

谈谈GPU的使用寿命
描述
上文结合论文谈一谈,三年寿命的GPU [上]说到,电路腐蚀导致橡树岭实验室的GPU寿命只有3年,更换了11,000块GPU。
早在2015年橡树岭实验室就发表了针对GPU Error的另一篇文章:
[194] Understanding GPU Errors Large-scale HPC System and the Implications for System Design and Operation.
194 表示引用数。
这篇文章总结了Titan GPU运行中出现的失败和教训。
虽然这篇文章发表于2015年,但是文章中图片的模糊程度像是1955年。
1 背景介绍
GPU的主要的存储部件,都使用了SECDEC ECC校验保护,包括:
device memory
l2/l1 cache, instruction cache,data cache, share memory
register file
但是并不是GPU中所有的部件都能被ECC校验保护比如
logic
queue
thread block threaduler
warp scheduler
instruction dispatch unit
interconnect network
一旦一个部件发生错误,那么就可能影响多个线程。
文章总结了GPU经常出现的error以及其影响。
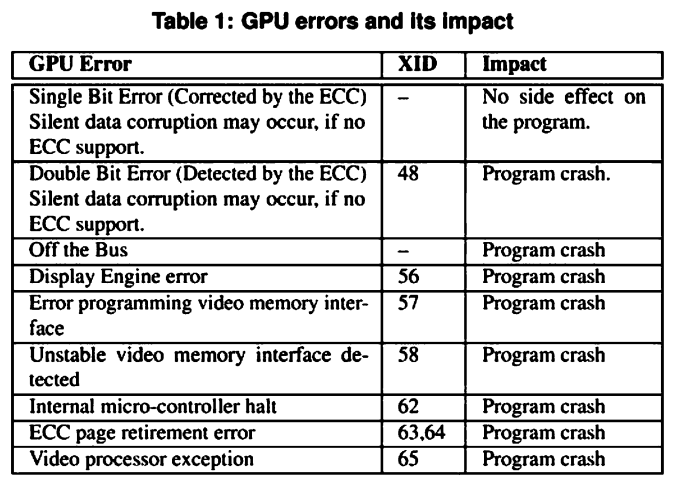
上图中最上面两行的Single Bit Error和Double Bit Error后面会缩写为SBE和DBE。
Stability
首先他们发现GPU发生问题的频率较低,考虑到共计有18,688块GPU。
按照GPU的手册,这个数量的GPU,至少每天会发生两次failure,但是实际中,每两天发生一次。
他们也注意到,上图中的Off the bus, ECC page retirement error和DBE failure是主要导致GPU失败的问题。
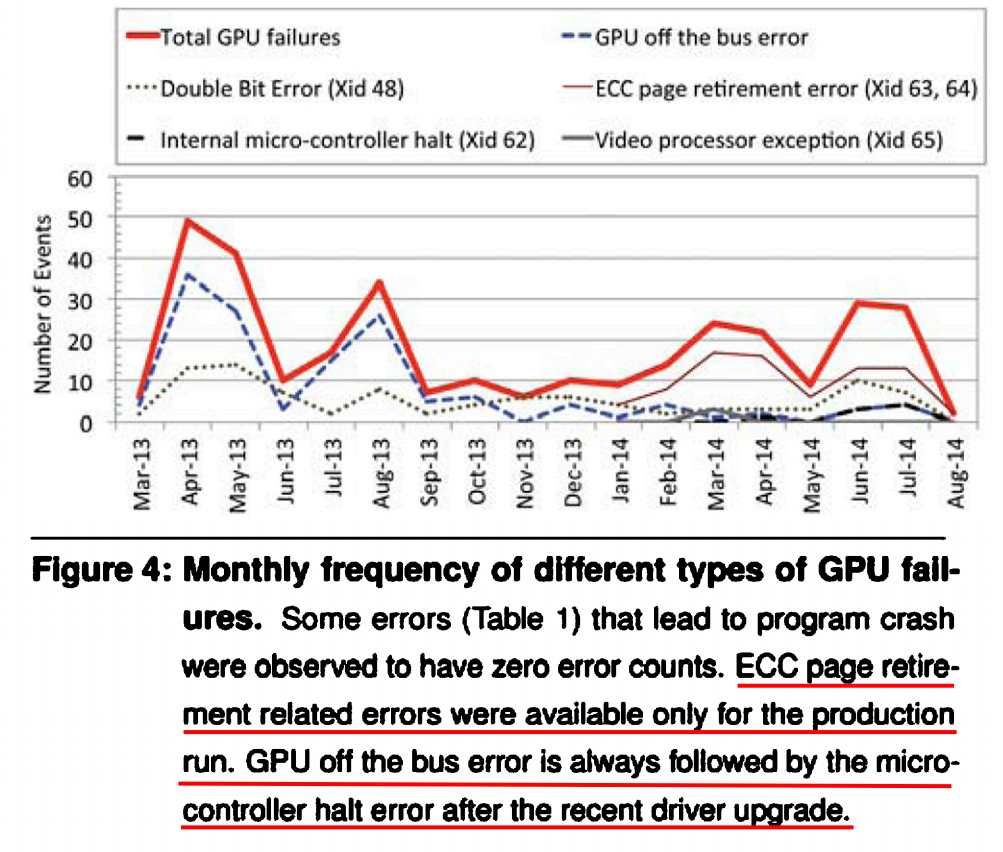
他们也注意到,一小部分的bad GPU重复的发生问题,是拉低MTBF(meantime between failure)的主要原因。
如果可以早发现,那么应当提升GPU稳定运行的时间。
Temporal Locality
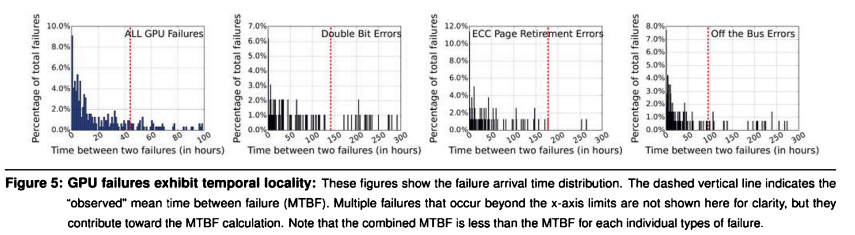
研究人员发现,有显著的一部分GPU failure发生远早于MTFB。 这意味着GPU failure有很强的temporal locality。 如下图所示,并不是均匀分布。
Stressing Testing
研究人员发现,有6块GPU card造成了总体DBE error中的25%。 有一部分GPU可能会多次发生DBE和ECC page retirement问题,应当在早期发现这些GPU卡。 通过在进入生产环节之前,进行压力测试,可以有效避免类似问题。
Temperature
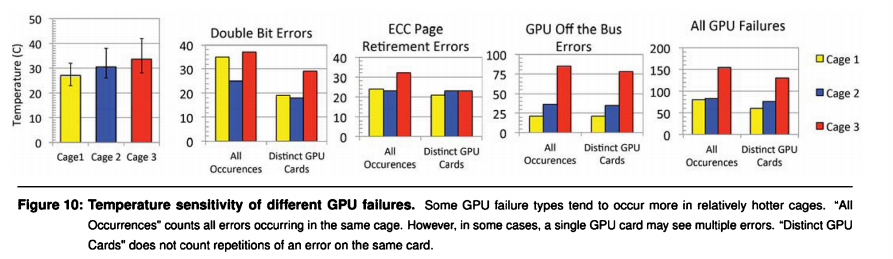
他们发现off the bus和DBE error是与温度有关,但并不是所有的问题都与温度有关。
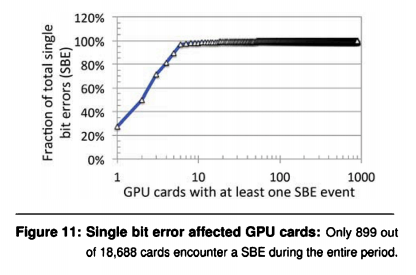
SBE
SBE (Single bit error), 他们发现98%的SBE问题只发生在10张卡上。
如下图x轴所示,10张卡占据了整体98%的SBE Error
L2 Cache
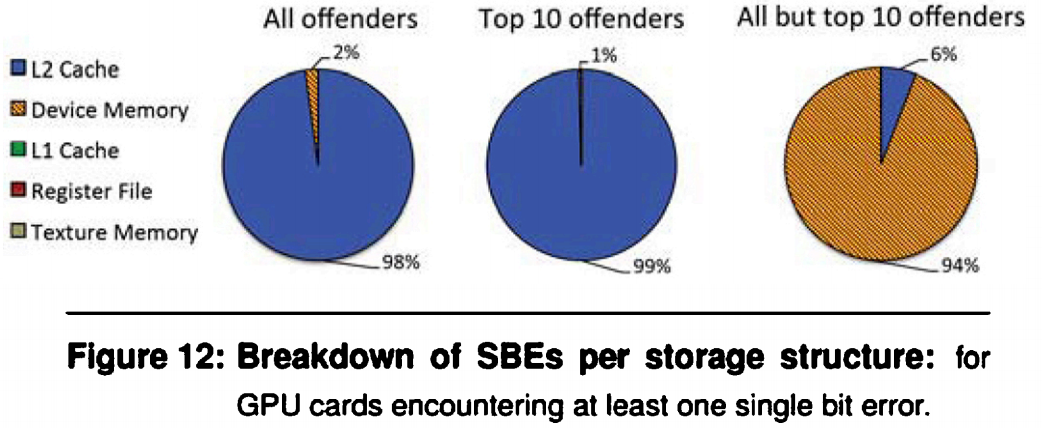
899张有问题的卡中,如上文所述,10张卡贡献了SBE 98%的问题。
这10张卡发生SBE错误时,99%都发生在了L2 Cache上,如下图中间的图。蓝色代表L2 Cache发生问题。
而对于其余发生问题,造成了2% SBE问题的卡,96%的问题都发生在了device memory上。
-
固态电池使用寿命2024-09-15 13955
-
交叉导轨的使用寿命2023-07-20 1785
-
电容器的使用寿命2023-06-18 12571
-
会缩短R型变压器使用寿命的注意事项2022-12-26 1491
-
如何延长锂离子电池的使用寿命2022-03-10 4745
-
如何延长电池的使用寿命2022-01-23 7406
-
如何保证工业的使用寿命更长久2021-11-04 1105
-
浅谈高压真空断路器的使用寿命2021-03-22 6707
-
电阻负载使用寿命和危害2020-07-03 5483
-
温度探头的使用寿命2019-02-21 14476
-
怎么延长电表使用寿命?2018-07-24 3503
-
电力电容器的保养及使用寿命2018-03-22 4807
-
电子产品使用寿命 元器件使用寿命 计算2015-06-06 11189
-
等离子的使用寿命是多久?2009-05-24 4497
全部0条评论

快来发表一下你的评论吧 !
