

如何构建及优化GPU云网络
描述
并从计算节点成本优化、集群网络与拓扑的选择等方面论述如何构建及优化GPU云网络。
Part 1:Compute Fabric 计算节点的选型
计算节点作为AI算力中心的核心组成部分,其成本在建设报价中占据极大比重。初始获取的HGX H100物料清单(BoM)通常采用顶级配置,价格不菲。
值得注意的是,HGX与NVIDIA的系统品牌DGX不同,它作为一个授权平台,允许合作伙伴根据需求定制GPU系统。针对这一特点,我们可以从以下几方面着手,合理优化成本,以适应业务实际需求;
默认 HGX H100 机箱 物料报价清单

来源:SemiAnalysis
选择中端CPU
LLM大型语言模型训练主要依赖于GPU的密集计算能力,对CPU的工作负载要求不高。CPU在此过程中承担的角色较为简单,包括但不限于使用PyTorch进行GPU进程控制、网络初始化、存储操作以及虚拟机管理程序的运行。选取一款中端性能的CPU例如Intel CPU,可以确保NCCL性能和虚拟化支持方面表现更为出色,且系统错误率较低。
RAM 降级到 1 TB RAM 同样是计算节点中相对昂贵的部分。许多标准产品都具有 2TB 的 CPU DDR 5 RAM,但常规的AI工作负载根本不受 CPU RAM 限制,可以考虑减配。 删除 Bluefield-3 DPU
Bluefield-3 DPU最初是为传统 CPU 云开发的,卖点在于卸载CPU负载,让CPU用于业务出租,而不是运行网络虚拟化。结合实际情况,奔着GPU算力而来的客户无论如何都不会需要太多的 CPU 算力,使用部分 CPU 核心进行网络虚拟化是可以接受的。此外Bluefield-3 DPU 相当昂贵,使用标准 ConnectX 智能网卡完全可满足网络性能所需。综合考虑前述几项成本的优化,已经可为单个服务器降低约5%的成本。在拥有 128 个计算节点的 1024 H100 集群中,这个比率背后的金额已经相当可观。
英伟达官网对Bluefiled-3和CX智能网卡的应用解释:BlueField-3 适用于对数据处理和基础设施服务有较高要求的场景,如云计算、数据中心等;ConnectX-7 则更适合需要高速网络连接的应用,如高性能计算、人工智能网络等。
减少单节点智能网卡数量(请谨慎选择)
标准物料清单中,每台 H100 计算服务器配备八个 400G CX-7 NIC,单服务器的总带宽达到 3,200Gb/s。如果只使用四块网卡,后端计算网的带宽将会减少 50%。这种调整显而易见可以节约资金,但多少会也对部分AI工作负载性能造成不利影响。
AI智能网卡Smart NIC主要解决的问题是网络传输上无法线性传输数据问题,以及卸载更适合在网络上执行的业务,更适用于对网络传输要求较高的AI网络基础设施。智能网卡作为后端网络的重要组件,配合其他硬件设备(交换机与光模块等)共同解决大规模网络拥塞死锁、丢包及乱序等一系列网络传输的问题。因此,我们不建议在AI工作负载网络下减少智能网卡的数目以达到避免网络传输故障的可能。
Kiwi SmartNIC 产品介绍
Kiwi小编将于近期为大家讲述AI智能网卡与DPU的主要区别,敬请期待。
Part 2:集群网络的选型
集群网络是继Compute计算节点之后的第二大成本来源。本文举例的 NVIDIA H100 集群有三种不同的网络: 后端网络(计算网,InfiniBand 或 RoCEv2):用于将 GPU 之间的通信从数十个机架扩展到数千个机架。该网络可以使 InfiniBand 或 Spectrum-X 以太网,也可以使用其他供应商的以太网。 前端网络(业务管理和存储网络): 用于连接互联网、SLURM/Kubernetes 和网络存储以加载训练数据和Checkpoint。该网络通常以每 GPU 25-50Gb/s 的速度运行,满配八卡的情况每台GPU服务器的带宽将达到 200-400Gb/s。
带外管理网络 :用于重新映像操作系统、监控节点健康状况(如风扇速度、温度、功耗等)。服务器上的BMC、机柜电源、交换机、液冷装置等通常连接到此网络以监控和控制服务器和各种其他 IT 设备。
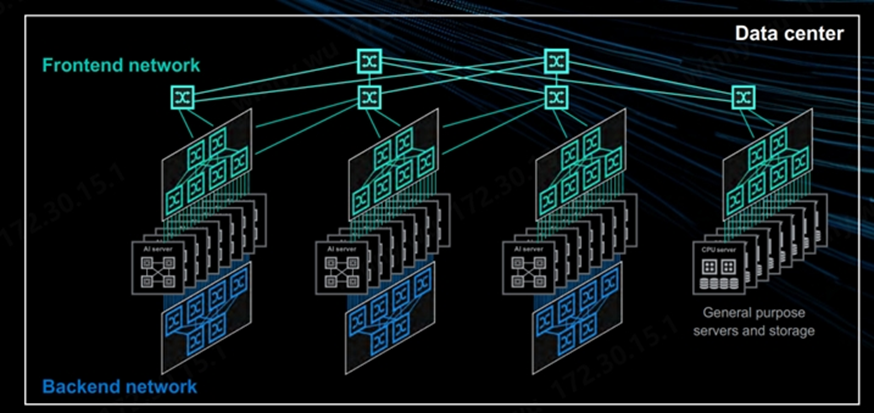
来源:Marvell ,AI集群网络
默认 HGX H100 集群网络物料报价清单

来源:SemiAnalysis
计算网络:RoCEv2替代IB
与以太网解决方案相比,NVIDIA 提供的InfiniBand无疑更昂贵,但部分客户会认为以太网性能相对偏低,这主要是因为以太网需要进行必要的无损网络参数配置并且针对性调优才能发挥集合通信库的性能。
然而,不过从对业务性能的影响角度看,目前在万卡以下的AI网络技术背景下使用IB或是RoCEv2作为后端计算网并没有太多差异。这两类网络在千卡级别的集群规模下经过调优都可以实现相对无损的网络传输。以下图示主要基于大规模集群条件下IB和RoCEv2的共同点与差异点。

IB VS RoCEv2主要区别
与此同时,随着远程直接内存访问(RDMA)被普遍应用,现在越来越多的关注点转向了将开放标准、广泛采用以太网用于大规模算力网络场景。与InfiniBand相比,以太网降低了成本和复杂性,并且没有可扩展性的限制。
AMD近期提及以太网据最新实例统计,在后端网络,相比InfiniBand,以太网RoCEv2是更好的选择,具有低成本、高度可扩展的优势,可将TCO节省超过50%,能够扩展100万张GPU。而InfiniBand至多能扩展48000张GPU。
无论是在AI训推的测试场景,还是头部云厂商已有的组网案例中,AI以太网都有了大量成功案例可供参考。据统计,在全球 TOP500 的超级计算机中,RoCE和IB的占比相当。以计算机数量计算,IB 占比为 47.8%, RoCE 占比为 39%; 而以端口带宽总量计算,IB占比为 39.2%,RoCE 为 48.5%。目前包括奇异摩尔在内的AI产业链成员相信有着开放生态的高速以太网将会得到快速发展。
前端网络:合理降低带宽速率
NVIDIA 和一些OEM/系统集成商通常会在服务器提供 2x200GbE 前端网络连接,并使用 Spectrum Ethernet SN4600 交换机部署网络。我们知道,这张网络仅用于进行存储和互联网调用以及传输基于 SLURM,Kubernetes 等管理调度平台的带内管理流量,并不会用于时延敏感和带宽密集型的梯度同步。每台服务器 400G 的网络连接在常规情况下将远超实际所需,其中存在一些成本压缩空间。
带外管理网络:选用通用的以太网交换机
NVIDIA 默认物料清单一般包括 Spectrum 1GbE 交换机,价格昂贵。带外管理网络用到的技术比较通用,选择市场上成本更优的 1G 以太网交换机完全够用。
Part 3:计算网络拓扑的架构优化
GPU集群计算网将承载并行计算过程中产生的各类集合通信(all-reduce,all-gather 等),流量规模和性能要求与传统云网络完全不同。
NVIDIA 推荐的网络拓扑是一个具有无阻塞连接的两层胖树网络,理论上任意节点对都应该能同时进行线速通信。但由于存在链路拥塞、不完善的自适应路由和额外跳数的带来的通信延迟,真实场景中无法达到理论最优状态,需要对其进行性能优化。
轨道优化(Rail-optimized)架构
举例来说:Nvidia的DGX H100服务器集成了八个通过NVSwitches连接的H100 GPU,实现了7.2 TBps的无阻塞内部带宽。而GB200 NVL72计算机则更进一步,以每GPU 14.4 TBps的速度将72个B200超级芯片通过第五代NVLink技术连接在机架内。(相关阅读:预计OCP成员全球市场影响力突破740亿美元——OCP 2024 Keynote 回顾)
这里将这些具备TB级内部带宽的平台统称为高带宽域”HBD”。Rail优化网络作为一种先进的互联架构被广泛应用。然而,尽管Rail优化网络在降低局部通信延迟方面表现出色,但它依然依赖于Spine交换机层来连接各个Rail交换机,形成完全二分法的Clos网络拓扑。这种设计确保了不同HB域中的GPU能以TB级别速率进行高效通信。
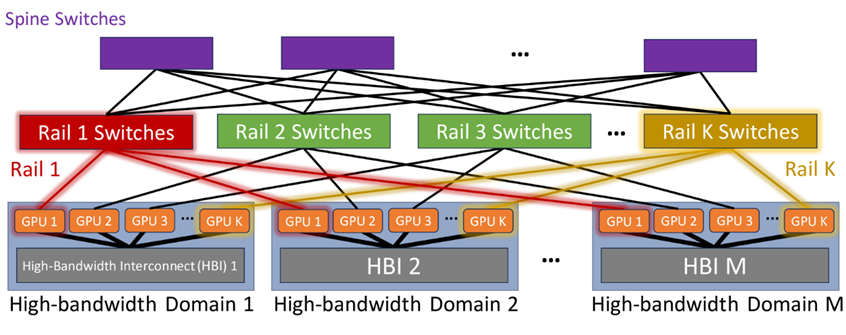
(Source:https://arxiv.org/html/2307.12169v4)
轨道优化网络的主要优势是减少网络拥塞。因为用于 AI 训练的 GPU 会定期并行底发送数据,通过集合通信来在不同GPU之间交换梯度并更新参数。如果来自同一服务器的所有 GPU 都连接到同一个 ToR 交换机,当它们将并行流量发送到网络,使用相同链路造成拥塞的可能性会非常高。如果追求极致的成本优化,可以试用一种Raily-Only单层轨道交换机网络。
Raily-Only单层轨道交换机网络
Meta在近期就发表过类似的文章,提出了一种革命性思路-抛弃交换机Spine层。
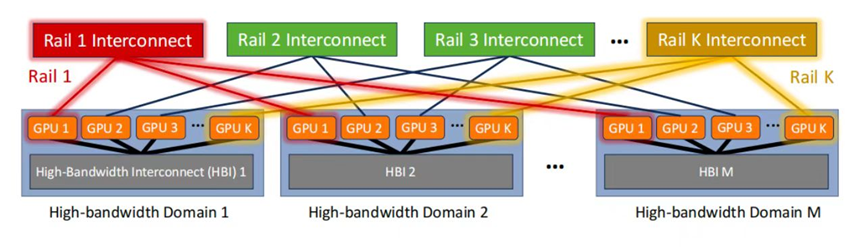
(Source:https://arxiv.org/html/2307.12169v4)
相较于传统的Rail-optimized GPU集群,Rail-only网络保留了HB域和Rail交换机,但巧妙地移除了Spine交换机。这一变革确保了同一网络内的GPU对之间的带宽保持不变,同时实现了网络Fabric的精简与成本的降低。具体来说,通过移除Spine交换机并重新配置Rail交换机与GPU之间的链路,他们构建了一个专用且独立的Clos网络,每个Rail独立运行。由于Rail交换机拥有富余的下行端口直接连接GPU,相较于Rail-optimized网络,Rail-only设计显著减少了所需交换机的数量,从而降低了整体网络成本。
在Rail-only网络中,不同HBD域之间的直接连通性被移除,但数据仍可通过HBD域内的转发实现跨域通信。例如, GPU 1(Domain 1)向GPU 2(Domain 2)发送消息时,首先通过第一个HBD域到达Domain 2的某个GPU,再经网络传输至最终目的地。
确定合适的超额订阅率 轨道优化拓扑的另一个好处可以超额订阅(Oversubscription)。在网络架构设计的语境下,超额订阅指的是提供更多的下行容量;超额订阅率即下行容量(到服务器/存储)和上行带宽(到上层Spine交换机)的比值,在 Meta 的 24k H100 集群里这个比率甚至已经来到夸张的7:1。
通过设计超额订阅,我们可以通过突破无阻塞网络的限制进一步优化成本。这点之所以可行是因为 8 轨的轨道优化拓扑里,大多数流量传输发生在 pod 内部,跨 pod 流量的带宽要求相对较低。结合足够好的自适应路由能力和具备较大缓冲空间的交换机,我们可以规划一个合适的超额订阅率以减少上层Spine交换机的数量。
但值得注意的是,无论是IB还是RoCEv2,当前还没有一个完美的方案规避拥塞风险,两者应对大规模集合通信流量时均有所不足,故超额订阅不宜过于激进。现阶段如果是选用基于以太网的AI网络方案, 仍推荐1:1的无阻塞网络设计。
多租户隔离
参考传统CPU云的经验,除非客户长期租用整个GPU集群,否则每个物理集群可能都会有多个并发用户,所以GPU云算力中心同样需要隔离前端以太网和计算网络,并在客户之间隔离存储。基于以太网实现的多租户隔离和借助云管平台的自动化部署已经有大量成熟的方案。如采用InfiniBand方案,多租户网络隔离是使用分区密钥 (pKeys) 实现的:客户通过 pKeys 来获得独立的网络,相同 pKeys 的节点才能相互通信......
关于我们
AI网络全栈式互联架构产品及解决方案提供商
奇异摩尔,成立于2021年初,是一家行业领先的AI网络全栈式互联产品及解决方案提供商。公司依托于先进的高性能RDMA 和Chiplet技术,创新性地构建了统一互联架构——Kiwi Fabric,专为超大规模AI计算平台量身打造,以满足其对高性能互联的严苛需求。
我们的产品线丰富而全面,涵盖了面向不同层次互联需求的关键产品,如面向北向Scale out网络的AI原生智能网卡、面向南向Scale up网络的GPU片间互联芯粒、以及面向芯片内算力扩展的2.5D/3D IO Die和UCIe Die2Die IP等。这些产品共同构成了全链路互联解决方案,为AI计算提供了坚实的支撑。
奇异摩尔的核心团队汇聚了来自全球半导体行业巨头如NXP、Intel、Broadcom等公司的精英,他们凭借丰富的AI互联产品研发和管理经验,致力于推动技术创新和业务发展。团队拥有超过50个高性能网络及Chiplet量产项目的经验,为公司的产品和服务提供了强有力的技术保障。我们的使命是支持一个更具创造力的芯世界,愿景是让计算变得简单。奇异摩尔以创新为驱动力,技术探索新场景,生态构建新的半导体格局,为高性能AI计算奠定稳固的基石。
-
新手小白怎么学GPU云服务器跑深度学习?2024-06-11 2450
-
可以手动构建imx-gpu-viv吗?2025-03-28 740
-
【产品活动】阿里云GPU云服务器年付5折!阿里云异构计算助推行业发展!2017-12-26 3522
-
AI开发者福音!阿里云推出国内首个基于英伟达NGC的GPU优化容器2018-04-04 2935
-
请问Mali GPU的并行化计算模型是怎样构建的?2021-04-19 2351
-
如何构建神经网络?2021-07-12 2026
-
基于云计算的通信网络优化2017-10-09 1100
-
云存储内容分发网络中的能耗优化方法2017-12-17 986
-
使用云监控实现GPU云服务器的GPU监控和报警(下)-云监控插件监控2018-07-23 595
-
基于GPU的稀疏矩阵存储格式优化综述2021-06-11 1179
-
云承载网方式构建新型网络--云专线2022-10-09 1377
-
GTC23 | NVIDIA 携手谷歌云提供强大的全新生成式 AI 平台,基于新款 L4 GPU 和 Vertex AI 构建2023-03-23 1619
-
芯动科技与云玑信息达成战略合作共筑GPU云桌面新征程2023-06-08 2010
-
应用NVIDIA Spectrum-X网络构建新型主权AI云2024-07-26 1988
-
GPU加速云服务器怎么用的2024-12-26 1381
全部0条评论

快来发表一下你的评论吧 !
