

Google AI Edge Torch的特性详解
描述
作者 / 主任工程师 Cormac Brick,软件工程师 Advait Jain,软件工程师 Haoliang Zhang
我们很高兴地发布 Google AI Edge Torch,可将 PyTorch 编写的模型直接转换成 TFLite 格式 (.tflite),且有着优异的模型覆盖率和 CPU 性能。TFLite 已经支持 Jax、Keras 和 TensorFlow 编写的模型,现在我们加入了对 PyTorch 的支持,进一步丰富了框架选择。
这一新产品现已作为 Google AI Edge 的一部分提供。Google AI Edge 是一套易于使用的工具,包含可直接使用的机器学习 (ML) 任务、构建机器学习流水线的框架,以及运行流行的大语言模型 (LLM) 和自定义模型的能力——所有这些都可在设备上运行。本文是 Google AI Edge 博客连载中的第一篇,用于帮助开发者们构建 AI 功能,并轻松地将其部署至多个平台。
今天发布的 AI Edge Torch Beta 版本包含以下特性:
直接集成 PyTorch
出色的 CPU 性能和初步 GPU 支持
在 torchvision、timm、torchaudio 和 HuggingFace 里的 70 多个模型上得到验证
支持超过 70% 的 PyTorch core_aten 算子
兼容现有的 TFLite 运行时,无需更改部署代码
支持在工作流的多个阶段进行模型探索器 (Model Explorer) 可视化
以 PyTorch 为中心的简洁体验
Google AI Edge Torch 从一开始就致力于为 PyTorch 社区提供卓越的开发体验,API 使用起来感觉非常原生,并提供简便的模型转换路径。
import torchvision
import ai_edge_torch
# Initialize model
resnet18 = torchvision.models.resnet18().eval()
# Convert
sample_input = (torch.randn(4, 3, 224, 224),)
edge_model = ai_edge_torch.convert(resnet18, sample_input)
# Inference in Python
output = edge_model(*sample_input)
# Export to a TfLite model for on-device deployment
edge_model.export('resnet.tflite'))
在底层,ai_edge_torch.convert() 使用 torch.export 集成了 TorchDynamo——在 PyTorch 2.x 中,这个方法用于将 PyTorch 模型导出为标准化的模型形式,从而在不同环境中运行。我们目前的实现支持超过 70% 的 core_aten 算子,这个比例会在构建 ai_edge_torch 1.0 版本的过程中大幅增加。我们还提供了 PT2E 量化的示例,这是 PyTorch2 原生的量化方法,以简化量化工作的流程。我们很期待听到来自 PyTorch 社区的反馈,以进一步改善开发者体验,从而帮助大家更好地把用 PyTorch 打造的新颖体验部署至更多样的设备中。
模型覆盖和性能
在此版本发布之前,许多开发者使用社区提供的转换方法,如 ONNX2TF,在 TFLite 中运行 PyTorch 模型。我们开发 AI Edge Torch 的目标是减少开发过程中的阻力,提供出色的模型覆盖率,并继续完成我们的使命: 在 Android 设备上提供最佳的性能。
在覆盖率方面,我们的测试表明,与现有工作流程 (尤其是 ONNX2TF) 相比,AI Edge Torch 在给定的模型集合上的覆盖率有显著的提高。
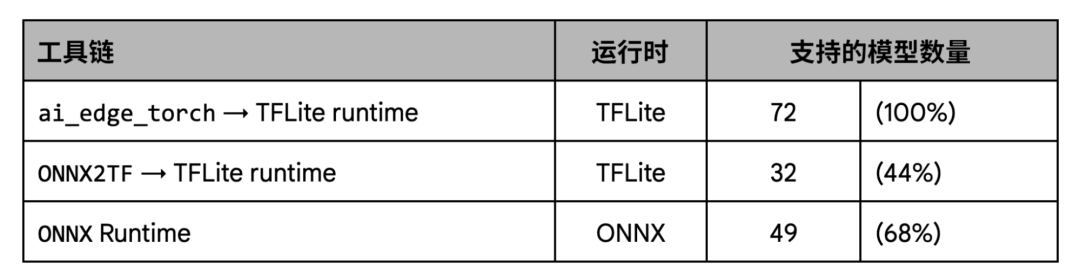
在性能方面,我们的测试显示 AI Edge Torch 与 ONNX2TF 的基准性能表现相当,比 ONNX 运行时相比则有着更好的性能。
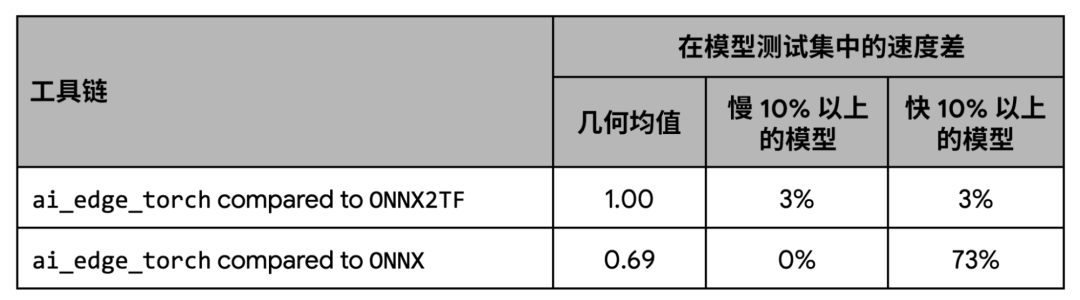
下图显示了在 ONNX 覆盖的模型子集上的每个模型的详细性能:
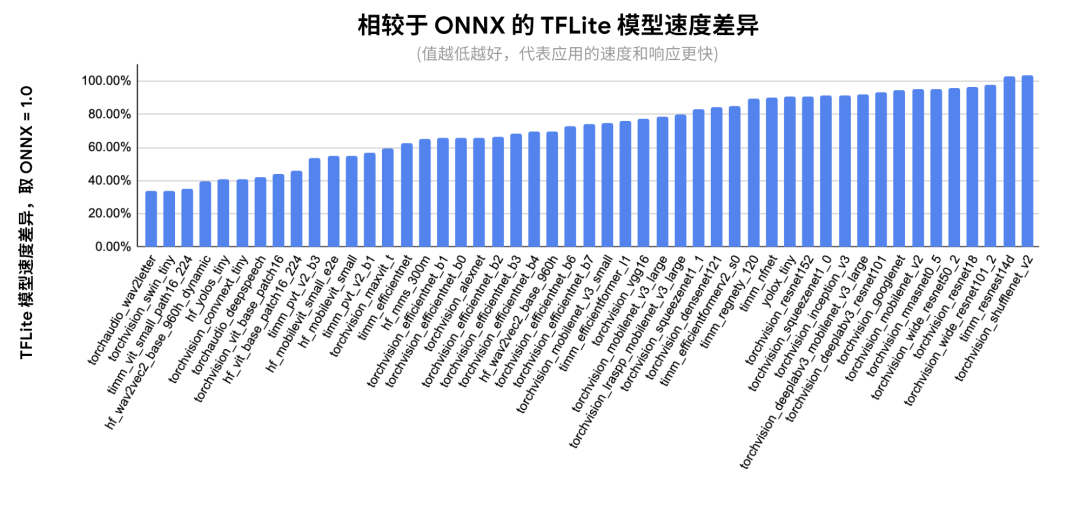
△ 相对于 ONNX 的每个网络的推理延迟。以 Pixel 8 为测试设备,使用 fp32 精度。XNNPACK 固定为 4 个线程以确保复现性,经过 20 次迭代预热后取 100 次运行的均值
早期体验用户和合作伙伴
在过去的几个月中,我们与参与早期体验的合作伙伴们密切合作,包括 Shopify、Adobe 和 Niantic,以改进我们的 PyTorch 支持。ai_edge_torch 已经被 Shopify 团队用来在设备上去除产品图像的背景,这个功能会出现在不久后发布的 Shopify 应用中。
芯片合作伙伴和代理
我们还和 Arm、Google Tensor G3、联发科技、高通、三星 System LSI 这些合作伙伴们一起,提供跨 CPU、GPU 和加速器的硬件支持。我们通过这些合作提高了产品的性能和覆盖率,并在加速器代理上验证了由 PyTorch 生成的 TFLite 文件。
我们也很荣幸地和高通共同宣布新的 TensorFlow Lite 代理,现已开放供所有开发者使用。TFLite 代理是附加的软件模块,可提升在 GPU 和硬件加速器上的执行速度。这个新的 QNN 代理支持我们在 PyTorch Beta 测试集中用到的大多数模型,并提供对高通芯片的广泛支持。通过使用高通的 DSP 和神经处理单元,相比仅使用 CPU 和 GPU 的场景,能明显地提升运行速度 (相较 CPU 平均提升 20 倍,GPU 平均提升 5 倍)。为了方便测试,高通最近还发布了新的 AI Hub。高通 AI Hub 是一个云服务,可以让开发者在一系列 Android 设备上对 TFLite 模型进行测试,并在使用 QNN 代理的设备上提供性能增益的可见性。
下一步
在接下来的几个月中,我们将继续在开放的环境中对产品进行迭代,朝着 1.0 版本努力,包括提升模型覆盖率、改进 GPU 支持,提供新的量化模式。在本系列的第二篇文章中,我们将更深入地介绍 AI Edge Torch 生成式 API,这个 API 能让开发者们在边缘设备中运行自定义生成式 AI 模型,并且提供优秀的性能表现。
我们要感谢所有早期体验用户,正是他们提供的宝贵反馈让我们得以及早发现错误,并确保开发者们获得顺畅的体验。我们还要感谢硬件合作伙伴以及 XNNPACK 生态系统的贡献者,是他们的帮助让我们在如此多样的设备上都能获得优异的性能表现。同时,我们也要感谢广大的 PyTorch 社区在这一路提供的指导和支持。
-
Cadence与Google合作,利用ChipStack AI Super Agent在Google Cloud上扩展AI驱动的芯片设计2026-04-24 4292
-
使用NORDIC AI的好处2026-01-31 1813
-
面向AI与机器学习应用的开发平台 AMD/Xilinx Versal™ AI Edge VEK2802025-04-11 3271
-
在设备上利用AI Edge Torch生成式API部署自定义大语言模型2024-11-14 2422
-
Edge AI工控机的定义、挑选考量与常见应用2024-08-14 1710
-
采用Versal AI Edge系列的边缘ACAP2023-09-13 616
-
如何使用torch 2.0或更高版本创建图像?2023-05-16 564
-
PyTorch中 torch.nn与torch.nn.functional的区别2023-01-11 2187
-
借助 Edge Impulse 实现 AI 开发的民主化2022-12-30 3068
-
Edge AI在深度学习应用中超越云计算2022-07-10 2989
-
Google掌舵人:打电话AI是一次非凡突破2020-05-12 2155
-
Google之后 微软宣布暂停Chromium Edge版本更新2020-03-21 2246
-
一文看懂谷歌的AI芯片布局2018-11-29 1317
-
EDGE技术详解2010-04-10 1819
全部0条评论

快来发表一下你的评论吧 !
