

一文详解计算型存储协议框架
描述
引言
近年来,AI应用态势迅猛增加,对计算侧的算力和内存提出了更高的要求。GPU、HBM这些高性能高密计算部件和内存部件,在AI计算场景中作为必需品,成为市场热点。业界也在讨论能否把计算侧的业务卸载到存储侧,称为计算型存储(Computational Storage),通过存储侧卸载数据预处理,如数据校验、解压、数据提取,甚至卸载局部机器学习训练,从而减轻计算侧的算力负载和内存负载。这两年,SNIA和NVMe陆续定义了计算型存储框架和协议接口,而IBM、Intel、Dell、Solidigm、Kioxia等知名厂商也在通过存储应用和SSD盘联合定制,开拓计算型存储应用道路。
01 计算型存储协议框架
SNIA在2022年8月发布的Computational Storage Architecture and Programming Model,描述了计算型存储的架构和模型定义。计算型存储设备定义为三种模型:计算型存储处理器(Computational Storage Processor,CSP)、计算型存储盘(Computational Storage Drive,CSD)和计算型存储阵列(Computational Storage Array,CSA)。
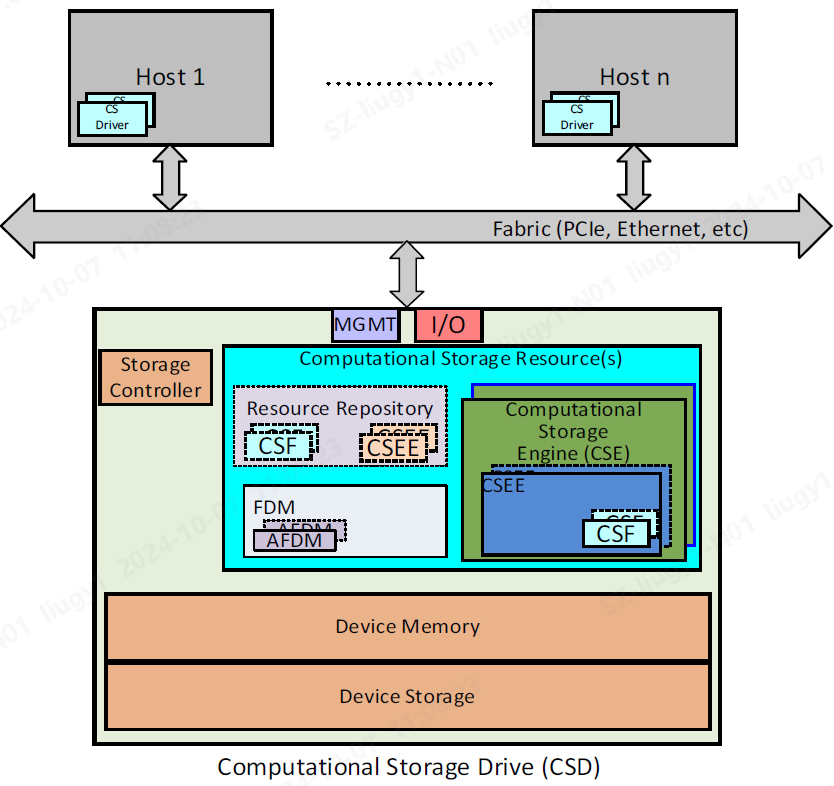
◎图1 CSD架构
以计算型存储盘(CSD)为例,其架构框架如图1所示。Storage Controller可以对应于SSD的管理控制器,控制Device Memory(如SSD内的DDR)和Device Storage(如SSD内的NAND Flash)。计算型存储主要是定义计算型存储资源(Computational Storage Resource, CSR),用于设备提供用户可支配使用的计算资源和内存资源。
其中,计算型存储引擎(Computational Storage Engine, CSE),是用于提供计算资源。CSE里面包括计算型存储引擎环境(Computational Storage Engine Environment, CSEE)用于提供执行计算环境或者平台,譬如操作系统、Container容器,或者FPGA这种硬件环境。计算环境里通过计算型存储功能(Computational Storage Function, CSF),提供具体的计算功能,如压缩、加密、数据filter、Erasure Code、RAID、hash/CRC、重删、正则表达式计算等功能。
另一方面,功能数据内存(Function Data Memory,FDM)是设备提供给CSE进行计算使用的内存区域。用户通过分配功能数据内存(Allocated Function Data Memory,AFDM)绑定给具体CSF,用于具体计算存储输入数据、中间过程数据和输出结果。
NVM Express在2024年发布的Computational Programs Command Set Specification和Subsystem Local Memory Command Set Specification两个协议标准,具象化了计算型存储框架在NVMe接口上的实现。NVM Express在原有用于数据持久化存储的NVM Namespace外,额外定义了Compute Namespace和Subsystem Local Memory (SLM) Namespace,分别对应SNIA定义的CSE和FDM,为用户提供计算资源和内存资源。
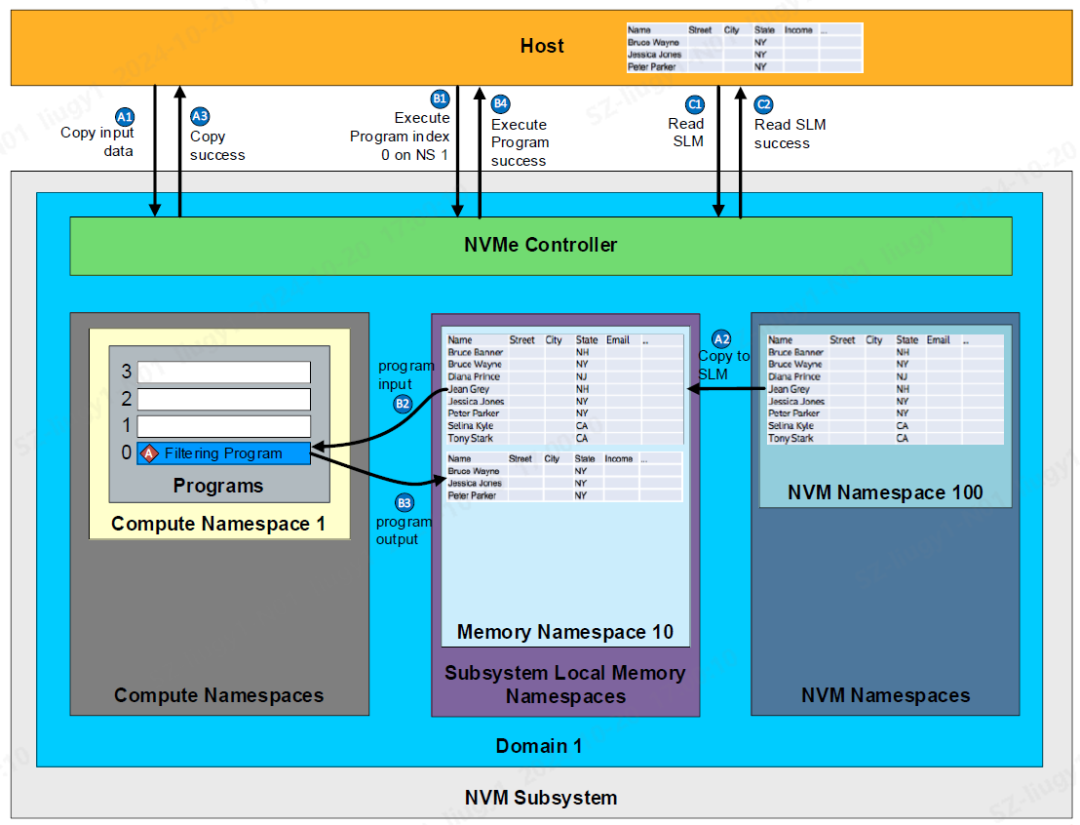
◎图2 NVM Express计算型存储框架
NVM Express的计算型存储接口架构和运作,如上图所示。一个Compute Namespace可以支持多个程序(Program)。Program可以支持主机加载(Downloadable Program),或者是盘内预设(Device-defined Program)。用户在使用前,需要通过Program Activation Management命令激活这些Program。
Subsystem Local Memory (SLM) 可以提供给Program用作数据输入输出的内存区域。用户可以通过Memory Range Set Management命令,为Compute Namespace建立SLM Namespace中的多个内存区域(Memory Range)。
用户在激活需要的Program和建立Program所需的内存区域后,可以通过以下步骤执行Program:
1主机下发Memory Copy命令,盘片从NVM Namespace,即SSD存储LBA数据区域,读出数据后,拷贝数据到SLM的内存区域。此外,主机也可以下发Memory Write命令,盘片从主机内存拷贝数据到SLM的内存区域。以准备好Program执行所需要的输入数据。图2中A1-A3示例是将SSD存储的数据库数据,拷贝到SLM的内存区域。
2主机通过下发Excute Program命令,执行Compute Namespace的Program,采用内存区域中的数据作为输入,Program进行计算后,输出到内存区域中。图2中B1-B4示例过程是,主机调用盘内的filter program,对数据库数据进行筛选计算,将筛选结果输出到SLM的内存区域后,上报主机。
3主机通过下发Memory Read命令,盘片将SLM内存区域中的数据,读出到主机内存,如图2中C1-C2所示。
02 计算型存储应用思路
SNIA和NVMe定义了一整套盘片和主机进行计算交互的框架和接口,SNIA还定义了一整套的API(见Computational Storage API, SNIA)。这样可以有效推动应用规范化,将计算型存储接口落入到设备驱动、操作系统内核等,支撑起主机应用层访问接口标准化。
从SSD设备的角度来看,SSD作为存储部件,在存储系统内分配的空间、功耗和成本都是受约束的。SSD的设计规划上,SSD并不是一个强算力系统。对于一个15W的SSD来说,可能分配到内部CPU计算的功耗不到2W。从SSD CPU和总线选取和设计来说,CPU的作用主要是进行SSD内部控制,而不是进行数据计算。这样,在SSD内要实现灵活的、用户可加载的计算引擎,如通过OS或者Container平台进行软件计算,通过SSD内部CPU计算达到高性能是很困难的。
从目前业界趋势来说,一方面是在SSD控制器外,增加FPGA作为计算引擎,或者是FPGA同时用于SSD控制和计算(如IBM FlashCore Module方案),由于FPGA在芯片封装大小、成本和功耗上不如ASIC,这样会造成整盘性能、硬件布局、功耗、散热、成本等一系列的问题。另一方面是通过在控制器ASIC提供定制的硬化引擎,这就对盘片厂商有很高的能力要求,除了有盘片设计生产能力,还要有SSD控制器芯片定义和设计能力,并且能够拉通上层应用厂商,识别盘片卸载业务趋势进行长远规划。
这里以2023年Solidigm在Flash Memory Summit发表的Data scrubbing卸载定制作为示例。存储服务器会经常巡检全部的数据,即把数据全部读出,进行hash计算(如CRC32、MD5等),再和存储保存在元数据的结果进行比对。这个场景下对于服务器的算力、内存、NVMe/TCP接口都有很大压力,会成为业务瓶颈。

◎图3 Data scrubbing
Solidigm提出的方案是在盘内进行hash计算。主机侧组织需计算的LBA list下发到盘,盘片从LBA区域读出数据,存放到盘内内存区域,调用盘内硬化引擎进行CRC32等计算,只将计算结果返回到主机。
这样,卸载了主机侧进行hash计算的算力,由于盘片只上报结果,节省大量接口数据读取带宽,以及主机内存,而且可以随着盘数量增加扩展计算能力。
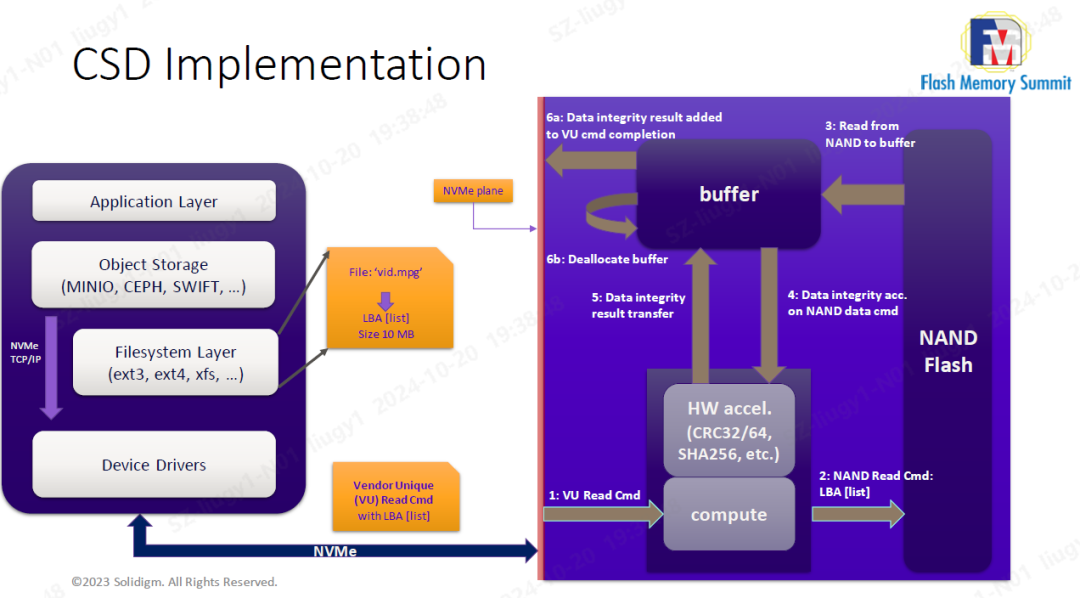
◎图4 CSD实现
03 忆联端到端能力构建
计算型存储SSD随着协议标准的成熟化,可与客户联合定制实现业务卸载。其价值是减轻客户侧的系统算力、内存压力,减少网络和设计接口带宽,从而在AI高速发展的趋势下,突破系统瓶颈,发挥系统能力。
作为一家领先的SSD厂商,忆联正积极整合内外部资源,深入探索计算型存储的前沿领域。通过引入先进的计算技术,优化控制器设计,并结合智能存储管理,致力于开发具有高性能、高可靠性和智能化特性的存储解决方案。
忆联不仅关注对数据传输效率和存储容量的提升,更关注探索各垂直应用领域的融合技术创新。忆联拥有成熟的芯片、软件、硬件、以及生产团队,能够支撑SSD从控制器芯片、软件业务、硬件设计、装备生产的端到端规划和设计开发,可支撑各垂直行业客户实现SSD联合定制,满足多样化市场需求,突破客户业务瓶颈,创造各行各业的客户价值。
-
一文详解pcb的组成和作用2023-12-18 3959
-
一文详解pcb微带线设计2023-12-14 6938
-
一文详解pcb的msl等级2023-12-13 17102
-
一文详解pcb不良分析2023-11-29 2431
-
一文详解pcb地孔的作用2023-10-30 3266
-
一文详解pcb和smt的区别2023-10-08 6079
-
一文详解分立元件门电路2023-03-27 5175
-
一文看懂FPGA芯片投资框架.zip2023-01-13 647
-
一文详解精密封装技术2022-12-30 2748
-
一文读懂什么是NEC协议2021-10-15 2723
-
一文详解区块链的存储体系2020-11-26 9650
-
一文解析Spring框架2020-06-17 1789
-
一文解析SpringBoot2整合SSM框架2020-06-09 2037
-
基于EVMS和SNMP的存储管理框架2009-04-22 964
全部0条评论

快来发表一下你的评论吧 !
