

Xilinx 7系列FPGA PCIe Gen3的应用接口及特性
描述
以下文章来源于FPGA技术实战 ,作者FPGA技术实战
前言: Xilinx7系列FPGA集成了新一代PCI Express集成块,支持8.0Gb/s数据速率的PCI Express 3.0。本文介绍了7系列FPGA PCIe Gen3的应用接口及一些特性。
1. PCI Express规范演进
PCIe是一种高速串行计算机扩展总线标准,旨在替代传统的PCI和AGP总线标准,提供更高的数据传输速率和更好的信号完整性。PCIe规范自2003年推出以来,已经从最初的1.0升级到了7.0,提供了更高的带宽和速度。表1总结了PCIe基本规范的演变。
表1:PCIe基本规范的演变
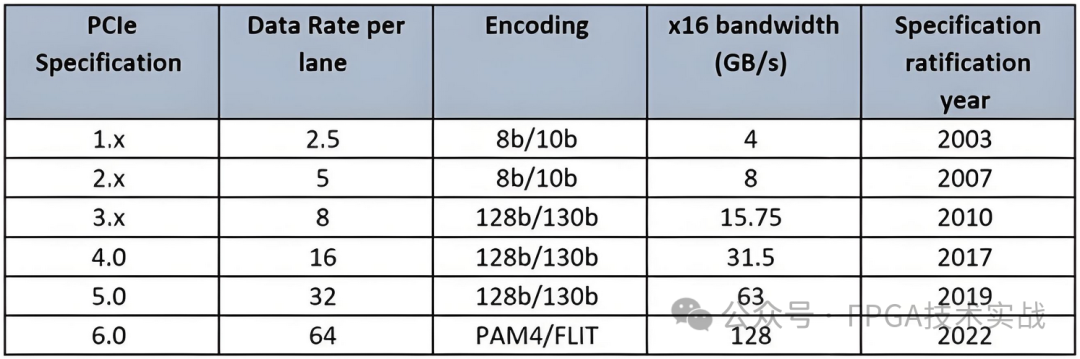
1.由于数据包开销、流量开销和其他系统效率低下,可实现的系统带宽小于有效带宽。
除了修订基本规范外,PCI-SIG还推广了支持特定应用的配套规范。一个正在迅速采用的配套规范是I/O虚拟化,特别是Single Root I/O虚拟化(SR-IOV)。SR-IOV大大提高了共享和虚拟化环境中的I/O利用率,Xilinx 7系列FPGA支持此功能。
2. 7系列FPGA PCI Express概述
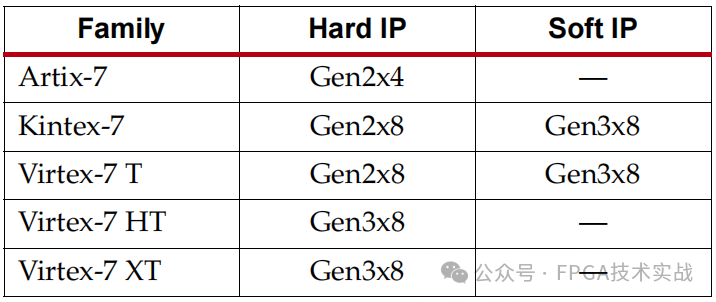
每个Xilinx 7系列FPGA系列都支持PCIe集成根端口和端点解决方案。Artix-7设备最多支持Gen2x4硬核配置。Kintex-7和Virtex-7 T设备最多支持Gen2x8硬核配置。Virtex-7 XT和HT设备具有集成的Gen 3硬核内核,最多8个通道。除了PCIe IP的集成外,第三方联盟合作伙伴Northwest Logic和PLDA还提供针对Kintex-7和Virtex-7系列的Gen3x8软IP解决方案。表2总结了每个器件家族支持的IP层级。
表2:7系列FPGA支持的Lane宽度和速度等级
7系列FPGA的集成IP可以使用简单的基于GUI的工具流进行配置,以创建端点、根端口或根复合体解决方案。系统设计者能够控制许多可配置的参数,如通道宽度、线速率、最大有效载荷大小、FPGA逻辑接口速度、参考时钟频率和基址寄存器设置。另外,Xilinx还提供参考设计以加快设计进度。这些目标参考设计包括PCIe设计的所有组件,如DMA控制器、自定义IP、设备驱动程序和软件应用程序。
3. 用于Virtex XT和HT设备的PCI Express Gen 3集成IP
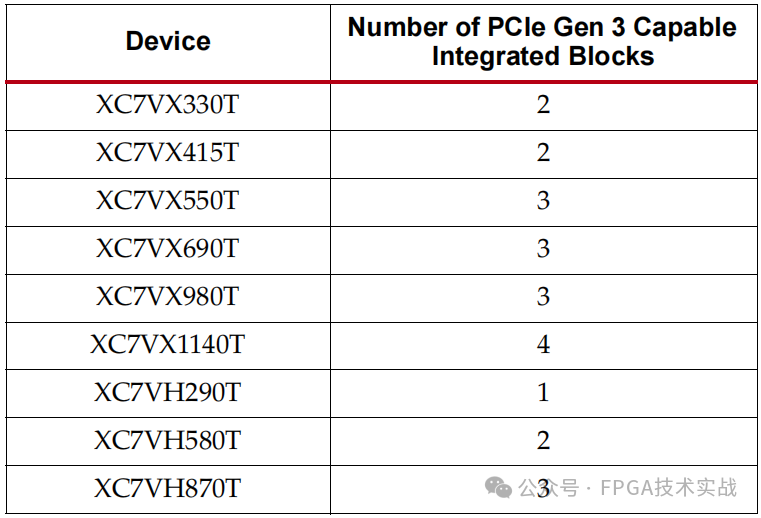
Virtex-7 XT和HT设备支持多个集成的Gen 3集成块,每个集成块最多八个通道。该集成块能够使用128B/130B编码以每通道8.0Gb/s的规定数据速率运行。表3显示了具有Gen 3集成块的7个系列器件以及每个设备的块数。
表3:Virtex-7 系列具有Gen 3功能的硬块器件
3.1 PCIe Gen 3收发器在7系列中的优势
GTH收发器包含允许在PCIe Gen 3数据速率下非常稳健运行的功能。这些功能包括:
•收发器加重/均衡
•自适应连续时间线性均衡器(CTLE)
•自适应决策反馈均衡器(DFE)
收发器加重电路设计用于克服高频信道插入损耗,并实现为3抽头FIR滤波器。这些抽头是可编程的,通常,用户不需要显式设置抽头值,因为这是由PCIe Gen 3链路均衡协议自动处理的。
GTH收发器中的CTLE和DFE电路协同工作,可补偿高达20dB的损耗。CTLE采用全自动自适应算法,持续监测输入信号,并优化高通滤波器功能的频率响应。这种自适应功能减轻了用户的负担,解决了过均衡或欠均衡的问题。
DFE由七个固定抽头和四个独立的滑动抽头实现。当PCIe在背板上使用时,这非常有用,这在许多有线通信和数据中心应用中都很常见。与CTLE类似,DFE也完全自适应于抽头值和滑动抽头的位置。
3.2 PCIe Gen3数据吞吐量
PCI-SIG的目标是将每一代PCIe的有效数据吞吐量翻一番,第3代也不例外。重要的是要注意,有效数据吞吐量(有时称为有效数据传输速率)与原始数据传输速率(如8Gb/s线路速率)不同。有效数据吞吐率取决于许多变量,例如:
•Lane宽度
•线速率
•系统最大有效负载大小和最大读取请求大小
•TLP开销
•链路管理(数据链路层数据包)
•编码丢失
•DMA开销
当配置为在具有256字节系统最大有效负载大小的真实系统中运行的具有x8 Gen 3功能的内核时,用于PCIe的7系列Gen 3集成块能够实现每个方向超过7GB/s的持续吞吐量。
3.3 与内存接口
大多数PCIe应用程序使用某种类型的内存进行数据缓冲,通常是DDR SDRAM。
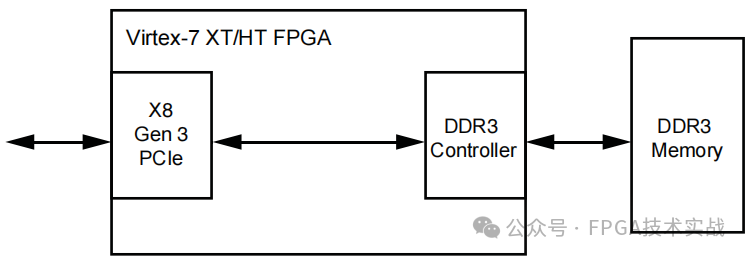
图1:DDR3内存与Virtex-7 XT/HT FPGA的接口
在确定内存带宽要求时,设计人员应使用2.5倍的带宽乘数来考虑读写方向和任何额外的开销,如内存寻址。
例如,如果从PCIe链路持续传输6.5GB/s,并且所有这些数据都缓冲在DDR3内存中,则设计人员可以计算以下内容以确定内存带宽和/或接口宽度要求。
确定内存带宽要求
持续传输所需的总内存带宽:
6.5 GB/s*2.5=16.25 GB/s
示例:如果使用具有1866Mb/s DDR3功能的内存,设计人员可以计算数据接口必须有多宽才能跟上16.25 GB/s。转换为Gb/s:
16.25GB/s*8位/字节=130Gb/s。
计算DDR3内存所需的接口宽度:
每个引脚130 Gb/s÷1866 Mb/s=约70个引脚
此计算表明,以1866 Mb/s运行的标准72针DDR3接口可以跟上x8 Gen 3 PCI Express链路的全双工数据。支持较慢DDR数据速率(如1600 Mb/s)的FPGA需要额外的引脚和组件。
3.4 PCIe Gen3其他高性能功能
PCIe Gen3集成块包含许多功能,可实现更好的系统性能。这些功能包括:
•用于流量类型的高性能专用AXI4接口(增强型AXI-4流)
•跨越256位宽接口的数据
•内置标签管理,最多可处理64个未完成的读取请求
•灵活的接收缓冲;可配置高达8KB的请求空间和16KB的完成空间
•内置多功能和SR-IOV支持
AXI4接口上的奇偶校验保护
•对所有内部缓冲存储器进行ECC保护
•可调整大小的基址寄存器(RBAR)
•地址翻译服务(ATS)
•原子操作事务
•TLP处理提示能力(TPH)
•优化缓冲区冲洗/填充能力(OBFF)
•动态功率分配能力(DPA)
•功率预算能力(PB)
3.5 可扩展、优化的AXI接口
Xilinx部署的AMBA4 AXI4规范允许以一致的方式连接IP块,同时更好地利用设计资源。
所有适用于7系列FPGA的PCIe解决方案均按照AMBA4 AXI4规范设计。AXI接口提供了三种风格,每种风格都针对不同的客户用例量身定制。
1.Basic AXI4-Stream: 此接口类似于旧Xilinx FPGA系列中的传统TRN接口。该接口是将基于TRN的设计迁移到7系列设备的最简单接口,由发送和接收AXI4流接口组成。此接口可用于Artix-7、Kintex-7和Virtex-7 T FPGA上的PCI Express解决方案(在Virtex-7 XT设备上不可用)。
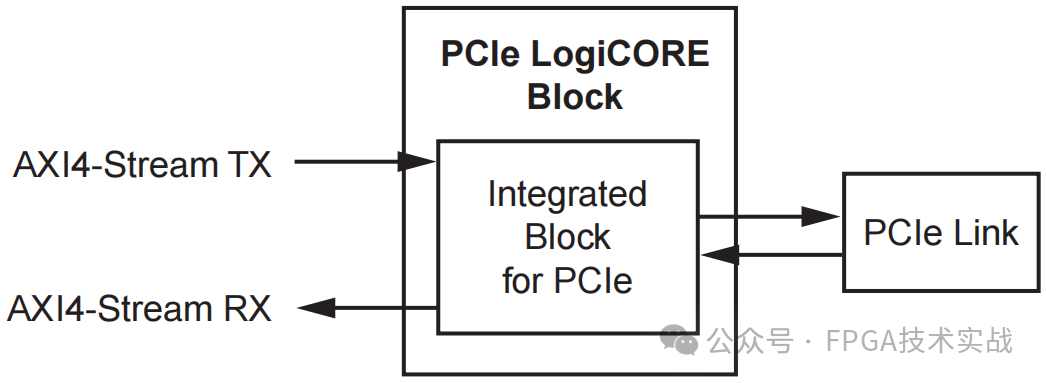
图2:AXI4流基本界面
2.Enhanced AXI4-Stream: 此接口类似于基本的AXI4 Stream接口,但通过将数据流拆分/组合为Completer和Requester流对其进行了扩展。增强版本还允许可选功能,如数据包去分级、数据重新排列和完成标签管理。此接口可用于PCI Express解决方案的Virtex-7 HT和XT FPGA(在Virtex-7 T、Artix-7和Kintex-7设备上不可用)。见图3。
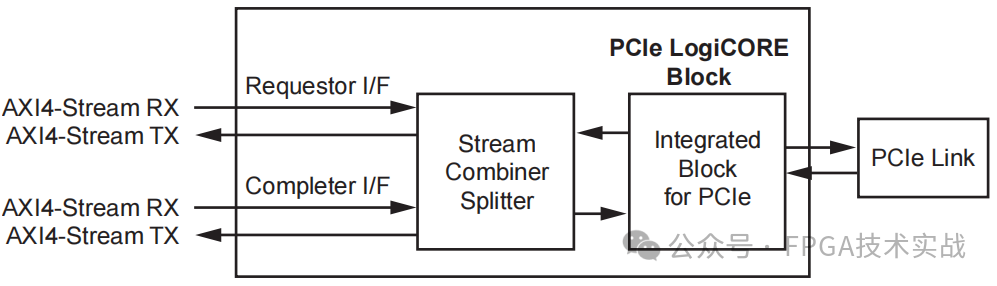
图3:增强型AXI4流接口
3.AXI4: 这是一个内存映射接口,用于基于处理器系统的内核。此接口是嵌入式设计的迁移路径,可用于PCIe解决方案的Artix-7、Kintex-7和Virtex-7 T、HT和XT FPGA。
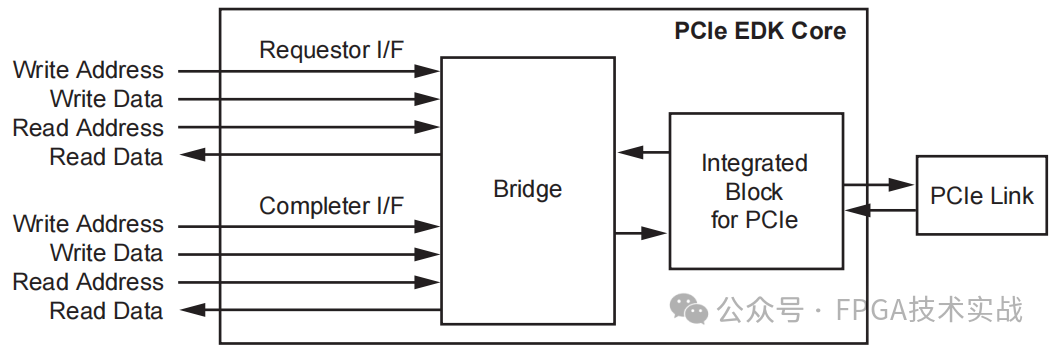
图4:AXI4接口
4. 7系列FPGA的PCIe新功能
7系列FPGA PCIe解决方案中添加了许多新功能,为设计人员提供了PCIe性能、灵活性和易用性。
4.1 PCIe IP块的快速初始化
PCIe基本规范要求PCIe链路在电源稳定后100ms内准备好进行链路训练。传统上,这对大型FPGA(>100000个逻辑单元)来说是一个挑战,因为使用常见的闪存设备配置大型FPGA可能需要100多ms。
传统上使用"蛮力"方法来解决100ms的要求。通常,设计人员使用最快、最宽的闪存设备来实现必要的带宽,以满足配置时间要求。在某些情况下,需要使用多个闪存设备和CPLD来实现所需的带宽。虽然从软件的角度来看,这可能是最简单的方法,但由于BOM成本的增加,它通常是最昂贵的。这种方法还使用了宝贵的FPGA I/O,特别是在使用宽输入总线时,并且随着Xilinx FPGA的尺寸增长到200万个逻辑单元甚至更高,这种方法很快就会过时。
注意:此问题通常仅限于端点附加卡设计。
4.2 Tandem PROM和Tandem PCIe
Tandem PROM方法是7系列器件中的新方法,是最简单、最便宜的实现方法。在构建PCIe IP核时,用户指示实现工具通过简单的软件交换机创建两级比特流。比特流的第一阶段仅包含配置PCIe集成块所需的配置帧。配置后,FPGA启动序列发生,PCIe链路变为活动状态,因此很容易满足100毫秒的要求。然后,在PCIe枚举/配置系统过程中加载FPGA配置的其余部分。两阶段比特流方法可以使用廉价的闪存设备来保存比特流。
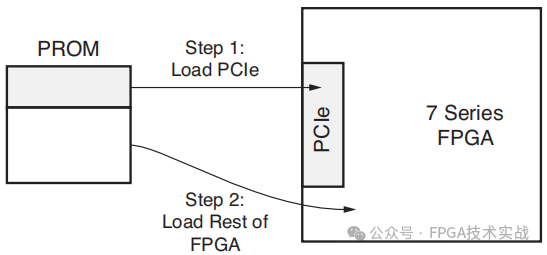
图5:串联PROM方法
Tandem PCIe解决方案基于Tandem PROM技术构建,允许用户通过PCI Express链路加载第二级比特流。
4.3部分重构
要实现通过PCIe连接的多个用户应用程序,可以使用部分重新配置工具流。该方法依赖于比特流压缩来满足100ms的要求。初始比特流包含与内部配置访问端口(ICAP)连接的PCe IP核。FPGA的大部分未配置。然后通过使用比特流压缩来减小初始比特流的大小,从而允许快速初始化。
FPGA未配置部分的部分比特流通过PCe链路实时下载。使用部分重新配置工具流,设计者创建一个或多个可以驻留在主机中的应用程序(部分比特流)。高性能计算市场中的协同处理算法加速器等应用受益于这种动态可重编程性。
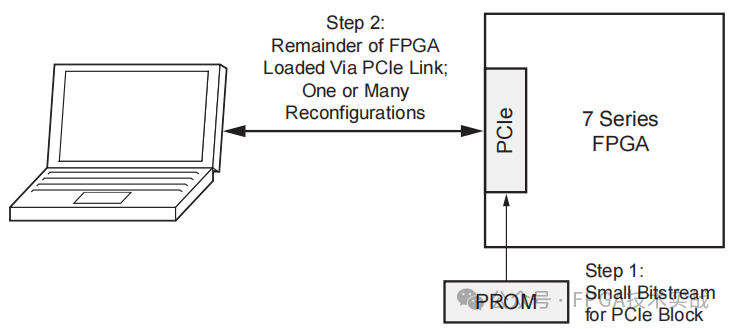
图6:部分重新配置工具流程
4.4数据跨接
Xilinx对7系列FPGA中的PCIe集成块进行了许多增强,以提高内核的性能。大多数基于FPGA的解决方案要求用户界面上的事务层数据包(TLP)以对齐的方式接收,即当TLP结束时。在下一个时钟周期之前,无法从IP核读取下一个TLP。
这些解决方案在数据流中引入了缺口,从而降低了整体数据吞吐量。7系列FPGA能够在用户界面上跨包(允许一个TLP在同一时钟周期结束,而另一个开始),从而允许PCIe内核以全线速率运行。这对于需要全线速带宽的超高端应用非常重要。对于不需要极端带宽且更喜欢对齐数据包的应用程序,增强的AXI Stream接口具有可选的对齐功能。
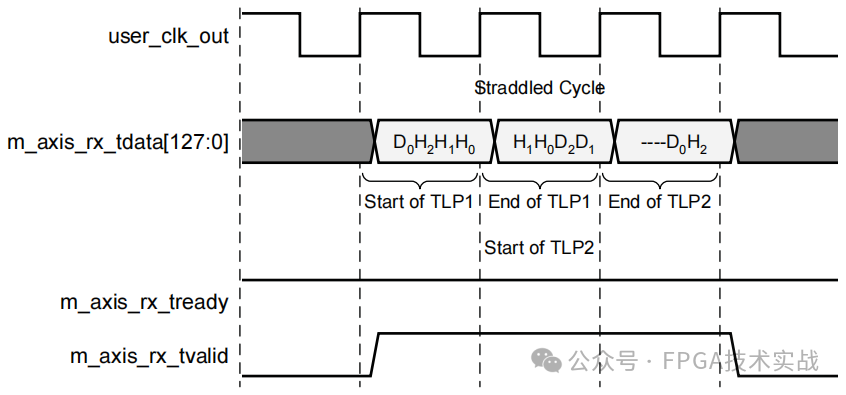
图7:7系列数据跨接
除了支持跨数据包外,7系列FPGA还具有提高整体性能的功能,例如改进了用户对信用分配方案的控制,以及新的流量控制功能,使用户能够更精细地控制已发布和未发布的流量。
4.5 读取请求完成的标签管理
当传输大于典型系统读取完成边界大小64字节的读取请求TLP时,设计者必须承担的一项艰巨任务是处理多个完成和无序返回。通常,设计者必须存储传出读取请求的标签,然后将这些标签与传入的完成TLP进行协调和管理。此外,设计者还必须监控错误情况,如完成超时。
标签管理是发送读取请求的总线主控DMA设计的一个必要功能,换句话说,就是从生产者“拉取”数据。这是通过管理传出读取请求的标签并将传入的完成与这些标签进行协调来实现的。Virtex-7 HT和XT设备的PCIe解决方案可选地提供此标签管理功能,大大简化了DMA设计人员的设计要求。
4.6 多功能
7系列FPGA能够作为多功能设备运行。这种类型的设备具有多种功能,所有功能都共享一个PCIe链路。每个功能都有自己的PCIe配置头空间。因此,从主机系统软件的角度来看,每个功能在其自己的PCIe链路上都表现为一个单独的PCIe设备。这大大简化了设备驱动程序的开发和可移植性,因为驱动程序开发人员可以创建单个驱动程序,并为每个硬件功能复制它。见图8。
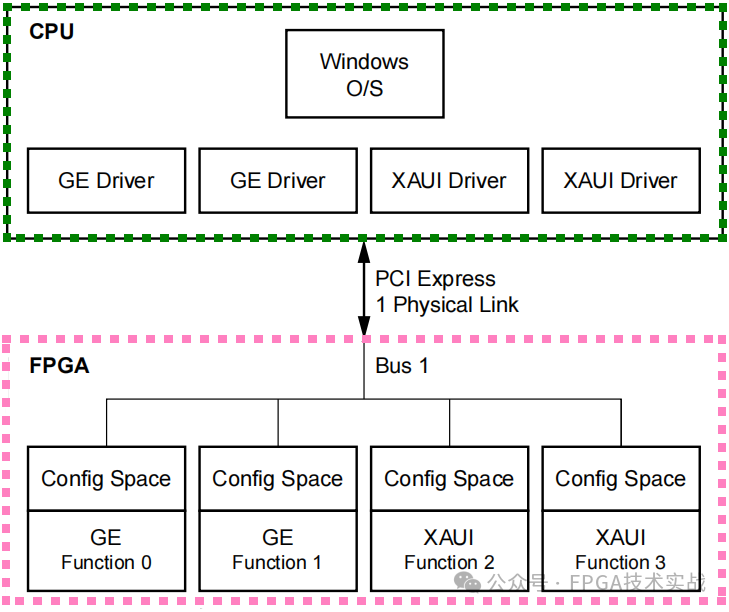
图8:多功能设备
4.7 Single Root I/O虚拟化
Single Root I/O虚拟化(SR-IOV)允许在单个root(CPU子系统)上运行的多个客户机(操作系统)访问I/O设备,而不会在不支持SR-I0V的虚拟化系统中产生软件损失。类似于多功能设备如何为每个物理功能提供单独的配置空间,SR-IOV通过为访问I/O设备的每个客户操作系统提供虚拟功能(虚拟配置空间)来工作。因此,每个客户操作系统都有自己的I/O设备“视图”。
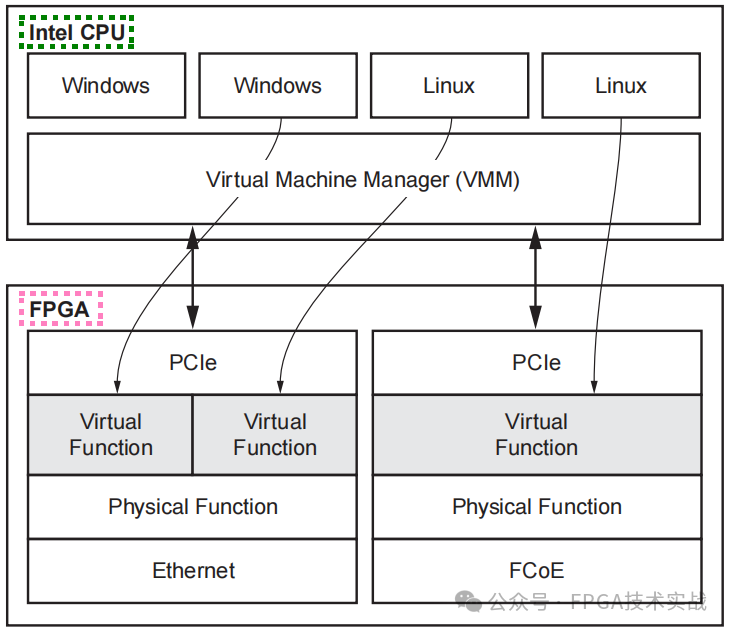
图9:SR-IOV虚拟配置空间
支持SR-IOV的适配器在虚拟化环境中的I/O效率方面有了巨大的提高。SR-IOV不仅成为企业IT市场(数据中心)广泛采用的标准,而且开始在通信和存储网络市场取得进展。
4.8 高级错误报告和端到端CRC
高级错误报告(AER)是一个可选功能,它为基于PCIe的系统中可能发生的错误类型提供了更大的粒度和控制。在非AER PCIe系统中,只定义了三种类型的错误:致命、非致命和可纠正。在大多数情况下,这三种定义的错误类型没有为系统提供足够的信息,无法从错误中优雅地恢复。启用AER后,系统软件可以确定特定错误的确切原因,并在可能的情况下尝试恢复。
当用户启用时,7系列FPGA中的PCIe集成块可选择执行自动端到端CRC(ECRC)检查和生成。已添加新端口以控制错误生成,并在检测到ECRC错误时进行标记。设计者不再需要在FPGA中设计这种逻辑。AER和ECRC用于高可靠性和高可用性是关键驱动因素的应用。这些功能通常用于航空航天和国防、银行和金融、通信和存储等细分市场。
4.9 可调整大小的BAR
许多端点应用程序包含大量的本地内存,例如,高端图形卡可以包含超过1 GB的DDR3 SDRAM。如基于32位的操作系统,无法将如此多的内存资源分配给单个实体。如果适配器没有实现某种孔径窗口方案,操作系统通常会忽略资源请求。因此,系统无法使用适配器。可调整大小的基址寄存器(BAR)功能为设计者提供了一些控制,这样就不会发生这种情况。如果系统无法分配适配器请求的全部资源,它可以将BAR调整到更小、更可接受的孔径,从而使适配器仍能在系统内运行。7系列FPGA中的PCIe解决方案完全支持可调整大小的BAR功能。
4.10 Atomic操作
Atomic Operations引入了三种新的TLP类型,旨在通过直接在I/O总线(在本例中为PCIe)上创建标准同步原语(如互斥和自旋锁)来提高系统性能和延迟。这在任何具有多个生产者和消费者的系统中都很有用,例如多CPU系统。此功能的目标应用程序空间是协同处理和硬件加速适配器。
本文转载自FPGA技术实战公众号
-
Altera Stratix V GX FPGA实现了与PCIe Gen3的兼容2013-05-23 2327
-
LX2160A-CEX7有没有办法强制或降级 NVMe 设备在 PCIe Gen3 而不是 Gen4 上运行2026-06-17 226
-
用于 PCIe Gen-3 卡的高速前端参考设计2015-05-08 6961
-
基于FPGA的高速以太网适配器卡必备的PCIe Gen3技术2017-02-10 6153
-
PCIe GEN3 ECRC仅在离线模式下出错2018-11-05 2370
-
为什么在我的PCIe Gen3插槽上使用VC709不起作用?2019-09-09 3415
-
请问XC7K325T-2FFG900支持PCIE PHY GEN3吗?2020-07-25 2719
-
符合PCIe Gen1,Gen2和Gen3标准的9端口PCIe时钟发生器2020-08-27 4051
-
PCIE高速传输解决方案FPGA技术XILINX官方XDMA驱动2021-05-19 6984
-
PCIe Gen-3高速前端卡参考设计2022-09-21 1541
-
Layerscape MPU中是否有支持PCIe GEN3 16通道的EVB?2023-05-30 965
-
Altera率先实现Stratix V GX FPGA与PCIe Gen3交换机互操作2011-12-14 1134
-
Virtex-7 FPGA Gen3 Integrated Block 的 TAG 管理2017-11-18 2181
-
PCIe x8 Gen3在Xilinx Kintex-7 FPGA KC705板上的运行演示2019-01-04 5849
-
UltraScale FPGA器件中PCIe Gen3模块的性能演示2018-11-28 4645
全部0条评论

快来发表一下你的评论吧 !
