

基于TI TMS320F28M35H52C 的非对称双核 MCU 提高系统性能方案
控制/MCU
描述
1、背景介绍
随着各个行业朝着智能化方向的发展,嵌入式产品对能耗和效率的要求越来越苛刻。特别是在智能电网、工业和医疗等领域,一个产品的核心 MCU 处理器面临多重挑战。比如,一个自动化的马达系统或者分布式工业系统,一方面需要更多的数字信号处理能力来更精确地控制马达,另一方面也需要更多和更高级的网络接口(CAN,Ethernet 或者 Wireless 等)来实现实时的分布式监控或控制功能。再比如图 1,一个太阳能逆变系统,一方面需要 DSP 引擎来实现 DC/AC 或者 DC/DC 的算法,另一方面也需要将多个逆变器通过 Wireless 或者以太网 Ethernet 组成网络,从而实现智能诊断和监控。
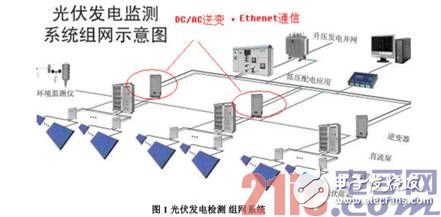
面对这些需求,有两种传统的方案可以解决。一种方案是采用两颗单独的 MCU/DSP,其中一颗 MCU或者 DSP 用于实现数字信号处理或者控制算法,另外一颗 MCU 实现网络协议栈或者图形显示界面等。这类方案的存在诸多缺点,首先两颗 MCU 增加了 PCB 的面积,而且双 MCU 之间的通讯的可靠性和数据吞吐率受到限制,另外,功耗也将显著增加,程序开发者甚至需要维护多个软硬件开发环境。另外一种方案是采用更高主频和更多片内资源的单核 MCU/DSP,分时地完成数据处理和辅助通信或显示功能,这种方案显著增加了系统成本和功耗,最致命的是,当客户的产品需要增加新的功能的时候,工程师需要重新计算 MCU 内核的资源和不同任务所需要的运行时间,需要更多的测试时间,因此不利于扩展和产品维护。
面对种种不足,异构双核架构应运而生,可以很好解决上述问题。事实上,非对称双核架构 MCU 可以将不同的系统任务分配于不同的 MCU 内核,分工精细,并且可以最佳地平衡性能、功耗和成本。两个MCU 内核间的通信可以通过不同的方式来实现,比如分享内存区和消息区,非常简单和易于实现。在下面的章节,本文将以 TI 最新的 Concerto 系列产品 TMS320F28M35H52C 为例,详细阐述非对称异构双核 MCU 的优势,及其为系统带来的性能提升。
2、C2000 Concerto 双核 MCU 的特点
C2000 Concerto 系列 MCU 是 TI 推出的创新性的异构双核产品。Concerto 混合架构通过将业界最好的实时控制功能和通讯功能集成在一个芯片内,提供高性能、高效率和可靠性,从而实现实时控制环路和低延时的快速通讯响应[1]。以下从内核、存储器架构、通讯外设等方面阐述其特点。Concerto 系列 TMS320F28M35H52C 功能框图如下图 2 所示。
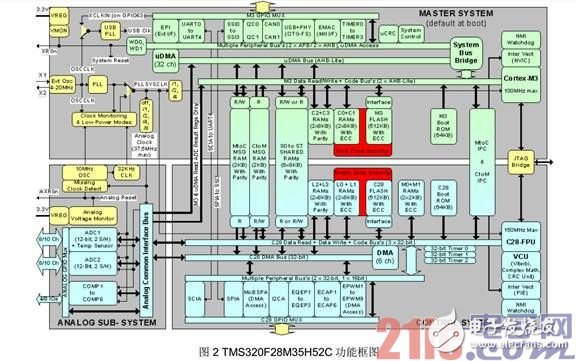
首先是高性能的内核。Concerto 系列 MCU 包含 Cortex-M3 和 C28x 两个内核。Cortex-M3 内核是Concerto 的主系统 Master 子系统内核,主频最高可运行于 125 MHz。Cortex-M3 内核是 32 位的ARM 核,超高的性价比,已经被业界广泛使用,其性能和稳定性也已被用户所广泛接受,非常适用于通讯和事件控制。C28x 是新一代的 32 位 DSP 内核,是 TI 大多数现有的 C2000 产品的内核,最高可运行于 150 MHz,Concerto 中的 C28x 带浮点运算单元(Floating-Point Unit),VCU 协处理器等,性能超强,非常适用于大吞吐量的数据处理。C28x 作为 Control 子系统,宏观上受控于 Cortex-M3 Master 子系统。
其次是优化的存储器架构。如图 2 所示,TMS320F28M35H52C 的 C28x 可支配 512KB 带 ECC 校验的 Flash 存储器,64KB ROM,36KB 带 ECC 校验的 RAM;Cortex-M3 可支配 512KB 带 ECC 校验的Flash 存储器,64KB ROM,32KB 带 ECC 校验的 RAM [3]。在两个内核之间,是共享的外设和存储区。总共 64K 字节的共享 RAM,4K 的消息 RAM。
再次是外设。如图 2 所示,TMS320F28M35H52C 的 C28x 内核可支配 DMA、高速 ADC(3MSPS)、多路高精度的 PWM(24 路 PWM和 16 路高精度 HRPWM)、eCAP、eQEP 等为闭环控制所优化的控制外设;Cortex-M3 内核可支配多个串行接口、以太网、CAN 等工业通讯外设。同时,两个内核还可共享 ADC 等外设,增强整个系统的灵活性。
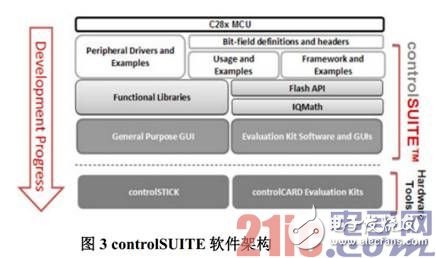
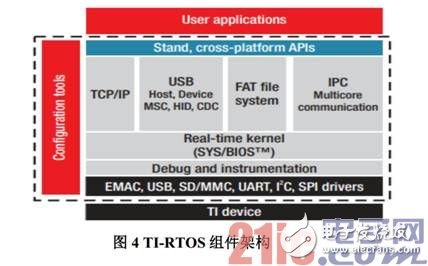
最后是软件架构。如图 3 所示,controlSUITE 是一个集成所有 C2000 MCU 的开发资源和软件包和开发平台,它为 TMS320F28M35H52C 的开发者提供了外设例程、DSP 库、文档、开发板资料。ControlSUITE 还提供免费的全功能实时操作系统 TI-RTOS 平台,如图 4 所示,TI-RTOS 是基于SYS/BIOS 实时内核,集成了稳定的中间件,例如 TCP/IP 协议栈、USB 协议栈、FAT 文件系统、IPC多核通讯组件等。
3、IPC 内核间通信
Cortex-M3 和 C28x 内核之间的通信主要完成两大功能,一是数据通信,二是传递状态和控制信息。IPC(内核间通讯)的数据通信需要较大的 RAM 来支持,而传递状态和控制等信息只需要一系列状态标志位即可。此外,Cortex-M3 侧的 UART4 与 C28x 侧的 SCIA;以及 Cortex-M3 侧的 SSI3 与 C28x侧的 SPIA 在 Concerto 内部实现互联,不需要在芯片外部硬件连接,而是否使能这类功能则有 CortexM3 系统配置。
3.1 Message RAM 内存区
TMS320F28M35H52C 使用 Message RAM 实现 IPC 的数据通信。如图 5 所示,2K 字节的 MTOC Message RAM 用于从 Master (Cortex-M3)子系统向 Control(C28x)子系统传递消息;2K 字节的CTOM Message RAM 用于从 Control 子系统向 Master 子系统传递消息。由于两个子系统都配有 DMA外设,因此,DMA 也可以读写 Message RAM,从而提高系统效率。Message RAM 区通过 RAM 内存的读写权限保证了 Message 的互斥访问,例如,C28x CPU 与 DMA 可以读写访问 CTOM Message RAM 区,而 Cortex-M3 CPU 和 uDMA 只能读访问 CTOM Message RAM。同样,两个内核对于MTOC Message RAM 区的读写访问权限则正好相反。

Message RAM 仅仅作为 IPC 的数据缓存,IPC 还需借助于特定的控制逻辑电路来完成。如图 6 所示,Master 子系统和 Control 子系统都是通过 5 个寄存器来实现 IPC 的逻辑流程控制:IPCACK、IPCSTS、IPCFLG、IPCCLR、IPCSET。这 5 个寄存器都是 32 位,每一个 bit 对应于 IPC 的一个通道,因此最多可实现 32 个通道的握手通信。Bit0 到 Bit3 总共 4 个通道可以触发消息接收方的 IPC 中断,Bit4 到Bit31 共 28 个通道则需要消息接收方的软件查询来获取 Message RAM 中是否收到数据。如果两个内核之间仅仅传递状态和控制信息(例如 RTOS 中的 Semaphore),仅通过以上寄存器便可以实现,而无需 Message RAM 的参与。
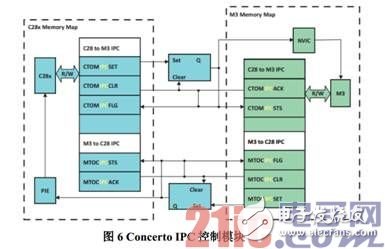
以下通过举例 Master 子系统往 Control 子系统发送一帧数据,来简单介绍 IPC 模块的操作流程。
1. Cortex-M3 先在 MTOC Message RAM 中写入一帧数据;
2. Cortex-M3 置位 MTOCIPCSET(CM3 映射存储器区)的 Bit9,如图 6 所示,此时 MTOCIPCSTS(C28x 映射存储器区)的 Bit9 也将置位;
3. C28x 轮询 MTOCIPCSTS 的 Bit9,查询到 Bit9 已置位;(如果之前的操作是 Bit0 到 Bit3 其中之一, 则将触发 C28x 产生一个 IPC 中断)
4. C28x 读 MTOC Message RAM 中的数据,此时,Cortex-M3 成功将一帧数据发送至 C28x。
3.2 Shared RAM 内存区
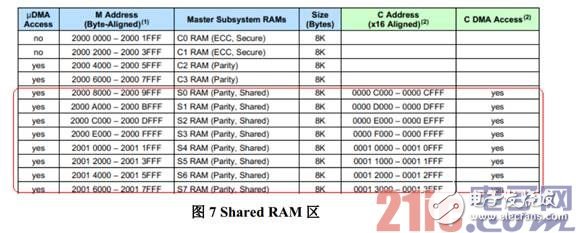
大部分情况下,2K 字节的 IPC Message RAM 区能够满足 C28x 和 M3 子系统之间的数据通信,配合DMA,通信效率也可以进一步提高。如果用户希望一次性在两个子系统传递更大块的数据,另一种方法是通过 Shared RAM 内存。
TMS320F28M35H52C 有一个 64K 字节大小的 Shared RAM 区,总共 8 块 S0-S7,每块 8K 字节大小,如图 7 所示。Cortex-M3 可以设置让任何一块 Shared RAM 区由 C28x 或 M3 主控,比如,映射 S0 至C28x 侧以后,C28x CPU 和 DMA 可以读写 S0,而 M3 和 uDMA 将只能读 S0,不能写入和预取。
假如 Cortex-M3 需要一次性发送 6K 字节的数据到 C28x 侧,它可以先将 Shared RAM 区 S0 映射到本地存储器空间,接着通过 IPC 发送一个标志位给 C28x 来通知其可以将数据取走。
3.3 IPC 的软件驱动
controlSUITE 软件开发包中提供 2 种 IPC 的软件驱动库,IPC Driver 和 IPC_Lite Driver。IPC_Lite Driver 仅使用 IPC 寄存器来实现通信,不需要额外的 RAM,但是用户只能支持一个 IPC 中断服务 ISR,且不支持以队列形式来处理 IPC 请求。IPC_Lite Driver 使用方式如下:
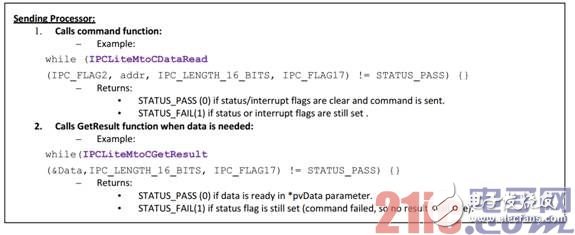

1,主动发起数据请求的内核会首先调用 IPC_Lite Driver 提供的名函数。在这个例子汇总,M3 是发送数据的内核并执行“IPCLiteMtoCDataRead” 函数。
• IPC_FLAG2 是 C28 中断标志,指示 C28 内核一个消息到来。
• IPC_FLAG17 是响应标志,C28 用其指示 M3 核一个命令已经被处理。
• 需要读取数据的 C28 的地址也被作为一个参数传递给 C28 内核。
• 这个函数在 while 循环中被调用的原因是,它可能返回 STATUS_FAIL 并且不会发送信息给C28 直至 MtoC IPC 中断 2 和标志 17 可用, 之后,该函数返回 STATUS_PASS.
2,被动接收数据请求的内核会在 ISR 中解析其 IPCCOM寄存器的命令。这个例子中,C28 MtoCIPCINT2 ISR 知道标志置位,解析 MTOCIPCCOM寄存器的命令,识别出是读数据命令。
3,被动接收数据请求的内核会调用与主动发起数据请求的内核相同的函数名。这个例子中,C28 执行 IPCLiteMtoCDataRead, IPC_FLAG2 作为中断标志参数, IPC_FLAG17 作为状态标志参数。
4,如果接收到命令有效,IPC_Lite 的驱动函数会处理读命令并确认(acknowledges)状态和中断标志。如果接收到的命令无效,则只有中断标志被确认(acknowledged)用来释放中断给后续的命令,而状态标志仍然置位。
IPC Driver 通过在 Message RAM 中建立环形缓冲区,使得多个 IPC 通信命令可以以队列的形式被缓冲,然后逐个处理,并且可以同时支持多个 IPC 中断服务程序 ISR,当然,IPC Driver 需要更多的RAM 来支持。和 IPC-Lite 不同,为了使用 IPC 驱动,需要在 M3 和 C28 的项目中增加一些设置。
第一步是在 M3 和 C28 的链接定位文件(.cmd)中添加 IPC 循环缓冲区和指针段到 CTOM和 MTOC message RAM。如下所示:

第二步,应用程序源码中必须定义并且初始化至少一个 volatile global tIpcController 变量 (为 C28 –M3 IPC 中断使用),如下所示:



1. 主动发起数据请求的内核会首先调用 IPC Driver 提供的一个命令函数。这个例子中,M3 是发起数据请求的内核,执行“IPCMtoCSetBits”函数。
• g_sIpcController1 是 tIpcController 类型的变量,控制 M3 和 C28 IPC 中断通道之间的通信。
• SETMASK_16BIT 是 16-bit 掩码,指示应该被置位的位域。IPC_LENGTH_16_BITS 指示命令操作的数据对象是 16-bits。
• 函数被配置成允许阻塞 “ENABLE BLOCKING”, 意味着函数会一直等待直到 M3 PutBuffer 有空的缓冲区。如果函数被配置成不许阻塞 “DISABLE BLOCKING”, 一旦”Put”缓冲区满,它会立即返回STATUS_FAIL 并且不会发送消息到 C28。如果”Put”缓冲区有空余,函数会返回 STATUS_PASS,
消息被成功发送到 C28.
2. 被动接受数据请求的内核会连续调用 IpcGet 函数来读取 sMessage 结构体里的消息,只要有消息在”Get”缓冲区。在 ISR 中 IpcGet 函数被调用,C28 侧的 tIpcController 变量被用来绑定两个相同的M3 和 C28 的 IPC 中断通道(和 M3 侧用来发送命令的 tIpcController 相同)。
3. 即使被动接收数据的内核没有确认(acknowledged)IPC 中断标志,主动请求数据的内核仍然可以连续发送消息,因为 tIpcController 变量会把消息排队放到”Put”缓冲区(与被动接收数据请求的内核的”Get”缓冲区相同)。被动接收数据请求的内核的 ISR 会连续获取并处理消息,直至”Get”缓冲区为
空。
4、Cortex M3 和 C28x 核的任务分工
Cortex-M3 子系统的优势在于处理事务和管理通讯外设的能力,C28x 内核子系统在实时控制和数据处理方面性能优越。因此,在一个系统中,合理地分配两个子系统的所处理的事务,优化资源的配置是至关重要的。基于 Concerto 的系统,一方面应当最大化地使用 C28x 的 DSP 和实时控制优势,发挥ADC、PWM、C28x 组成的闭环系统的优势;另一方面应将人机界面、通讯协议栈、文件系统等尽可能运行在 Cortex-M3 子系统一侧。下面通过两个应用案例来讨论如何通过合理任务分工来提高系统效率。
4.1 光伏逆变器网络节点
光伏逆变器的主要功能是把光伏面板输出的 DC 直流电逆变为 110V/220V 的 AC 交流电,最终接入电网或者离网输电至用电设备。在一个大功率的光伏发电网络拓扑中,往往有许多个光伏逆变器,这些逆变器需要被监测,控制中心需要实时观测各个光伏逆变器的工作状态。因此,光伏逆变器网络节点的功能主要包括 DC/AC 逆变器和网络连接。如图 9 所示,C28x 子系统(运行于 100MHz)完成MPPT 和 DC/AC 逆变算法。网络连接可以有多种方式,常用的方式包括 Ethernet 以太网、RS485 或CAN 等,TMS320F28M35H52C 的 Cortex-M3 子系统(100 MHz)带 Ethernet、RS485 和 CAN 等接口,支持多种有线和无线连接功能。
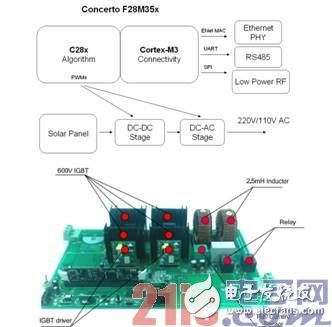
图 8 Solar HV DC-AC Kit
对于 C28x 子系统,采用状态机的设计思路来区别不同的系统状态。不同的状态代表着不同的运行模式,其它的任务能够根据特定的运行模式采取相应的行动。例如,可以采用下面 5 种不同的运行模式。
• Power On Mode: 系统上电后进入 Power On Mode,系统上电后,F28M35H52C1 中的 Cortex-M3内核 boot 程序首先启动,此时 C28x 控制子系统和模拟子系统处于复位状态,需要 M3 主子系统将其从复位状态解除。M3 主子系统设定 M3 和 C28x 内核的时钟频率,由于 M3 和 C28x 的主频之比必须
为整数比,因此 M3 和 C28x 的主频设定只能为 60/60MHz、75/150MHz、100/100MHz。在 M3 和C28x 的主频设定完成之后,需要由 M3 主子系统对整个芯片的外设资源以及 GPIO 进行配置,来决定哪些 GPIO 可以由 C28x 控制子系统进行配置。本系统中 M3 和 C28x 主频设定为 75/150MHz。当所有的初始化操作完成后,系统自动转入到 Standby Mode。
• Standby Mode:所有的 PWM 和继电器被关闭。系统等待启动命令,也检测是否发生错误。
• Soft Start Mode: 接收到启动命令,系统进入软启动模式,PWM 和继电器开启。如果启动成功而且没有错误发生,系统自动进入正常逆变模式。
• Normal Inverter Mode: 该模式下系统输出功率,如果没有错误发生也没有收到关闭命令,系统会一直处于这个模式。
• Fault Mode: 如果发生错误,例如母线过压,系统立即进入 Fault Mode。所有 PWM 输出被封锁,输出继电器被断开。Fault 状态可以被按键或者 GUI清除。清除后,系统会返回到Standby Mode
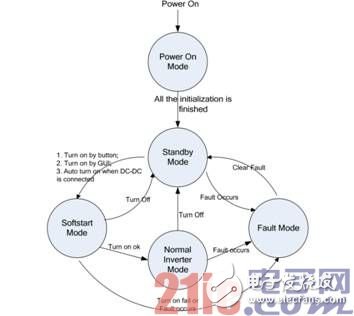
图 90 C28x 端程序系统状态机
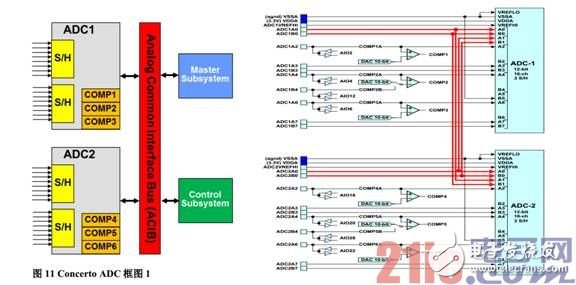
图 101 Concerto ADC 框图
Concerto 系列有两个 12-bit ADC 模块,每个 ADC 模块包含两个采样保持电路,支持同步或者顺序采样模式,3 个带 10-bitDAC 的模拟比较器,模拟信号的输入范围 0V~3.3V( 内部参考)或者VREFHI/VREFLO 比例关系(外部参考)。
图 11 给出了详细的 ADC 配置,TMS320F28M35H52C 的 Cortex-M3 和 C28x 内核都能够访问 ADC的结果寄存器,而且 2 个 ADC 模块共享 4 个模拟输入, Concerto ADC 模块的这个特性允许对关键信号进行安全性验证,提高系统的可靠性。
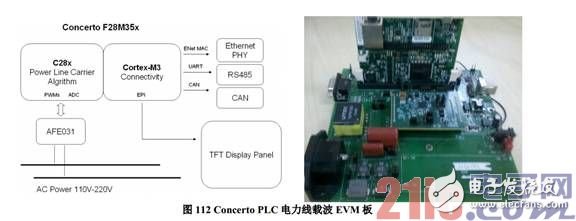
4.2 电力线载波通讯 PLC 智能家居网关
智能家居网关能够将房间内的智能电器以有线或者无线的方式组成网络,集中进行管理。如图 10 所示,TMS320F28M35H52C 的 C28x(运行于 150MHz)主要完成电力线载波通信(Power Line CarrierCommunication)PLC 的 OFDM 物理层算法。Cortex-M3(75MHz)的运行 TCP/IP 协议接入以太网,其次,可选地通过 UART 接口外接 GPRS 模块或者通过 EBI 外扩总线连接 TFT 彩屏用户界面。
5、总结
Concerto C2000 异构双核 MCU 将 C28x DSP 内核与 ARM 公司的 Cortex-M3 内核融合在一起,展示出高效的数据处理、数据通讯和事件管理的强大性能。C28x 和 Cortex-M3 两个子系统分工明确,又通过 IPC 模块巧妙实现了实时高效地核间通讯。在软件方面,controlSUITE 开发平台提供多种组件,包括 TCP/IP 协议栈、IPC 驱动、USB 协议栈、FAT 文件系统等,可帮助用户更快地开发出创新性的产品。
- 相关推荐
- 热点推荐
- mcu
- ti
- tms320f28m35h52c
-
非对称双核MCU的基础知识与重要特点2021-11-01 1607
-
如何采用非对称双核MCU提高系统性能?2021-04-02 2794
-
SOM-TL2837x是一款基于TI TMS320F2837x高端单/双核浮点MCU工业级核心板2020-09-09 1770
-
F28M35H52C1RFPQ F28M35H52C1RFPS F28M35H52C1RFPT请问这三个有什么区别?2020-07-25 1461
-
请问F28M35H52C1中EPI的控制能否由C28核实现?2020-06-09 1511
-
谁有F28M35H52C1RFPT的参考设计2020-06-08 2355
-
基于双核MCU提高系统性能2019-07-04 4405
-
TMS320C6657的编程优化与双核加载2018-08-29 2520
-
如何在F28M35H52C1中调试双核程序?2018-08-28 1400
-
F28M35H52C原理图2015-11-02 599
-
应用非对称双核MCU增强系统性能2012-04-11 1333
-
非对称双核MCU基础知识及核间通信2012-03-26 4089
-
TI DSP TMS320F28x DSP2011-02-26 1093
全部0条评论

快来发表一下你的评论吧 !
