 AM 增加了累计训练时间。这在基于 DNN 的 ASR 系统中尤为明显,因为就像在第7章中所描述的那样,由于 DNN 的参数量以及所使用的反向传播(backpropagation,BP)算法,训练DNN要显著慢于训练混合高斯模型(Gaussian mixture models,GMM)。第三,为每种语言构建分开的语言模型阻碍了平滑的识别,并且增加了识别混合语言语音的代价。为了有效且快速地为大量语言训练精确的声学模型,减少声学模型的训练代价,以及支持混合语言的语音识别(这是至关重要的新的应用场景,例如,在香港,英语词汇经常会插入中文短语中),研究界对构建多语言 ASR 系统以及重用多语言资源的兴趣正在不断增加。
尽管资源限制(有标注的数据和计算能力两方面)是研究多语言 ASR 问题的一个实践上的原因,但这并不是唯一原因。通过对这些技术进行研究和工程化,我们同样可以增强对所使用的算法的理解以及对不同语言间关系的理解。目前已经有很多研究多语言和跨语言 ASR 的工作(例如 [265, 431])。在本章中,我们只集中讨论那些使用了神经网络的工作。
我们将在下面几节中讨论多种不同结构的基于DNN的多语言ASR(multilingualASR)系统。这些系统都有同一个核心思想:一个DNN的隐藏层可以被视为特征提取器的层叠,而只有输出层直接对应我们感兴趣的类别,就像第9章所阐述的那样。这些特征提取器可以跨多种语言享,采用来自多种语言的数据联合训练,并迁移到新的(并且通常是资源匮乏的)语言。通过把共享的隐藏层迁移到一个新的语言,我们可以降低数据量的需求,而不必从零训练整个巨大的DNN,因为只有特定语言的输出层的权重需要被重新训练。
12.2.1 基于Tandem或瓶颈特征的跨语言语音识别
大多数使用神经网络进行多语言和跨语言声学建模(multilingual and crosslingual acoustic modeling)的早期研究工作都集中在 Tandem 和瓶颈特征方法上[318, 326, 356, 383, 384]。直到文献 [73, 359] 问世以后,DNN-HMM 混合系统才成为大词汇连续语音识别(large vocabulary continuous speech recognition,LVCSR)声学模型的一个重要选项。如第10章中所述的,在 Tandem 或瓶颈特征方法中,神经网络可以用来进行单音素状态或三音素状态的分类,而这些神经网络的输出或隐藏层激励可以用作 GMM-HMM 声学模型的鉴别性特征。
由于神经网络的隐藏层和输出层都包含有对某个语言中音素状态进行分类的信息,并且不同的语言存在共享相似音素的现象,我们就有可能使用为一种语言(称为源语言)训练的神经网络中提取的Tandem或瓶颈特征来识别另一种语言(称为目标语言)。实验显示出当目标语言的有标注的数据很少时,这些迁移的特征能够获得一个更具有竞争力的目标语言的基线。用于提取Tandem或瓶颈特征的神经网路可以由多种语言训练[384],在训练中为每种语言使用一个不同的输出层(对应于上下文无关的音素),类似于图12.2所示。另外,多个神经网络可分别由不同的特征训练,例如,一个使用感知线性预测特征(PLP)[184],而其他的使用频域线性预测特征(frequency domain linear prediction or FDLP[15])。 提取自这些神经网络的特征可被合并来进一步提高识别正确率。
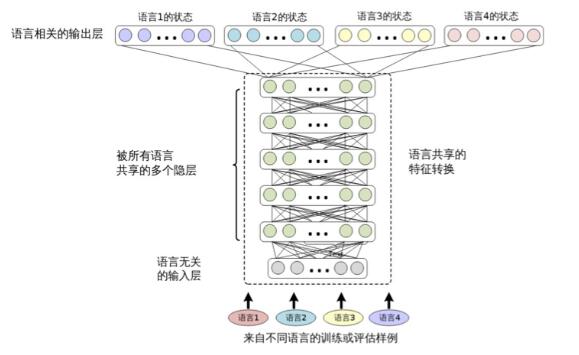
图 12.2 共享隐层的多语言深度神经网络的结构(Huang 等[204] 中有相似的图)
基于 Tandem 或瓶颈特征的方法主要用于跨语言 ASR 来提升数据资源匮乏的语言的ASR 性能。它们很少用于多语言 ASR。这是因为,即使使用同一个神经网络提取Tandem 或瓶颈特征,仍然常常需要为每种语言准备一个完全不同的 GMM-HMM 系 统。然而这个限制在多种语言共享相同的音素集(或者上下文相关的音素状态)以及决策树的情况下,就可能被移除,就像 [265] 中所做的那样。共享的音素集可以由领域知识确定,比如使用国际音素字母表(international phonetic alphabet,IPA)[14],或者通过数据驱动的方法,比如计算不同语言单音素和三音素状态间的距离[431]。
12.2.2 共享隐层的多语言深度神经网络
多语言和跨语言的自动语音识别可以通过 CD-DNN-HMM 框架轻松实现。图12.2描述了用于多语言 ASR 的结构。在文献 [204] 中,这种结构被称为共享隐层的多语言深度神经网络(SHL-MDNN)。因为输入层和隐层被所有的语言所共享,所以 SHL- MDNN 可以用这种结构进行识别。但是输出层并不被共享,而是每种语言有自己的 softmax 层来估计聚类后状态(绑定的三音素状态)的后验概率。相同的结构也在文献 [153, 180] 中独立地提出。
注意,这种结构中的共享隐层可以被认为是一种通用的特征变换或一种特殊的通用前端。就像在单语言的 CD-DNN-HMM 系统中一样,SHL-MDNN 的输入是一个较长的上下文相关的声学特征窗。但是,因为共享隐层被很多语言共用,所以一些语言相关的特征变换(如HLDA)是无法使用的。幸运的是,这种限制并不影响 SHL-MDNN 的性能,因为如第9章中所述,任何线性变换都可以被 DNN 所包含。
图 12.2中描述的 SHL-MDNN 是一种特殊的多任务学习方式[55],它等价于采用共享的特征表示来进行并行的多任务学习。有几个原因使得多任务学习比 DNN 学习更有利。第一,通过找寻被所有任务支持的局部最优点,多任务学习在特征表达上更具有通用性。第二,它可以缓解过拟合的问题,因为采用多个语言的数据可以更可靠地估计共享隐层(特征变换),这一点对资源匮乏的任务尤其有帮助。第三,它有助于并行地学习特征。第四,它有助于提升模型的泛化能力,因为现在的模型训练是包含了来自多个数据集的噪声。
虽然 SHL-MDNN 有这些好处,但如果我们不能正确训练 SHL-MDNN,也不能得到这些好处。成功训练 SHL-MDNN 的关键是同时训练所有语言的模型。当使用整批数据训练,如 L-BFGS 或 Hessian free[280] 算法时,这是很容易做到的,因为在每次模型更新中所有的数据都能被用到。但是,如果使用基于小批量数据的随机梯度下降
(SGD)训练算法时,最好是在每个小批量块中都包含所有语言的训练数据。这可以通过在将数据提供给 DNN 训练工具前进行随机化,使其包含所有语言的训练音频样本列表的方式高效地实现。
在文献 [153] 中提出了另一种训练方法。在这种方法中,所有的隐层首先用第5章提到的无监督的 DBN 预训练方式训练得到。然后一种语言被选中,随机初始化这种语言对应的 softmax 层,并将其添加到网络中。这个 softmax 层和整个 SHL-MDNN 使用这种语言的数据进行调整。调整之后,softmax层被下一种语言对应的随机初始化的 softmax 代替,并且用那种语言的数据调整网络。这个过程对所有的语言不断重复。这种语言序列训练方式的一个可能的问题是它会导致有偏差的估计,并且与同时训练相比,性能会下降。
SHL-MDNN 可以用第5章介绍的生成或鉴别性的预训练技术进行预训练。SHL-MDNN的调整可以使用传统的反向传播(BP)算法。但是,因为每种语言使用了不同的softmax层,算法需要一些微调。但一个训练样本给到SHL-MDNN训练器时,只有共享的隐层和指定语言的 softmax 层被更新。其他 softmax 层保持不变。
训练之后,SHL-MDNN 可以用来识别任何训练中用到的语言。因为在这种统一的结构下多种语言可以同时解码,所以SHL-MDNN 令大词汇连续语言识别任务变得轻松和高效。如图12.3所示,在 SHL-MDNN 中增加一种新语言很容易。这只需要在已经存在的SHL-MDNN 中增加一个新的 softmax 层,并且用新语言训练这个新加的softmax 层。
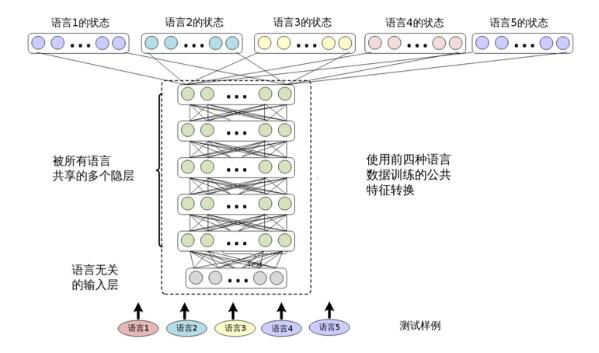
图 12.3 用四种语言训练的 SHL-MDNN 支持第五种语言
在 SHL-MDNN 中通过共享隐层和联合训练策略,相比只使用单一语言训练得到的单语言 DNN,SHL-MDNN 可以提高所有可解码语言的识别准确率。微软内部对 SHL-MDNN 进行了实验评估[204]。实验中的 SHL-MDNN 有5个隐层,每层有2048个神经元。DNN的输入是11(5-1-5)帧带一阶和二阶差分的13维MFCC特征。使用138小时的法语(FRA)、195小时的德语(DEU)、63小时的西班牙语(ESP)和63小时的意大利语(ITA)数据进行训练。对一种语言,输出层包含1800个三音素的聚类状态(即输出类别),它们是由用相同训练集和最大似然估(MLE)训练得到的GMM-HMM系统确定的。SHL-MDNN使用无监督的DBN预训练方法初始化,然后用由MLE模型对齐的聚类后的状态进行BP算法调整模型。训练得到的DNN之后被用到第6章介绍的CD-DNN-HMM框架中。
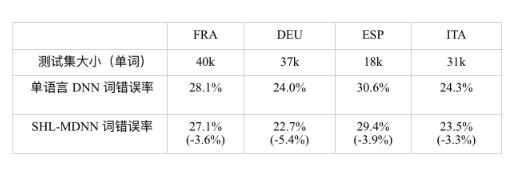
表 12.1比较了单语言 DNN 和共享隐层的多语言 DNN 的词错误率(WER),单 语言 DNN 只使用指定语言的数据训练,并用这种语言的测试集测试,SHL-MDNN 的隐层由所有的四种语言的数据训练得到。从表 12.1中可以观察到,在所有的语言 中,SHL-MDNN 比单语言 DNN 有 3% ~ 5% 相对 WER 减少。我们认为来自 SHL- MDNN 的提升是因为跨语言知识。即使是有超过 100 小时训练数据的 FRA 和 DEU, SHL-MDNN 仍然有提升。
表 12.1 比较单语言 DNN 和共享隐层的多语言 DNN 的词错误率(WER);括号中的是 WER 的相对减少。
12.2.3 跨语言模型迁移
从多语言 DNN 中提取的共享隐层可以被看作一种由多个源语言联合训练得到的 特征提取模块。因此,它们富有识别多种语言的语音类别的信息,并且可以识别新语 言的音素。
跨语言模型迁移的过程很简单。我们仅提取 SHL-MDNN 的共享隐层,并在其上 添加一个新的 softmax 层,如图 12.4所示。softmax 层的输出节点对应目标语言聚类后 的状态。然后我们固定隐层,用目标语言的训练数据来训练 softmax 层。如果有足够 的训练数据可用,还可以通过进一步调整整个网络得到额外的性能提升。
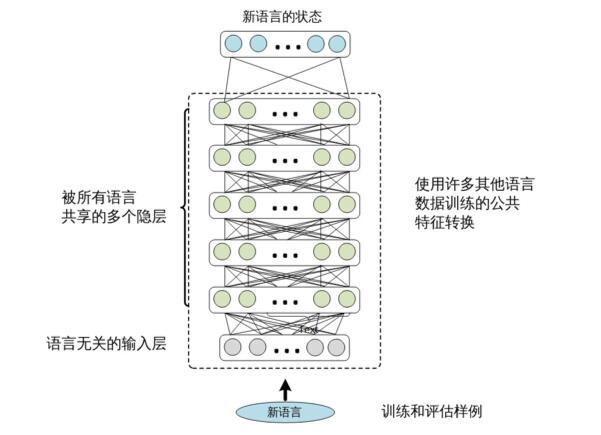
图 12.4 跨语言迁移。隐层从多语言 DNN 中借来,而 softmax 层需要用目标语言的数 据训练。
为了评估跨语言模型迁移的效果,文献 [204] 中做了一系列实验。这些实验中,两 种不同的语言被用作目标语言:与12.2.2节中训练 SHL-MDNN 的欧洲语言相近的美式英语(ENU)和与欧洲语言相差较远的中文普通话(CHN)。ENU 测试集包括 2286
句话(或 18000 个词),CHN 测试集包括 10510 句话(或 40000 个字符)。
隐层的可迁移性
第一个问题是隐层是否可以被迁移到其他语言上。为了回答这个问题,我们假设 9 小时美式英文训练数据(55737 句话)可以构建一个 ENU 的 ASR 系统。表 12.2总 结了实验结果。基线 DNN 只用 9 小时 ENU 训练集,这种方式达到了 ENU 测试集上 30.9% 的 WER。另一种方式是借用从其他语言中学到的隐层(特征变换)。在这个实 验中,一个单语言的 DNN 由 138 小时的法语数据训练得到。这个 DNN 的隐层随后被 提取并在美式英语 DNN 中复用。如果隐层固定,只用 9 小时美式英语数据训练 ENU 对应的 softmax 层,可以获得相对基线 DNN 的 2.6% 的 WER 减少(30.9%→27.3%)。 如果整个法语 DNN 用 9 小时美式英语数据重新训练,可以获得 30.6% 的 WER,这比 30.9% 的基线 WER 还要略微好一点。这些结果说明法语 DNN 的隐层所表示的特征变 换可以被有效地迁移以识别美式英语语音。
表 12.2 比较使用和不使用迁移自法语 DNN 的隐层网络在 ENU 测试集上的词错误率
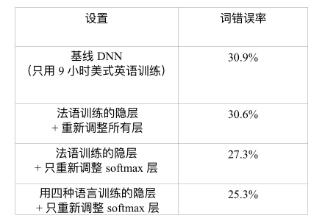
另外,如果在12.2.2节中描述的 SHL-MDNN 的共享隐层被提取并用在美式英语 DNN 中,可以得到额外 2.0% 的 WER 减少(27.3%→25.3%)。这说明在构造美式英语 DNN 时,提取自 SHL-MDNN 的隐层比提取自单独的法语 DNN 的隐层更有效。总之, 相对基线 DNN,通过使用跨语言模型迁移可以获得 4.6%(或相对的 18.1%)的 WER 减少。
目标语言训练集的大小
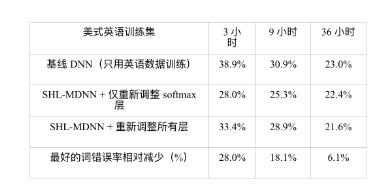
第二个问题是目标语言的训练集大小如何影响多语言 DNN 跨语言模型迁移的性 能。为了回答这个问题,Huang 等人做了一些实验,假设 3、9 和 36 小时的英语(目标语言)训练数据可用。文献 [204] 中的表 12.3总结了实验结果。从表中可以观察到, 利用迁移隐层的 DNN 始终好于不使用跨语言模型迁移的基线 DNN。我们也可以观察 到,当不同大小的目标语言数据可用时,最优策略会有所不同。当目标语言的训练数 据少于 10 小时,最好的策略是只训练新的 softmax 层。当数据分别为 3 小时和 9 小时 的时候,这么做可以看到 28.0% 和 18.1% 的 WER 相对减少。但是,当训练数据足够 多时,进一步训练整个 DNN 可以得到额外的错误减少。例如,当 36 小时的美式英语 语音数据可用时,我们观察到通过训练所有的层,可以获得额外的 0.8% 的 WER 减少(22.4%→21.6%)。
表 12.3 比较当隐层迁移自 SHL-MDNN 时,目标语言训练集大小对词错误率(WER) 的影响效果。
从欧洲语言到中文普通话的迁移是有效的
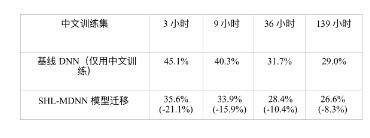
第三个问题是跨语言模型迁移方式的效果是否对源语言和目标语言之间的相似 性敏感。为了回答这个问题,Huang 等人[204] 使用了与训练 SHL-MDNN 的欧洲语言极 其不同的中文普通话(CHN)作为目标语言。文献 [204] 中的表 12.4列出了不同中文 训练集大小的情况下,使用基线 DNN 和经过多语言增强的 DNN 的字错误率(CER)。 当数据少于 9 小时的时候,只有 softmax 层被训练;当中文数据多于 10 小时的时候,所 有的层都被进一步调整。我们可以看到通过使用迁移隐层的方法,所有的 CER 都减少 了。即使有 139 小时的 CHN 训练数据可用,我们仍然可以从 SHL-MDNN 中获得 8.3% 的 CER 相对减少。另外,只用 36 小时的中文数据,我们可以通过迁移 SHL-MDNN 的共享隐层的方式在测试集上得到 28.4% 的 CER。这比使用 139 小时中文训练数据的 基线 DNN 得到 29% 的 CER 还好,节省了超过 100 小时的中文标注。
表 12.4 CHN 的跨语言模型迁移效果,由字错误率(CER)减少衡量;括号中是 CER 相 对减少。
使用标注信息的必要性
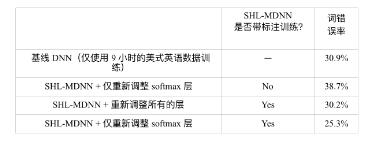
第四个问题是通过无监督学习提取的特征是否可以在分类任务上表现得和有监 督学习一样好。如果回答是可以,这种方法会有显著的优势,因为获取未标注的语音 数据比标注过的语音数据要容易很多。本节揭示出标注信息对于高效地学习多语言 数据的共享表示还是很重要的。基于文献 [204] 中的结果,表 12.5比较了在训练共享 隐层的时候,使用和不使用标注信息的两种系统。从表 12.5中可以发现,只使用预训 练过的多语言深度神经网络,然后使用 ENU 数据适应学习整个网络的方法,只得到 了很小的性能提升(30.9%→30.2%)。这个提升显著小于使用标注信息时得到的提升
(30.9%→25.3%)。这些结果清晰地表明,标注数据比未标注数据更有价值,同时,在 从多语言数据中学习高效特征时标注信息的使用非常重要。
表 12.5 对比在 ENU 数据上使用和不使用标注信息时从多语言数据上学习到的特 征。
-
京东多语言质量解决方案2026-01-13 1139
-
ChatGPT 的多语言支持特点2024-10-25 2517
-
大语言模型(LLMs)如何处理多语言输入问题2024-03-07 1562
-
多语言开发的流程详解2023-11-30 2074
-
如何在TSMaster面板和工具箱中实现多语言切换2023-11-11 2632
-
基于LLaMA的多语言数学推理大模型2023-11-08 1130
-
蚂蚁集团开源高性能多语言序列化框架Fury解读2023-08-25 2414
-
Multilingual多语言预训练语言模型的套路2022-05-05 4228
-
基于多语言的跨平台静态测试解决方案2022-03-03 1108
-
串口屏能否支持全球多语言功能?2019-03-27 1871
-
Mozilla使用开源Common Voice语音识别数据集进行多语言操作2018-06-12 5533
-
SoC多语言协同验证平台技术研究2015-12-31 1042
-
多语言综合信息服务系统研究与设计2009-04-01 496
全部0条评论

快来发表一下你的评论吧 !
