

GPU服务器AI网络架构设计
描述
众所周知,在大型模型训练中,通常采用每台服务器配备多个GPU的集群架构。在上一篇文章《高性能GPU服务器AI网络架构(上篇)》中,我们对GPU网络中的核心术语与概念进行了详尽介绍。本文将进一步深入探讨常见的GPU系统架构。
8台配备NVIDIA A100 GPU的节点/8台配备NVIDIA A800 GPU的节点
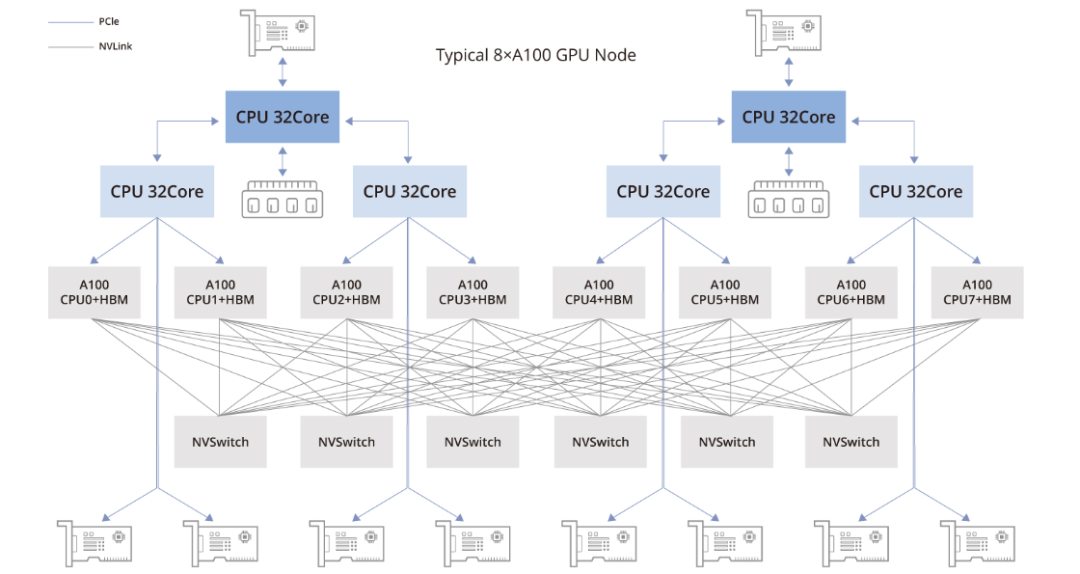
如上图所示的A100 GPU拓扑结构中,8块A100 GPU所组成的拓扑包含以下组件:
两颗CPU芯片(及其两侧相关的内存,NUMA架构):中央处理器负责执行通用计算任务。
两块存储网络适配卡(用于访问分布式存储,具备带内管理等功能):这些网卡用于访问分布式存储资源。
四颗PCIe Gen4交换芯片:PCIe Gen4是PCIe接口的第四代,提供了更高的数据传输速率。
六颗NVSwitch芯片:NVSwitch使得GPU与GPU之间能够以极高的速度直接通信,这对于大规模深度学习节点和并行计算任务的有效运行至关重要。
八块GPU:A100 GPU作为主要处理单元,负责执行并行计算,尤其适合人工智能和深度学习工作负载。
八块GPU专用网络适配卡:每块GPU配备一块专用的网络适配卡,旨在优化GPU之间的通信,并提升并行处理任务的整体性能。
接下来的部分我们将对这些组件进行详细解读。下一张图片将提供更详尽的拓扑结构信息供参考。
存储网络卡
在GPU架构中,存储网络卡的定位主要涉及其通过PCIe总线与中央处理器(CPU)的连接,以及负责促进与分布式存储系统的通信。以下是存储网络卡在GPU架构中的主要作用:
读写分布式存储数据:存储网络卡的主要功能之一是高效地从分布式存储系统读取和写入数据。这对于深度学习模型训练过程至关重要,在此过程中频繁访问分布在各处的训练数据以及将训练结果写入检查点文件极为重要。
节点管理任务:存储网络卡的功能不仅限于数据传输,还包括节点管理任务。这包括但不限于通过SSH(安全外壳协议)进行远程登录、监控系统性能以及收集相关数据等任务。这些任务有助于对GPU集群的运行状态进行监控和维护。
虽然官方推荐使用BF3 DPU,但在实践中,只要满足带宽需求,可以选用其他替代解决方案。例如,为了成本效益考虑,可以考虑使用RoCE;而为了最大限度提升性能,则优先选择InfiniBand。
NVSwitch 网络结构
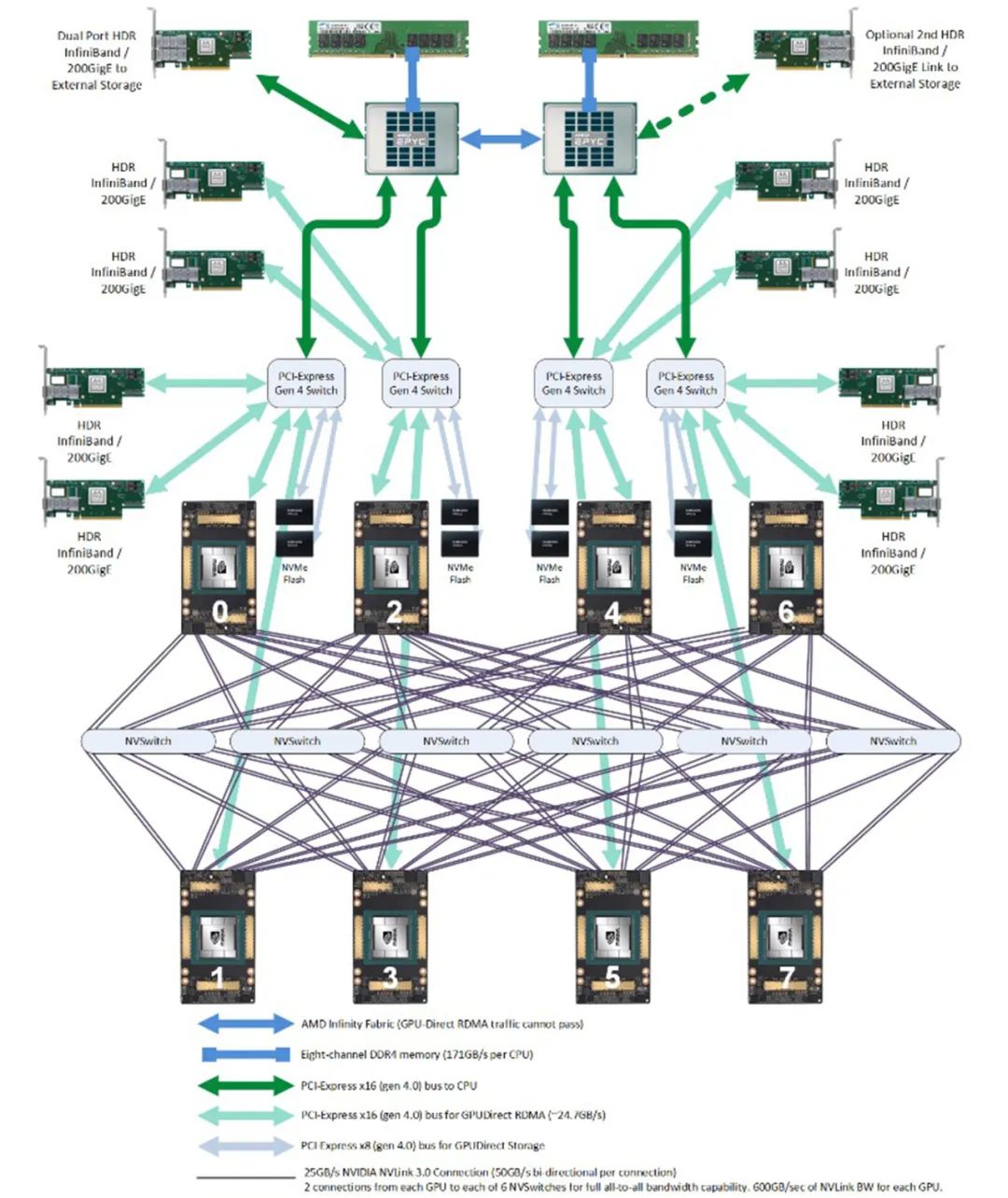
在完全互联网络拓扑中,每个节点都直接与所有其他节点相连。通常情况下,8块GPU通过六个NVSwitch芯片以全互联配置相连接,这一整体也被称为NVSwitch架构。
在全互联结构中,每条线路的带宽取决于单个NVLink通道的带宽,表示为n * bw-per-nvlink-lane。对于采用NVLink3技术、每条通道带宽为50GB/s的A100 GPU,在全互联结构中,每条线路的总带宽为12 * 50GB/s = 600GB/s。需要注意的是,此带宽是双向的,既支持数据发送也支持接收,因此单向带宽为300GB/s。
相比之下,A800 GPU将NVLink通道的数量从12减少到了8。因此,在全互联结构中,每条线路的总带宽变为8 * 50GB/s = 400GB/s,单向带宽为200GB/s。
以下是一个由8*A800组成的设备的nvidia-smi拓扑结构图示。

GPU与GPU之间的连接(左上区域):所有连接均标记为NV8,表示有8条NVLink连接。
网络接口卡(NIC)连接:在同一CPU芯片内:标记为NODE,表示无需跨越NUMA结构,但需要穿越PCIe交换芯片。在不同CPU芯片之间:标记为SYS,表示必须跨越NUMA结构。
GPU至NIC的连接:在同一CPU芯片内且处于同一PCIe交换芯片下:标识为NODE,表示仅需穿越PCIe交换芯片。
在同一CPU芯片内但不在同一PCIe交换芯片下:指定为NNODE,表示需要同时穿越PCIe交换芯片和PCIe主机桥接芯片。
在不同CPU芯片之间:标记为SYS,表示需要跨越NUMA结构、PCIe交换芯片,并覆盖最长距离。
GPU节点互联架构
以下图表展示了GPU节点间的互联架构:
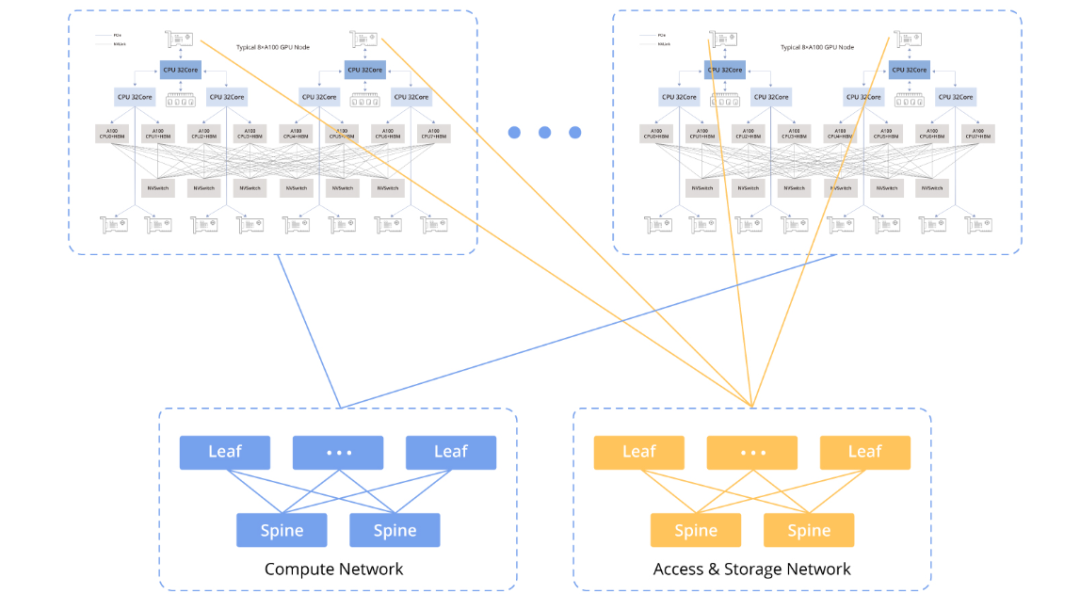
计算网络
计算网络主要用于连接GPU节点,支持并行计算任务之间的协同工作。这包括在多块GPU之间传输数据、共享计算结果以及协调大规模并行计算任务的执行。
存储网络
存储网络用于连接GPU节点和存储系统,支持大规模数据的读写操作。这包括将数据从存储系统加载到GPU内存中,以及将计算结果写回存储系统。
为了满足AI应用对高性能的需求,在计算网络和存储网络上,RDMA(远程直接内存访问)技术至关重要。在两种RDMA技术——RoCEv2和InfiniBand之间进行选择时,需要权衡成本效益与卓越性能,每种选项都针对特定应用场景和预算考虑进行了优化。
公共云服务提供商通常在其配置中采用RoCEv2网络,例如CX配置,其中包含8个GPU实例,每个实例配备8 * 100Gbps。与其他选项相比,只要能满足性能要求,RoCEv2相对较为经济实惠。
数据链路连接中的带宽瓶颈
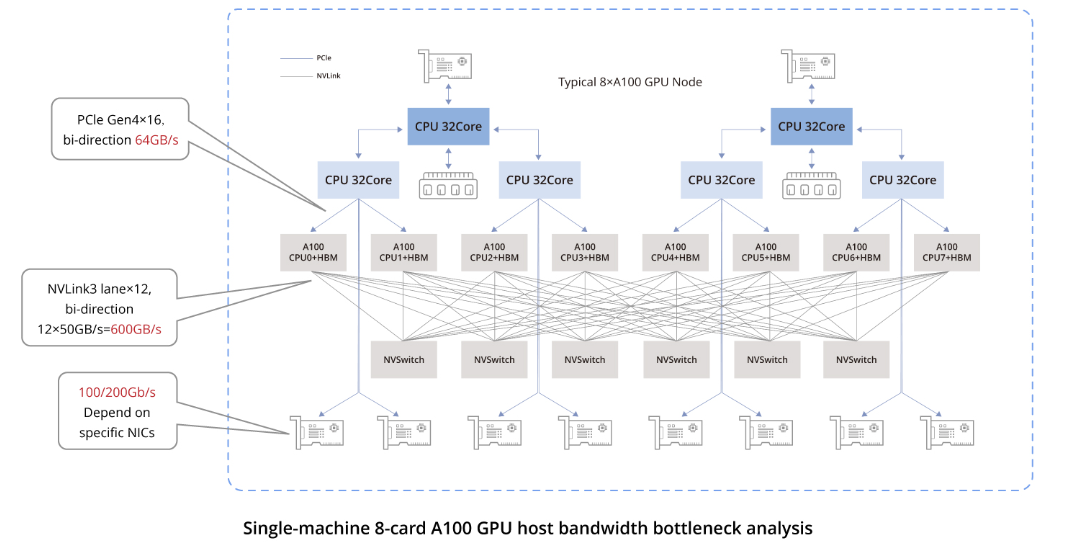
该图表突出了关键连接的带宽规格:
同一主机内GPU之间的通信:通过NVLink技术,双向带宽达到600GB/s,单向带宽达到300GB/s。
同一主机内GPU与其各自网络接口卡(NIC)之间的通信:采用PCIe Gen4交换芯片,双向带宽为64GB/s,单向带宽为32GB/s。
不同主机间GPU之间的通信:数据传输依赖于NIC,带宽取决于所使用的具体NIC。当前在中国,对于A100/A800型号常用的NIC提供主流的单向带宽为100Gbps(12.5GB/s)。因此,相较于同一主机内的通信,不同主机间的GPU通信性能显著下降。
200Gbps(25GB/s)接近PCIe Gen4的单向带宽。400Gbps(50GB/s)超越了PCIe Gen4的单向带宽。
因此,在此类配置中使用400Gbps的网卡并不能带来显著优势,因为要充分利用400Gbps带宽需要PCIe Gen5级别的性能支持。
8x NVIDIA H100/8x NVIDIA H800 主机
H100主机内部的硬件拓扑结构
H100主机的整体硬件架构与A100八卡系统的架构非常相似,但也存在一些差异,主要体现在NVSwitch芯片的数量和带宽升级上。
在每个H100主机内部,配置了4颗芯片,比A100配置减少了两颗。
H100芯片采用4纳米工艺制造,底部一行配备了18条Gen4 NVLink连接,从而提供了900GB/s的双向总带宽。
H100 GPU 芯片
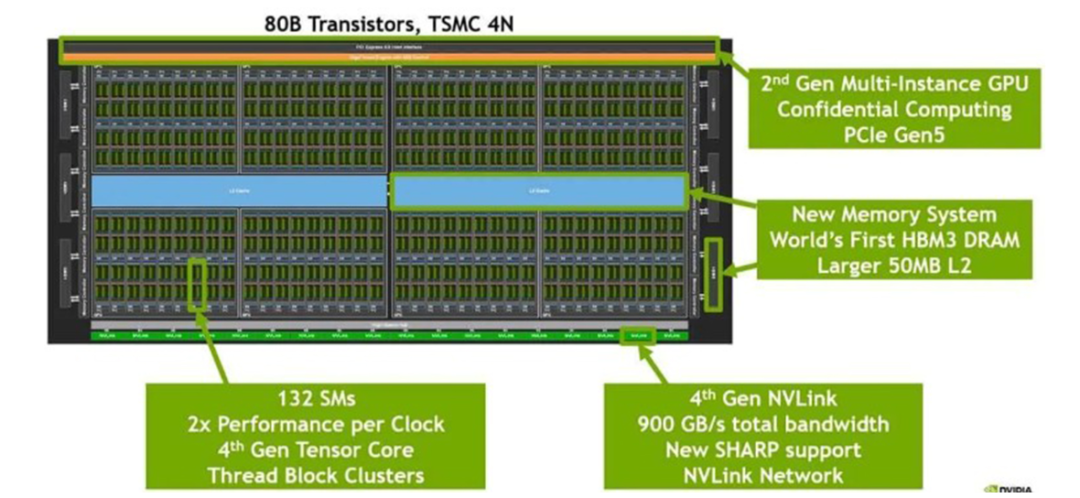
该芯片采用尖端的4纳米工艺制造,表明其采用了先进的制造技术。
芯片底部一排包含18个Gen4 NVLink连接,提供双向总带宽为18条通道 * 每通道25GB/s = 900GB/s。
芯片中央蓝色区域代表L2高速缓存,用于存储临时数据的高速缓冲区。
芯片左右两侧则集成了HBM(高带宽内存)芯片,这些芯片作为图形内存使用,存储图形处理所需的数据。
-
【产品活动】阿里云GPU云服务器年付5折!阿里云异构计算助推行业发展!2017-12-26 3522
-
gpu服务器是干什么的_gpu服务器和普通服务器有什么区别2018-01-06 44024
-
GPU服务器到底是什么?GPU服务器与普通服务器到底有什么区别2020-11-14 9158
-
GPU服务器是什么2022-02-25 6700
-
AI服务器与传统服务器的区别是什么?2023-06-21 3361
-
GPU服务器是什么?2023-08-01 2015
-
gpu服务器是干什么的 gpu服务器与cpu服务器的区别2023-12-02 3618
-
物理服务器对ai发展的应用2023-12-22 1237
-
gpu服务器是干什么的 gpu服务器与cpu服务器的区别有哪些2024-01-30 2580
-
ai服务器是什么架构类型2024-07-02 3923
-
gpu服务器与cpu服务器的区别对比,终于知道怎么选了!2024-08-01 1917
-
GPU云服务器架构解析及应用优势2024-08-14 1524
-
什么是AI服务器?AI服务器的优势是什么?2024-09-21 3862
-
GPU云服务器租用多少钱2024-12-09 1568
-
GPU加速云服务器怎么用的2024-12-26 1379
全部0条评论

快来发表一下你的评论吧 !
