

使用PVA引擎优化自动驾驶汽车CV开发流水线
描述
在汽车软件开发领域,越来越多的大规模 AI 模型被集成到自动驾驶汽车中,这些模型的范围从视觉 AI 模型到用于自动驾驶的端到端 AI 模型。现在,汽车软件开发领域对算力的需求正在飞速增长。导致系统负载增加,对系统稳定性和时延产生了负面影响。
为了解决这些难题,可以使用可编程视觉加速器(PVA)提高能效和整体系统性能。PVA 是 NVIDIA DRIVE SoC 上的一个低功耗、高效率的硬件引擎。通过使用 PVA,可以卸载通常由 GPU 或其他硬件引擎处理的任务到 PVA 上,从而降低它们的负载,使它们能够更加高效地管理其他关键任务。
在本文中,我们简要介绍了 DRIVE 平台上的 PVA 硬件引擎和 SDK。我们展示了 PVA 引擎在计算机视觉(CV)流水线中的典型用例,包括预处理、后处理和其他 CV 算法,重点介绍其效果和效率。最后,我们以蔚来为例,详细介绍了蔚来如何在其数据流水线中使用 NVIDIA PVA 引擎和优化算法来卸载 GPU 或视频图像合成器(VIC)任务,并提高自动驾驶汽车系统的整体性能。
PVA 硬件概述
PVA 引擎是一款先进的超长指令词(VLIW)、单指令、多数据(SIMD)数字信号处理器,它针对图像处理和计算机视觉算法加速任务进行了优化。PVA 具有出色的性能和极低的功耗。作为异构计算流水线的一部分,PVA 可与 NVIDIA DRIVE 平台上的 CPU、GPU 和其他加速器异步或并行使用。
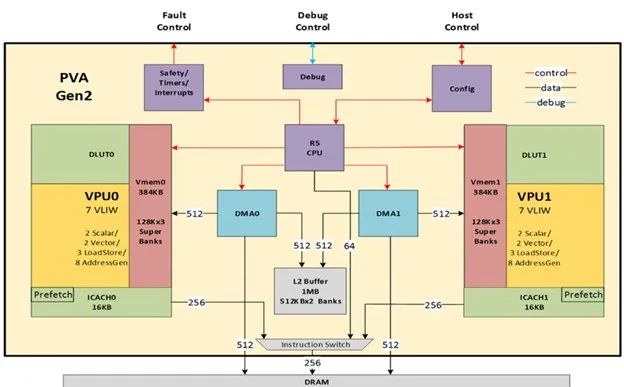
图 1. PVA 硬件架构
NVIDIA DRIVE Orin 上的 CV 集群中有一个 PVA 实例,NVIDIA DRIVE Orin 是一种高性能系统级芯片(SoC)专为先进的 AI 应用而设计,尤其是自动驾驶汽车和机器人领域。
在每个 PVA 中,有两个向量处理子系统(VPS)。每个 VPS 包括以下内容:
1 个矢量处理器(VPU)内核
1 个解耦查找单元(DLUT)
1 个向量内存(VMEM)
1 个指令缓存(I-cache)
VPU 核是主处理单元。它是一个专为计算机视觉优化的向量 SIMD VLIW DSP。它通过指令缓存获取指令,并通过 VMEM 访问数据。
DLUT 是专为提高并行查找操作效率而开发的专用硬件组件。它通过与主处理器解耦的流水线中执行此类查找操作,实现了使用单个查找表副本进行并行查找。通过这种方式,DLUT 可以最大限度地减少内存占用并提高吞吐量,同时避免依赖数据的内存库冲突,最终提高系统整体性能。
VMEM 为 VPU 提供了本地数据存储,实现了各种图像处理和计算机视觉算法的高效执行。它支持 VPS 以外的系统组件的访问(比如 DMA 和 R5),从而实现与 R5 及其他系统级组件的数据交换。
VPU(I-cache)可根据要求向 VPU 提供指令数据、从系统内存中请求缺失的指令数据并维护 VPU 的临时指令存储。
R5 为每个 VPU 任务配置 DMA,选择性地将 VPU 程序预取到 VPU 指令缓存中,并启动相应 VPU-DMA 的组合来处理任务。DRIVE Orin PVA 还包含 1 个 L2 SRAM 内存供两组 VPS 和 DMA 共享。
两个 DMA 设备用于在外部内存、PVA L2 内存、两个 VMEM(每个 VPS 1 个)、R5 紧密耦合内存(TCM)、DMA 描述符内存和 PVA 级配置寄存器之间移动数据。
在低负载系统中,对 DRAM 的两个并行 DMA 访问最高可实现 15 GB/s 的读/写带宽。在高负载系统中,该带宽最高可达到 10 GB/s。
在算力方面,INT8 GMACS(每秒十亿次乘法累加运算)为 2048,不包括 DLUT。每个 PVA 实例的 FP32 GMACS 为 32。
PVA SDK 介绍
与 GPU 的 CUDA 工具包类似,NVIDIA PVA SDK 专为打造利用 PVA 硬件功能的计算机视觉算法而设计。PVA SDK 为 CV 和 DL/ML 算法的开发、部署和安全认证提供了运行时 API、工具和教程。它提供了一个从构建到部署的无缝框架,支持将代码交叉编译成 Tegra PVA 上的二进制可执行文件。
PVA SDK 通过多种资源支持软件开发:
全面的入门指南。
x86 原生仿真器,可模拟真实的 VPU。支持在 x86-64 平台上开发和调试 VPU 内核。
全套代码生成工具,包括经过优化的 C/C++ 编译器、调试器和集成开发环境。
分析工具,例如用于视觉性能分析的 NVIDIA Nsight 系统和用于详细 VPU 代码性能指标的 API。
分步教程,该教程将逐一介绍 PVA 的概念,从基本示例到 VPU、DMA 的高级优化以及与其他 Tegra 引擎的互通。
丰富的文档和参考手册提供了有关 VPU 内部函数的详细信息,使用户能够编写优化的代码,同时抽象并降低 DMA 编程的复杂性。
PVA SDK 提供了大量现成的算法以支持自动驾驶和机器人领域中的常见计算机视觉用例。用户可以在其生产环境中直接使用这些算法(可访问源代码)或者使用 PVA SDK 的功能自主开发定制算法。
NVIDIA 根据常见的 CV 用例,基于 PVA SDK 预先开发了许多算法。用户可以在其产品中充分利用这些 PVA 算法并访问代码,也可以将各种不同的算法作为参考,自主开发有价值的算法。
典型 PVA 用例
许多自动驾驶汽车开发者都面临着 SoC 计算资源不足的挑战,这导致 CPU、GPU、VIC 和 DLA 负载过高。为了解决这个问题,人们正在考虑使用 PVA 硬件卸载 SoC 上使用率较高的硬件引擎的处理任务。
图像处理:部分图像处理和 CV 任务可以移植到 PVA 上,以卸载 GPU、CPU、VIC 甚至 DLA 的工作负载。
深度学习操作:在深度学习网络中,可将某些层或计算密集型运算符(例如 ROI 对齐)卸载到 PVA。在特定情况下,小型深度学习网络可以完全移植到 PVA 上。
数学计算:作为一个向量 SIMD VLIW DSP,PVA 可以高效地处理数学计算,例如矩阵计算、FFT 等。
以下详细介绍两个用例,以供参考:
将 AI 流水线中的预处理和后处理卸载至 PVA
将纯 CV 或受计算限制的流水线迁移至 PVA
将 AI 流水线中的
预处理和后处理卸载至 PVA

图 2. AI 推理流水线
这是 CV 流水线的典型用例。输入图像来自实时场景中的实时摄像头,或来自离线场景中的解码器。该流水线包括三个阶段:
预处理
AI 推理
后处理
PVA 硬件引擎在 CV 流水线的所有阶段,从预处理到后处理,都能发挥关键作用,确保图像处理和计算机视觉任务得到高效且有效的处理。
预处理
预处理涉及基本的 CV 任务,以便对齐或规范化模型的输入,其中包括重映射(去畸变)、裁剪、调整大小和颜色转换(从 YUV 到 RGB)等操作。
在某些情况下,当图像来自 NVDEC(Tegra SoC 上的解码器硬件引擎)时,图像布局为 block linear 格式。在这种情况下,在预处理阶段需要执行更多的步骤,将 block linear 格式转换为 pitch linear 格式的图像。
PVA 硬件引擎非常适合这些任务。然而,在内存受限的情况下,应考虑合并相邻的 PVA 操作,以充分利用 PVA 的算力。
AI 推理
AI 推理以最先进的 AI 模型为基础,执行业务需求所需的核心 CV 任务。该步骤可在 GPU 或深度学习加速器(DLA)上执行,以获得更好的性能。
PVA 运行时 API 同时支持 NvSciSync 和原生 CUDA 流,能够高效执行涉及 GPU/DLA 的异构流水线,而不会产生恢复到 CPU 进行调度相关的时延。
根据具体用例,该 AI 模型可以是用于物体检测的 YOLO 或 R-CNN,也可以是用于分类的逻辑回归或 K-nearest neighbor(KNN),以及其他模型等。
后处理
后处理会优化检测结果。该步骤可能涉及使用中值滤波器去除异常值,进行混合操作以融合不同的候选项或应用非最大抑制(NMS)来选择最佳目标。PVA 硬件能够有效处理这些任务。
将纯 CV 或受计算限制的流水线迁移至 PVA

图 3. 追踪器流水线
这是一个更具体、更复杂的用例,所有步骤都可以在 PVA 上执行。主要涉及检测和追踪输入图像中的特征点,或在某些场景中计算稀疏光流:
图像金字塔沿比例空间扩展图像。
特定的检测算法可识别图像中的特征点或角点。
跟踪算法逐帧追踪这些特征点。
与之前的用例相比,这个场景在关键方面有所不同:
计算受限处理:数据处理的每一步都受计算限制,并涉及到处理 2D 图像。这些算法可以很好地向量化,并在 PVA 硬件上高效执行。最重要的是,PVA 的算力得到了充分利用。
紧密耦合的步骤:有一个额外的数据循环将追踪信息传回之前的步骤,以完善后续的追踪结果。这使得各步骤之间的耦合更加紧密。
纯 CV 流水线:该用例是不涉及机器学习网络的纯计算机视觉流水线。每个步骤都是可预测和可解释的,只侧重于传统的 CV 算法。
通过使用 PVA 执行这些任务,用户可以减轻 GPU、VIC、CPU 和 DLA 的负载,提高系统的稳定性和效率。
蔚来汽车数据流水线优化
蔚来汽车是一家知名的全球化汽车制造商,致力于高端智能电动汽车的设计、开发和生产。
以下是来自蔚来的数据处理流水线,涉及使用专门的算法和技术对实时摄像头或 H.264 视频中的感兴趣区域和对象进行去识别、遮蔽或替换。
原始数据流水线方案
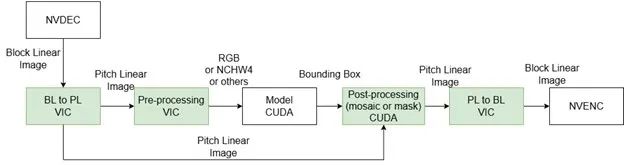
图 4. 蔚来的数据流水线
图 4 表示蔚来数据流水线的原始版本。NVDEC 用于解码 H.264 视频,生成 block linear 格式的 YUV 图像。由于 block linear 是 NVIDIA 特有的内部格式,因此外部用户无法直接处理这些图像。VIC 引擎被用于将 block linear 图像转换为 pitch linear 格式,以便进一步处理。
接下来,使用 VIC 引擎进行色彩转换(从 YUV 转换为 RGB)以生成 RGB 图像。然后,AI 模型会先对这些图像进行分析,以检测感兴趣的物体。在 AI 模型为物体生成边界框后,使用 VIC 或 CUDA 的后处理步骤将马赛克或蒙版应用于原始 YUV pitch linear 图像。
最后,使用 VIC 引擎将处理过的帧从 pitch linear 格式转换回 block linear 格式,然后使用 NVENC 将其回编成 H.264 视频。
使用 PVA 替换 CV 运算
在蔚来的案例中,GPU 和 VIC 的负载都很重。该流水线涉及多个 CV 运算,包括以下方面:
block linear 和 pitch linear 格式之间的布局转换
从 YUV 到 RGB 的颜色转换
加马赛克和加掩码
这些运算可以卸载到 PVA,以节省 GPU 和 VIC 的资源。
布局转换和色彩转换是 PVA 的内存受限任务,而 DMA 带宽是瓶颈。可以使用 PVA 中的其他计算资源进行基于边界框和 YUV PL 图像的加马赛克和加掩码。
为了进一步加快执行速度,还可以并行运行 PVA 算法,由于每个 PVA 实例都包含两个 VPU,每个 VPU 都有一个独立的 DMA 控制器,用于与 DRAM 交换数据。
在实施 PVA 内核时,还可以采用其他几种技术来提高整体性能,包括 DLUT、基于硬件的循环地址生成(AGEN)、乒乓缓冲区、循环展开等。
数据流水线优化
传统数据处理流水线中的时延可能来自两个方面:
在不同功能模块或硬件加速器(例如本用例中的 PVA 和 DLA)之间复制数据会产生额外开销。
执行和同步多个算法进程所需的额外同步开销。
使用 NVIDIA DriveOS SDK 提供的 NvStreams 框架可以减少这些开销。而 PVA 硬件加速器可以利用 PVA SDK 中的 NvSci 互通性 API 与 NvStreams 高效配合,实现零拷贝数据转换和异步任务提交,从而将开销降至最低。
零拷贝接口
不同硬件组件(例如 PVA 和 CPU)和应用对内存缓冲区有各自的访问限制或要求。为了实现零拷贝的目标,可采用统一的内存架构,使加速器能够与不同的应用在 NVIDIA DRIVE SoC 上共享同一物理内存。
在分配内存缓冲区之前,应收集和协调详细的需求以确保所分配的内存缓冲区可在必要的模块之间共享。该功能是通过 NvStreams API 实现的。
在成功分配可共享的内存缓冲区后,就能以零拷贝的方式进行不同硬件模块或应用之间的数据转换。这种解决方案适用于涉及进程间通信(IPC)或跨虚拟机(VM)的情况。如果是芯片间的数据传输,可在同一个 NvStreams 框架下使用高速 PCIe。
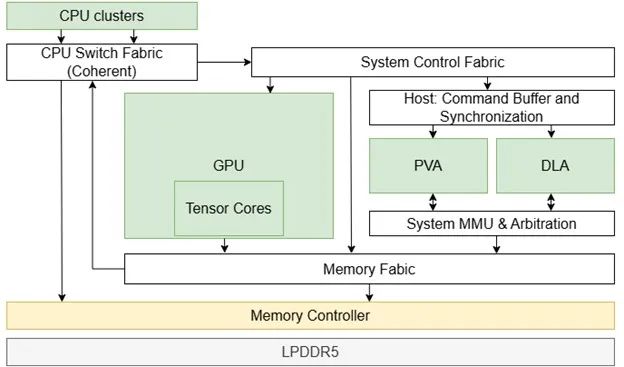
图 5. NVIDIA DRIVE SoC(Orin)架构
基于硬件加速器的调度
蔚来的数据流水线集成了多个硬件加速器,可以使用 NvSciSync 管理这些引擎之间的同步。NvSciSync 是 NVIDIA NvStreams 库的一部分,通过管理同步对象来协调执行各种硬件组件的操作。
首先,在加速器上运行的任务之间插入同步点。当任务开始时,后续硬件加速器会在同步点等待,直到前面的任务完成。任务完成后,相应的硬件加速器会释放同步点,自动触发下一个加速器继续执行任务。这一过程尽可能减少了 CPU 的占用,只需进行一些初始设置,并确保跨硬件引擎的高效同步。
基于 PVA 任务级别的调度
在原始流水线中,所有任务的提交和同步都由 CPU 逐个控制。这意味着 CPU 将任务提交给计算引擎,然后以同步的方式等待每个算法任务完成。
PVA 支持同时提交多个任务,并只等待最后一个任务。所有提交的 PVA 任务都将同时按照指定顺序进行计算,直到所有任务完成。批量提交多个任务可减少与提交 PVA 任务相关的 CPU 负载,从而优化性能。这样就能解放 CPU 处理其他重要的任务,并减少系统的整体时延。
借助 PVA SDK,用户也可以为 PVA 算法指定调度策略以充分利用 PVA 实例上的两个 VPU。例如,用户可以指定在单颗 VPU 上执行某些算法。
同时使用两个 VPU 时,如果任务之间有顺序要求,可以在两个 VPU 上依次设置要执行的任务。如果没有顺序要求,PVA 任务会在 VPU 空闲时立即执行。这大大降低了多任务的执行时延。
生产就绪
图 6 显示了蔚来使用 PVA 替换 CV 操作并将 DL 模型移植到 DLA 引擎后可用于生产的蔚来数据流水线。如需了解更多信息,请参阅《在 NVIDIA Jetson Orin 上部署 YOLOv5 与 cuDLA:量化感知训练到推理》。
https://developer.nvidia.com/zh-cn/blog/deploying-yolov5-on-nvidia-jetson-orin-with-cudla-quantization-aware-training-to-inference/

图 6. 用于生产的数据流水线
在这个经过优化的流水线中,PVA 和 DLA 解决方案有效地满足了业务需求。这种方法既可行又高效。从而使整体 GPU 资源利用率降低 10%,同时释放 VIC 引擎用于系统内的其他高优先级任务。在 block linear 和 pitch linear 格式的转换过程中,无需为临时变量预先分配额外的内存,从而大大节省了内存。
根据蔚来的内部评估,在系统中运行该流水线时,PVA 在 1 个 VPU 实例上的负载约为 50%。由于 1 个 PVA 包含两个 VPU,蔚来数据流水线中的 PVA 总负载约为 25%。这表明 PVA 仍有可用的算力处理该流水线中的其他任务。
进一步优化
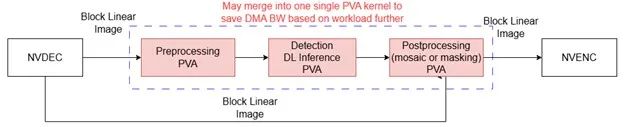
图 7. 用于进一步优化的数据流水线
为了进一步优化该流水线,可以采取以下步骤:
使用 PVA 将 DLA 替换为简单的深度学习模型,因为 PVA 目前仅有约 25% 的使用率。内部测试表明,Yolo-Fastest 网络可以成功移植到 PVA 上,并且其检测对象的能力符合预期。
考虑将预处理、深度学习推理和后处理阶段合并到单颗 PVA 内核中,这样就不需要在内核之间进行额外的 DMA 传输,从而降低 DMA 总带宽。
结语
基于 PVA 的优化解决方案显著提高了蔚来的性能,并被广泛应用于蔚来的量产车型中。通过将任务卸载到 PVA,可以解放 GPU 计算资源,从而加速深度学习计算并使用户能够实施更加复杂的深度学习网络。
蔚来正在积极借助 PVA SDK 在 PVA 上开发更高效的 PVA 算法,以便充分利用 NVIDIA DRIVE 平台的额外算力,提高其产品的智能和竞争力。
总之,PVA 提供了强大的工具来解决自动驾驶汽车开发中的计算问题,从而能够更高效、更有效地处理复杂的视觉任务,并提高整体系统性能。
-
谷歌的自动驾驶汽车是酱紫实现的吗?2011-06-14 4834
-
汽车自动驾驶技术2016-04-14 5610
-
自动驾驶汽车的处理能力怎么样?2019-08-07 2929
-
什么是流水线技术2010-02-04 4431
-
电镀流水线的PLC控制2016-02-17 1350
-
电能计量设备自动检定流水线调度优化研究_方彦军2017-01-18 850
-
如何利用乐高积木制作成自动化流水线2019-05-22 7724
-
各种流水线特点及常见流水线设计方式2021-07-05 10456
-
如何选择合适的LED生产流水线输送方式2021-08-06 1550
-
基于非常简单的Python代码就能完成流水线开发2021-11-16 3908
-
什么是流水线 Jenkins的流水线详解2023-05-17 1847
-
NIO的自动驾驶AI推理工作流2023-07-05 1722
-
超级方便的轻量级Python流水线工具2023-10-31 1712
-
SMT流水线布局优化技巧2024-11-14 2433
-
远程io模块在汽车流水线的应用2025-06-11 909
全部0条评论

快来发表一下你的评论吧 !
