

研究人员提出一种基于哈希的二值网络训练方法 比当前方法的精度提高了3%
电子说
描述
程健研究员团队最近提出了一种基于哈希的二值网络训练方法,揭示了保持内积哈希和二值权重网络之间的紧密关系,表明了网络参数二值化本质上可以转化为哈希问题,在ResNet-18上,该方法比当前最好方法的精度提高了3%。
近年来,深度卷积神经网络已经深入了计算机视觉的各个任务中,并在图像识别、目标跟踪、语义分割等领域中取得了重大突破。在一些场景下,当前深度卷积网络性能已经足以部署到实际应用中,这也鼓舞着人们将深度学习落地到更多的应用中。
然而,深度卷积网络在实际部署时面临着参数量和时间复杂度等两方面的问题,一方面是深度网络巨大的参数量会占用大量的硬盘存储和运行内存,这些硬件资源在一些移动和嵌入式设备中往往是很有限的;另外一方面就是深度网络的计算复杂度较高,这会使得网络推理速度很慢,同时会增加移动设备的电量消耗。
为了解决此类问题,人们提出了很多网络加速和压缩方法,其中网络参数二值化是一种将网络参数表示为二值参数的方法。由于二值网络中参数只有+1和-1两种值,乘法运算就可以被加法运算替代。由于乘法运算比加法运算需要更多的硬件资源和计算周期,使用加法运算替代乘法运算能够实现网络加速的目的。
另一方面,原始网络参数的存储格式是32位浮点数,二值参数网络只使用1位来表示+1或者-1,达到了32倍的压缩目的。但是将参数从32位量化到1位会导致较大的量化损失,当前的二值网络训练方法往往会导致较大的网络精度下降,如何学习二值的网络参数同时又不带来较大的精度下降是一个问题。
图自网络
自动化所程健研究员团队的胡庆浩等人最近提出了一种基于哈希的二值网络训练方法,揭示了保持内积哈希(Innerproduct Preserving Hashing)和二值权重网络之间的紧密关系,表明了网络参数二值化本质上可以转化为哈希问题。
给定训练好的全精度浮点32位网络参数 ,二值权重网络(BWN)的目的是学习二值网络参数
,二值权重网络(BWN)的目的是学习二值网络参数 并维持原始网络精度。学习二值参数
并维持原始网络精度。学习二值参数 的最朴素的方式就是最小化
的最朴素的方式就是最小化 与二值参数
与二值参数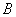 之间的量化误差,但是这种量化误差和网络精度之间存在着一定的差距,最小化量化误差并不会直接提高网络精度,因为每一层的量化误差会逐层积累,而且量化误差会受到输入数据的增幅。
之间的量化误差,但是这种量化误差和网络精度之间存在着一定的差距,最小化量化误差并不会直接提高网络精度,因为每一层的量化误差会逐层积累,而且量化误差会受到输入数据的增幅。
一种更好的学习二值参数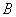 的方式是最小化内积相似性之差。假设网络某一层输入为
的方式是最小化内积相似性之差。假设网络某一层输入为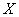 ,
,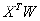 是原始的内积相似性,则
是原始的内积相似性,则 是量化之后的内积相似性,最小化
是量化之后的内积相似性,最小化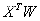 与
与 之间的误差可以学习到更好的二值参数
之间的误差可以学习到更好的二值参数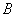 。从哈希的角度来讲,
。从哈希的角度来讲,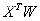 代表着数据在原始空间中的相似性或者近邻关系,
代表着数据在原始空间中的相似性或者近邻关系, 则代表着数据投影到汉明空间之后的内积相似性。而哈希的作用就是将数据投影到汉明空间,且在汉明空间中保持数据在原始空间中的近邻关系。至此,学习二值参数
则代表着数据投影到汉明空间之后的内积相似性。而哈希的作用就是将数据投影到汉明空间,且在汉明空间中保持数据在原始空间中的近邻关系。至此,学习二值参数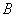 的问题就转化成了一个在内积相似性下的哈希问题,该哈希主要是将数据投影到汉明空间并保持其在原始空间中的内积相似性。
的问题就转化成了一个在内积相似性下的哈希问题,该哈希主要是将数据投影到汉明空间并保持其在原始空间中的内积相似性。
团队首先在VGG9小网络上对方法进行验证,并且在AlexNet和ResNet-18上超过当前的二值权重网络。特别的,在ResNet-18上,该方法比当前最好方法的精度提高了3个百分点。获得了较好的实验结果。
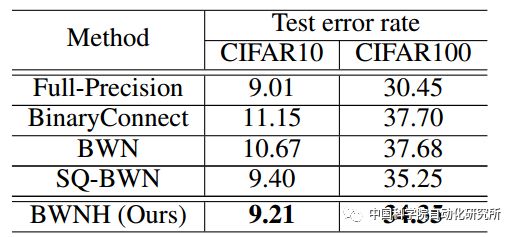
表1:不同方法在VGG9上的分类错误率
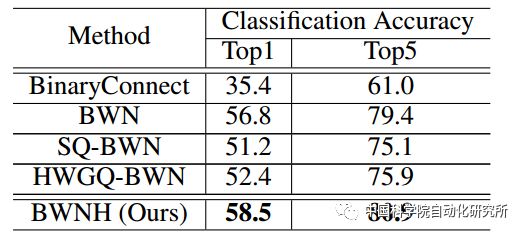
表2:不同方法在AlexNet的分类精度
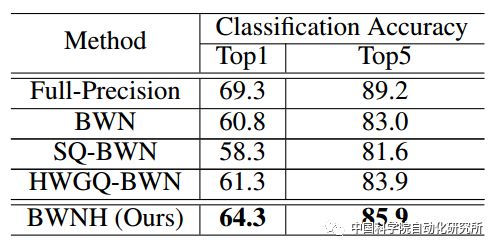
表3:不同方法在ResNet-18的分类精度
Dasgupta等人[2]在2017年11月份的《Science》上撰文揭示了果蝇嗅觉神经回路其实是一种特殊的哈希,其哈希投影是稀疏的二值连接。对比二值权重网络(BWN),我们可以发现二者之间有着密切的关系,首先,二者的网络都是二值连接,这意味着二值权重在生物神经回路中有存在的生物基础,这也为二值权重网络的潜在机理提供了启发;其次,二者都是为了保持近邻关系,并且可以描述为哈希问题,这种现象表明神经网络的某些连接是为了保持近邻关系。最后,果蝇嗅觉回路中的稀疏连接和卷积层的参数共享机制有着异曲同工之处,都是对输入的部分区域进行连接。
相关工作已经被AAAI2018接收[1],并将在大会上作口头报告。
参考资料:
[1] Qinghao Hu, Peisong Wang, Jian Cheng. From Hashing to CNNs: Training Binary Weight Networks via Hashing. AAAI 2018
[2]Dasgupta S, Stevens C F, Navlakha S. A neural algorithm for a fundamental computing problem. Science, 2017, 358(6364): 793-796.
-
ai大模型训练方法有哪些?2024-07-16 5435
-
探索一种降低ViT模型训练成本的方法2022-11-24 1552
-
优化神经网络训练方法有哪些?2022-09-06 1751
-
时识科技提出新脉冲神经网络训练方法 助推类脑智能产业落地2022-06-20 2333
-
隐藏技术: 一种基于前沿神经网络理论的新型人工智能处理器2022-03-17 16032
-
求大佬分享一种基于毫米波雷达和机器视觉的前方车辆检测方法2021-06-10 2249
-
一种基于异构哈希网络的跨模态人脸检索方法2021-04-28 961
-
基于异构哈希网络的跨模态人脸检索方法探究分析2021-03-31 917
-
研究人员发现一种可在水中产生纳米气泡的新方法2020-04-09 8002
-
普渡大学的研究人员正在开发一种综合医疗传感平台2019-10-25 1283
-
新型谐波分析方法提高了精度减少了智能仪表的计算开销2019-07-15 1283
-
微软在ICML 2019上提出了一个全新的通用预训练方法MASS2019-05-11 4221
-
dc模块电源的控制方法2018-07-28 3087
-
基于粒子群优化的条件概率神经网络的训练方法2018-01-08 1449
全部0条评论

快来发表一下你的评论吧 !
