

【每天学点AI】KNN算法:简单有效的机器学习分类器
描述
想象一下,你正在计划一个周末的户外活动,你可能会问自己几个问题来决定去哪里:
"今天天气怎么样?"如果天气晴朗,你可能会选择去公园野餐;如果天气阴沉,你可能会选择去博物馆。
这个决策过程,其实就是一个简单的分类问题,而KNN(K-Nearest Neighbors)算法正是模仿这种人类决策过程的机器学习算法。
| 什么是KNN?
KNN(K-Nearest Neighbors)算法是一种基本的分类与回归方法,属于监督学习范畴。它的核心思想是“物以类聚”,即相似的数据应有相似的输出。对于任意n维输入向量,分别对应于特征空间中的一个点,输出为该特征向量所对应的类别标签或预测值。
| KNN的工作原理
KNN算法通过测量不同特征值之间的距离来进行分类。对于一个新的输入样本,KNN算法会在训练数据集中寻找与该样本最近的K个样本(即K个邻居),然后根据这些邻居的类别来预测新样本的类别。在分类问题中,常见的做法是通过“投票法”决定新样本的类别,即选择K个邻居中出现次数最多的类别作为新样本的预测类别。
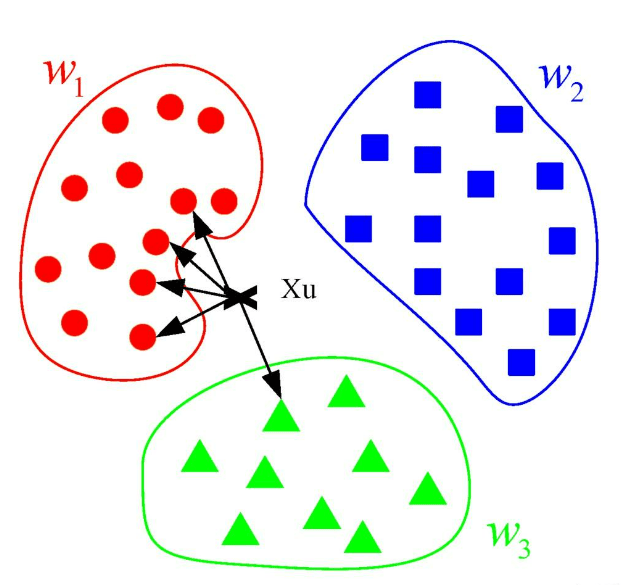
举个例子:想象一下,你是一个新来的大学生,想要加入一个社团。但是,你对这个大学里的社团不太了解,所以你想找一个和你兴趣最接近的社团加入。你决定问问你周围的同学,看看他们都加入了哪些社团。
①你首先会找到几个你认识的同学(比如5个),这些同学就像是你的“邻居”,因为他们离你最近,你最容易从他们那里得到信息。
②然后,你问问这些同学他们都加入了哪些社团,可能是篮球社、舞蹈社、棋艺社等等。
③统计一下这些同学中,哪个社团被提到的次数最多。比如,有3个同学提到了篮球社,2个提到了舞蹈社。
④根据这个“投票”结果,你决定加入篮球社,因为这是被提到次数最多的社团,你觉得这个社团可能最符合你的兴趣。
在这个例子中,你就是那个“新的输入样本”,你的同学就是“训练数据集”,你选择社团的过程就是KNN算法的“分类”过程。你通过了解你周围同学的选择(即寻找最近的K个邻居),然后根据他们的选择来决定你自己的选择(即根据邻居的类别来预测你的类别)。这个过程就是KNN算法的核心思想:通过观察和你相似的人的选择,来预测你可能会做出的选择。
| 如何构建KNN模型?
构建KNN模型也不是简单地像上述例子分几个步骤,需要有完整科学的流程。
- 选择距离度量:KNN算法需要一个距离度量来计算样本之间的相似度,常见的距离度量包括欧氏距离、曼哈顿距离等。
- 确定K值:K值的选择对算法的性能有重要影响,通常通过交叉验证来选择最佳的K值。
- 寻找最近邻:对于每一个新的数据点,算法会在训练集中找到与其距离最近的K个点。
- 分类决策:根据K个最近邻的类别,通过多数表决等方式来决定新数据点的类别。
| KNN的应用
KNN(K-Nearest Neighbors)算法在日常生活中的应用非常广泛,比如:
推荐系统
当你在电商平台上购物时,系统会根据你过去的购买记录和浏览习惯,推荐与你之前购买或浏览过的商品相似的其他商品。这里,KNN算法通过分析用户行为数据,找到与当前用户行为最相似的其他用户,然后推荐那些相似用户喜欢的商品。
餐厅评分
当你使用美食应用寻找餐厅时,应用可能会根据你的位置和偏好,推荐附近的高分餐厅。KNN算法在这里通过分析其他用户的评价和评分,找到与你的搜索条件最匹配的餐厅,并预测它们的受欢迎程度。
房价预测
如果你想出售或购买房屋,KNN算法可以帮助你估计房屋的价值。通过输入房屋的特征(如面积、位置、建造年份等),KNN算法会找到附近相似房屋的销售价格,然后根据这些最近邻居的价格来预测目标房屋的价格。
| KNN与其他算法的比较
KNN算法与其他常见的机器学习算法相比,有独特的优势和局限性。
与决策树(Decision Trees)比较
优势:
- KNN不需要训练过程,可以立即对新数据做出预测。
- KNN可以处理非线性数据,而决策树在处理非线性数据时可能需要更复杂的模型。
劣势:
- 决策树模型更易于解释和可视化,而KNN的预测过程可能不够直观。
- 决策树通常对噪声数据和异常值更鲁棒,而KNN对这些数据更敏感。
与支持向量机(SVM)比较
优势:
- KNN算法实现简单,易于理解和使用。
- KNN可以很好地处理多分类问题,而SVM在多分类问题上需要额外的技术如一对一或一对多。
劣势:
- SVM在高维空间中表现更好,尤其是在特征空间很大时。
- SVM可以提供更好的泛化能力,而KNN可能会过拟合,尤其是在样本数量较少时。
与随机森林(Random Forest)比较
优势:
- KNN不需要训练时间,而随机森林需要构建多个决策树并进行聚合。
- KNN可以处理非线性和高维数据。
劣势:
- 随机森林在处理大型数据集时通常更快,而KNN在大数据集上可能会非常慢。
- 随机森林提供了更好的泛化能力,并且对噪声和异常值更鲁棒。
与神经网络(Neural Networks)比较
优势:
- KNN算法简单,不需要复杂的模型训练过程。
- KNN可以很容易地解释和理解模型的预测过程。
劣势:
- 神经网络可以捕捉更复杂的模式和非线性关系,尤其是在深度学习模型中。
- 神经网络通常在大规模数据集上表现更好,尤其是在图像和语音识别等领域。
与梯度提升机(Gradient Boosting Machines, GBM)比较
优势:
- KNN不需要训练,可以快速对新数据进行预测。
- KNN可以处理分类和回归问题,而GBM主要用于回归问题。
劣势:
- GBM通常在预测准确性上优于KNN,尤其是在结构化数据上。
- GBM可以处理更复杂的数据模式,并且对噪声和异常值更鲁棒。
KNN算法在需要快速原型开发和对模型解释性要求较高的场合很适用,在需要处理大规模数据集、高维数据或需要更强泛化能力的场景下,可能需要考虑其他更复杂的算法。
所以在实际应用中,应该根据具体问题的数据特征、解释性需求以及计算资源等方面的考量,选择更合适的算法,提升模型的效果和应用的可行性。
KNN属于机器学习算法,在AI全体系课程中,它不仅是机器学习入门者最先接触的算法之一,也是理解其他更复杂机器学习算法的基础,对于深入学习机器学习和理解其他更高级的算法有着重要的意义。
AI体系化学习路线
-
机器学习算法汇总 机器学习算法分类 机器学习算法模型2023-08-17 2362
-
KNN算法、分类回归树、随机森林的优缺点及应用实例2022-11-11 7933
-
使用KNN进行分类和回归2022-10-28 3744
-
可检测网络入侵的IL-SVM-KNN分类器2021-04-29 1136
-
如何使用Arduino KNN库进行简单的机器学习?2021-04-01 4571
-
KNN分类算法及python代码实现2020-06-05 1960
-
机器学习KNN介绍2020-04-07 2925
-
各类机器学习分类算法的优点与缺点分析2020-03-02 4407
-
详解机器学习分类算法KNN2019-10-31 7346
-
Java的KNN算法2019-09-10 1811
-
人工智能机器学习之K近邻算法(KNN)2018-05-29 3544
-
学习KNN算法的基本原理,并用Python实现该算法以及阐述其应用价值2018-01-02 6688
-
图像分类的方法之深度学习与传统机器学习2017-09-28 1822
-
【Firefly RK3399试用体验】之结项——KNN、SVM分类器在SKlearn机器学习工具集中运用2017-07-20 4501
全部0条评论

快来发表一下你的评论吧 !
