

FAIR和INRIA的合作提出人体姿势估计新模型,适用于人体3D表面构建
电子说
描述
FAIR和INRIA的合作研究提出一个在Mask-RCNN基础上改进的密集人体姿态评估模型DensePose-RCNN,适用于人体3D表面构建等,效果很赞。并且提出一个包含50K标注图像的人体姿态COCO数据集,即将开源。
密集人体姿势估计是指将一个RGB图像中的所有人体像素点映射到人体的3D表面。
我们介绍了DensePose-COCO数据集,这是一个大型ground-truth数据集,在50000张COCO的图像上手工标注了图像-人体表面(image-to-surface)的对应点。
我们提出了DensePose-RCNN架构,这是Mask-RCNN的一个变体,以每秒多帧的速度在每个人体区域内密集地回归特定部位的UV坐标。
DensePose-COCO数据集
我们利用人工标注建立从二维图像到人体表面表示的密集对应。如果用常规方法,需要通过旋转来操纵表明,导致效率低下。相反,我们构建了一个包含两个阶段的标注流程,从而高效地收集到图像-表面的对应关系的标注。
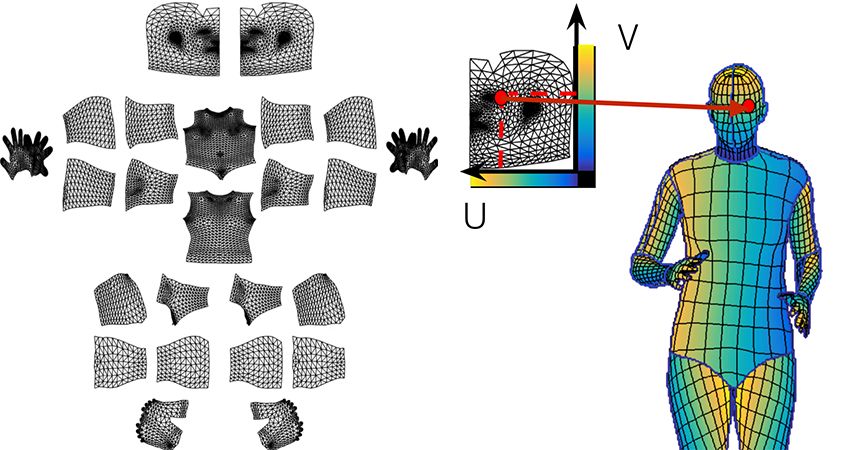
如下所示,在第一阶段,我们要求标注者划定与可见的、语义上定义的身体部位相对应的区域。我们指导标注者估计被衣服遮挡住的身体部分,因此,比如说穿着一条大裙子也不会使随后的对应标注复杂化。
在第二阶段,我们用一组大致等距的点对每个部位的区域进行采样,并要求注释者将这些点与表面相对应。为了简化这个任务,我们通过提供六个相同身体部分的预渲染视图来展开身体部位的表面,并允许用户在其中任何一个视图上放置标志。这允许注释者通过从在六个选项中选择一个,而不用手动旋转表面来选择最方便的视点。
我们在数据收集过程中使用了SMPL模型和SURREAL textures。
两个阶段的标注过程使我们能够非常有效地收集高度准确的对应数据。部位分割(part segmentation)和对应标注( correspondence annotation)这两个任务基本是是同时进行的,考虑到后一任务更具挑战性,这很令人惊讶。我们收集了50000人的注释,收集了超过500万个人工标注的对应信息。以下是在我们的验证集中图像注释的可视化:图像(左),U(中)和V(右)是收集的注释点的值。
DensePose-RCNN系统
与DenseReg类似,我们通过划分表面来查找密集对应。对于每个像素,需要确定:
它倾向于属于哪个表面部位;
它对应的部位的2D参数化的位置。
下图右边说明了对表面的划分和“与一个部位上的点的对应”。
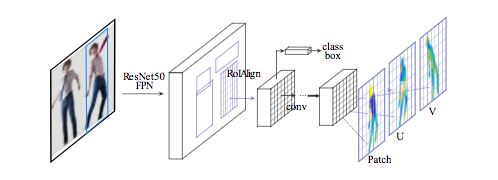
我们采用具有特征金字塔网络( FPN)的Mask-RCNN结构,以及ROI-Align池化以获得每个选定区域内的密集部位标签和坐标。
如下图所示,我们在ROI-pooling的基础上引入一个全卷积网络,目的是以下两个任务:
生成每像素的分类结果以选择表面部位
对每个部位回归局部坐标
在推理过程,我们的系统使用GTX1080 GPU在320x240的图像上以25fps的速度运行,在800x1100的图像上以4-5fps的速度运行。
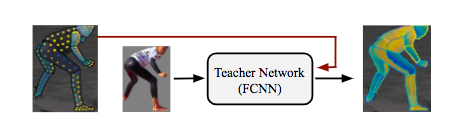
DensePose-RCNN系统可以直接使用注释点作为监督。但是,我们通过在原本未标注的位置上“修补”监督信号的值进行取得了更好的结果。为了达到这个目的,我们采用一种基于学习的方法,首先训练一个“教师”网络:一个完全卷积神经网络(如下图),它重新构造了给定图像的ground-truth值和 segmentation mask。
我们使用级联策略(cascading strategies)进一步提高了系统的性能。通过级联,我们利用来自相关任务的信息,例如已经被Mask-RCNN架构成功解决的关键点估计和实例分割。这使我们能够利用任务协同和不同监督来源的互补优势。
-
【爱芯派 Pro 开发板试用体验】人体姿态估计模型部署前期准备2024-01-01 1818
-
使用人体姿势估算-3d-0001模型执行human_pose_estimation_demo.exe时遇到错误怎么解决?2025-03-05 316
-
请问有适用于测人体温度的红外温度传感器吗2019-03-07 6642
-
基于局部姿态先验的深度图像3D人体运动捕获方法2018-01-03 1050
-
基于遗传优化的自适应凸松弛人体姿势估计2018-01-16 640
-
特伦托大学与Inria合作:使用GAN生成人体的新姿势图像2018-01-29 10538
-
3D感应技术TOF占用检测人体跟踪和人数统计2018-08-10 8763
-
基于DensePose的姿势转换系统,仅根据一张输入图像和目标姿势2018-09-24 11695
-
3D打印技术未来有望打印出人体器官 以促进医学研究的发展2018-12-21 2118
-
先临三维携手TechMed 3D推出人体3D扫描一体化解决方案2021-06-11 1411
-
Yoga AI从单个图像进行3D姿势估计2022-10-26 1155
-
CVPR2023:IDEA与清华提出首个一阶段3D全身人体网格重建算法2023-04-07 2000
-
AI深度相机-人体姿态估计应用2023-07-31 2238
-
3D人体生成模型HumanGaussian实现原理2023-12-20 3510
-
多尺度浸入式3D打印策略,用于人体组织和器官的精准制造2024-04-20 1745
全部0条评论

快来发表一下你的评论吧 !
