

介绍了C语言和机器语言的关系 以及其他类型语言的实现机制
电子说
描述
我们知道,任何编程语言编写的程序归根到底都是由底层机器的机器代码(01序列)执行的,无论是编译型语言还是解释型语言。而任何高级编程语言程序的源代码都是一个字符序列,这个字符序列到底层的01序列是通过编译器或解析器经过多次转换完成的。

图1 编程语言的层次结构
这个层次结构中,从高到低越来越接近于机器硬件。机器代码就是01序列,汇编语言就是描述本地机器的指令集体系结构,而高级语言就包含相应的数据结构和语法结构,更接近人类的语言习惯。因此,层次越高就越面向于人类。在计算机科学中,CPU被抽象为指令集体系结构,这个指令集描述了CPU所有完成的所有功能。所有的程序都经过编译或解释转化为这个指令集表示的机器程序。在指令集中指令可以按功能划分为:
1. 数据传输指令,用于读写内存、寄存器。
2. 算术与逻辑运算指令,比如:addl执行双字(32bit)的加法,andl双字的按位与。
3. 控制流指令,用于实现高级编程语言中的分支、循环等控制结构。
4. 过程调用指令,用于实现函数调用,分配、恢复栈帧等操作。
任何程序都需要被转换为某个指令集的指令序列,比如下列简单的求阶乘的C程序:
[cpp] view plaincopyprint?int fact_while(int n)
{
int result = 1;
while (n > 1) {
result *= n;
n = n-1;
}
return result;
}
在32bit机器上,经过gcc编译之后的x86指令序列为:
[plain] view plaincopyprint? movl 8(%ebp), %edx
movl $1, %eax
cmpl $1, %edx
jle .L7
.L10:
imull %edx, %eax
subl $1, %edx
cmpl $1, %edx
jg .L10
.L7:
通过观察C程序的机器代码可以发现由C程序转化为机器代码,主要有数据类型和控制结构的转换。下面以x86指令集说明:
1. 数据类型的转换:在底层,x86指令对于数据是不区分逻辑类型的,也就是不分int,float,double。所有的数据按照其所占的字节数被归类为字(16个字节,Word)、双字(32个字节,Double Words)、四字(64个字节,Quad Words)。一个指令操作的数据类型是由这个指令的后缀表示的,比如mov指令,movw操作字,movl操作双字。也就是说高级语言的程序中的不同数据类型反映到底层指令集上主要体现是指令的不同。比如,将上述C程序中的result类型改为short,在相应的汇编代码中的mov指令会由movl转换为movw。当然,还有一个问题就是C语言中的具体数据类型,在机器代码中是如何存储表示的。这应该是gcc编译器的职责,比如对于int,首先gcc需要知道底层指令集如何编码int,采用什么编码方式,字节顺序是Big-endian还是Little-endian等。在知道底层的实现方式后gcc才能将表示整型数字的字符串编码为相应的二进制形式。而对于数组、struct和union这些数据结构会转化为相应的内存地址加偏移量的形式。
2. 控制结构的转换:控制结构就是执行指令的流程。在x86中,所有的指令集都是顺序执行。要实现分支、循环等结构,必须具备go形式的跳转指令,以及相应的条件判断指令。CPU中有一组条件码寄存器,指示算术或逻辑运算的状态(计算结果是否溢出、为0或者是负数等)。执行条件运算指令可以测试一个条件,比如"cmpl $1, %edx"比较直接数1与寄存器%edx中存放的数的大小,并将结果存入条件码寄存器中。接下来执行条件跳转指令,根据条件码寄存器中的状态进行判断是否进行跳转。比如“jg .L10”是在前一条的cmpl指令结果返回大于的情况跳转到L10,否则执行下一条指令。
当然,在进行函数调用时,还要在底层用机器码对其进行描述。我们知道,计算机科学中用栈来实现函数的调用(叫做调用栈),栈中存放栈帧。每一次函数调用对应一个栈帧,栈帧中包含该方法的局部变量、保存的寄存器值等数据。这样函数的调用和返回就对应着栈帧的入栈和出栈。CPU的寄存器组中,有两个专门用于实现方法调用,分别是%esp和%ebp。%esp是栈指针寄存器,存放当前函数栈栈顶的内存地址。%ebp是帧指针寄存器,在%esp和%ebp之间的内存地址序列就对应于当前函数的栈帧。由于函数调用、返回与栈帧的关系很密切,所以可以将以此函数调用过程描述为:
1. 初始化被调用函数的栈帧,并将其入栈。也就是调用函数过程,通过call指令实现。
2. 执行被调用函数。
3. 恢复调用函数的栈帧,将被调用函数的栈帧出栈。也就是函数返回的过程,通过ret指令实现。
对于初始化、恢复栈帧实际上都是%esp和%ebp的调整,还要包括传参和返回值的问题,这些都是由编译器实现的。
上面介绍了C语言和机器语言的关系,下面看一下其他类型语言的实现机制。首先,我们可以把编程语言分为编译型语言、解释型语言和虚拟机语言。编译型语言直接被编译成本地机器代码,比如C、C++。解释型语言是通过解释器执行,比如javascript、shell、python等。虚拟机语言运行在虚拟机上,需要被编译成虚拟机代码,由虚拟机执行,比如java。虽然python也有自己的虚拟机,但是不需要编译,所以把它归类为解释型语言。
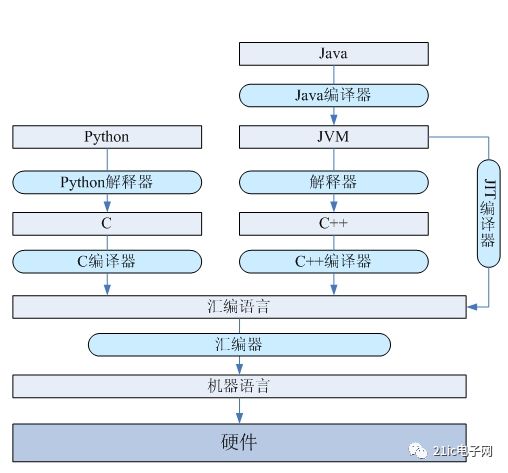
图2 编程语言实现结构
通过上文的分析、我们知道对于一门语言最重要的是数据类型、控制结构和语法结构以及系统调用。从上图可以看出,C和C++更接近于底层硬件,但是不能像汇编语言一样可以直接访问寄存器等硬件。而python和java相对于C和C++的抽象层次又高了一层,它们不能通过指针直接访问内存。从机器语言->汇编语言->系统语言(C和C++)->解释型语言(python)和虚拟机语言(java),抽象层次越来越高,越贴近于人的思维,不需要考虑那么多细节;同时,程序员的自由度和程序的运行速度越来越低。下面从低向高j讨论一下。
在底层,汇编语言会经过汇编器转换为机器代码。比如,通过gcc编译C程序时,会调用汇编器进行汇编。通过汇编器和汇编语言这一层次,可以很好的隔离底层机器硬件的实现细节。不同的处理器具有与之对应的汇编器,将汇编语言汇编成该处理器支持的指令集。这样就是实现了汇编语言这一层的移植性。
在C和C++系统编程语言这一层,会通过编译器完成语言元素到汇编语言的映射。比如前文描述的,数据类型、控制结构、函数调用等结构的转换。
python是解释型语言,它通过python解释器实现向底层语言的映射。我们知道python虚拟机是由C语言编写的,所以python程序会转化为C程序而执行。比如,python中的所有对象都会在C中有对应的PyObject结构体。python的list、dict等数据类型也要在C中有对应的表示。而像生成器、迭代器等语法结构需要相应的支持。
而虚拟机是模拟一个指令集的程序,所以它自身有一套独立于具体硬件、操作系统的指令集。需要通过底层语言实现这套指令集。虚拟机本身也有自己的数据类型系统、语言结构等。比如,java虚拟机上支持的数据类型有基本数据类型和引用类型,也支持tableswitch和lookupswitch等实现switch语法结构的字节码指令。对于这些语言元素映射到底层语言的实现方式可以不同的方式。首先是解释器模式转化为C++,还有就是JIT直接编译成本地机器代码。
像java这样的虚拟机语言会被编译器编译成虚拟机本地的机器代码,然后再虚拟机上执行,这里就需要向javac编译器实现java语言的数据类型、语言结构和java虚拟机上的数据类型、语法结构的映射。
通过谈论,可以看出编译器和解释器以及虚拟机在编程语言中的重要性,它们都是编程语言可以在计算机上运行的基石。一门编程语言的编译器、解释器或者虚拟机可以很大程度上影响这门语言的执行效率。因为它们在进行语言转换时会进行很多的优化以提高执行效率。这也是为什么JVM上有那么多优秀的语言,因为JVM很强大。所以,要深入语言的底层,要学会编译器、解释器和虚拟机的实现,这方面还需要下功夫啊。
-
PLC编程语言和C语言的区别2024-06-14 8068
-
vb语言和c++语言的区别2024-02-01 4956
-
如何选择创建c语言和c++2023-11-27 1835
-
单片机C语言和汇编语言的混合编程2022-01-25 2124
-
汇编程序和c语言对比,单片机编程中C语言和汇编的差异 精选资料分享2021-07-16 1236
-
单片机C语言和C语言为什么有差异?2020-09-01 4564
-
计算机的机器语言和汇编语言与高级语言的详细资料介绍2020-02-06 7148
-
C语言的简单介绍2020-01-02 970
-
机器语言是什么_机器语言指令大全2018-04-16 77925
-
C语言为什么不能直接转换为机器语言呢?2016-04-12 7000
-
汇编语言与机器语言!2016-03-13 5550
-
C语言和汇编语言混合编程方法和C语言中断处理方法2016-01-06 1042
-
c语言汇编语言和机器语言的转化2015-04-14 7956
全部0条评论

快来发表一下你的评论吧 !
