

FPGA协处理器案例 FPGA协处理器为HPC加速
可编程逻辑
描述
随着计算机技术的发展,人们开始把它应用到越来越多的领域,例如金融分析、科学计算、网络服务应用、医疗成像等等。虽然这些不同领域有着各异的应用程序和算法,但对于高性能的计算机而言,它们共同的需求就是,对程序要有强大的执行效率,并且能够实现较快的计算速度。
为了提高HPC的计算能力,在最近的几年中,人们开始把其他各种高性能架构开始向机群系统转移。然而,目前的机群系统大多还是传统的CPU,为了追求计算能力,仅仅是不停的增加计算节点,最终服务器会堆到机房外面。
如果在HPC系统中的计算节点上加入FPGA(现场可编程门阵列)作为协处理器,通过对FPGA进行特定程序算法优化,可以大大提高对特定应用程序的执行效率,同时还可以大大降低系统的功耗,并降低系统TCO。
随着主流服务器芯片厂商中AMD和Intel先后开放了CPU接口总线IP核,使得FPGA同CPU总线直接接口变得更加容易,而不需要再采用IO接口进行设计专门的协处理IO卡。目前已经有大量的厂商开始提供相关的协处理器。
HPC变迁趋势和机群架构的新问题
对于高性能计算(HPC),其特点是计算能力强,一般为特别设计的超级计算机。之前的超级计算机架构多是SMP、MPP、SMD等,图1所示为TOP500中HPC的架构变迁。
集群(Cluster)技术是近几年兴起的发展高性能计算机的一项技术,采用Cluster体系结构集群系统,具有可自由伸缩、高度可管理、高可用、高性能价格比等诸多优点,从图1中我们可以看到机群系统逐渐在HPC应用上取代MPP开始占据主流位置。
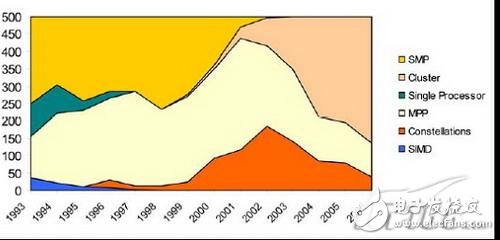
图1 TOP500中系统架构发展情况
虽然机群系统有着上述种种优势,但由于使用了通用的处理器,随着应用对计算能力需求的日益增加,人们不得不被动增加计算结点数目,增加CPU数目来应对计算能力需求的提升。目前的机群系统从原来的几十个计算结点,到现在的成百上千个结点,甚至到不远的将来上万个计算结点,机群系统的不足也随之日趋明显。主要体现在:第一、受机柜高度和传统1U机箱的限制,计算密度比较疏松,而且密度无法突破;第二、安装维护工作量和成本过大;第三、对于大规模机群,功耗日趋成为瓶颈;第四、智能而有效的管理监控成为大规模机群系统新的挑战。所有这些问题都会导致数据中心的整体拥有成本的增加(TCO),这对于长期运营的数据中心而言,是最不想看到的。
而最大的问题在于,对于所有的应用而言,都采用同样的CPU进行运算处理,而像金融分析、生物计算、科学计算,对CPU资源的需求是不同的,因此采用同样的系统,就不能够实际获得机群系统所标称的性能。
目前,人们开始寻找一种替代方式,可以看到的是采用基于FPGA的协处理器来加速应用软件的关键算法执行。这种方式类似于以前提出过的在C++代码中的内层循环采用汇编语言来直接编写,以优化关键程序运行。
相对于目前的X86处理器而言,FPGA一般都运行在比较低的时钟频率下,优势在于有着较高的内存带宽、突出的并行处理能力和出色的根据应用环境的硬件定制化能力。如果同在服务器上增加一颗处理器/内核比较,仅仅在服务器上增加一颗FPGA的协处理器,一般情况下性能可以提高2至3倍,而功耗则可以降低40%,根据应用情况进行算法优化的话,最大可以提高性能达10倍。
FPGA协处理器为HPC加速
正如上文所言,目前HPC应用涵盖了多个领域,有着不同的计算需求。例如在商业数据分析和基因测序中,要进行大量的数组运算、线形数据匹配、逻辑测试等等,而对于医疗成像、计算化学而言,其主要工作是同步映射、过滤等等。这些不同的应用需要不同的数学逻辑操作以及有效的内存连接读取等。
通用的CPU、专用的图像处理CPU(目前称之为GPU)或网络处理CPU,都无法为HPC应用提供一个可选的通用解决方案。而FPGA作为一个可重构计算引擎,可以在软件控制下进行硬件单元优化工作,来满足不同HPC应用需求,从而提供计算效率。从某种程度上说,采用基于FPGA协处理器的可重构计算硬件平台,可以有可能让HPC在各种应用软件下达到很高的效率。
FPGA通过把高性能计算算法中固有的并行运算部分硬件化来实现HPC应用加速。其实这种并行可分为多个等级,在机群计算中在多个CPU上进行任务的多线程分配我们可以称之为“任务级并行”。第二级并行我们称之为“指令并行”,传统的CPU支持数量有限的指令并发处理,就是CPU指令流水线的管道数或者发射数比较有限。而FPGA则可以提供很多管道,也就是说可以同时并行执行大量的指令。“数据并行”是FPGA很容易实现的第三级并行处理能力,FPGA的结构非常容易实现并行操作。因而,通过配置,它可以同时执行大量的数据吞吐操作,在这种情况下,该设备相当于多个传统CPU在同时工作。
如果实现上述三种级别的并行处理,一个200Mhz的FPGA处理能力将远远超过一个3Ghz的通用CPU,然而功耗仅仅是后者的1/4。例如在生物计算中,FPGA在处理DNA基因排序上能往往能够比通用CPU加速50倍到100倍;而在医疗CT的2D/3D图像处理上能够加速10倍左右;而对与一些通用的算法如FFT,一般情况下FPGA的加速至少可以达到10倍以上。
一个标准FPGA协处理器的例子
本文以XtremeData公司的协处理器产品为例,介绍其应用环境及工作流程。图二是XtremeData 公司的x86 FPGA 协处理器实物以及应用平台情况。从图中可以看出,该协处理器产品可以直接放置在普通的4路或者两路Opteron系统上,该系统可以是机架式服务器或刀片产品。
该协处理器模块同CPU管教兼容,同时可以直接使用板上连接在协处理器上的内存条,或者通过HT总线使用其他CPU上连接的内存条。这种结构有很大的优势,主板可以不用作任何改动,也就是说在普通的服务器上可以即插即用,同时还可以直接利用主板资源,并获取很大的HT总线带宽和低延迟。
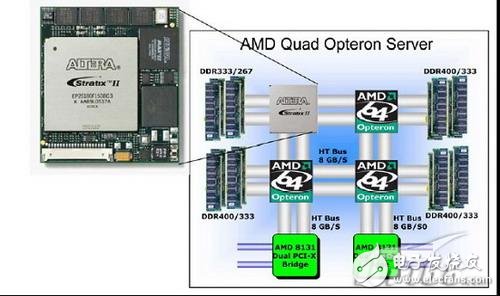
图2 典型协处理器应用架构
其工作原理把适用于该芯片的算法库安装在主机上,根据应用不同,主机上的GUI可以在线配置和更改FPGA内硬件进行不用算法的优化。当然,前提是对于各种HPC应用都要实现完成算法库的编写,并转换成FGPA可以识别的硬件描述语言库,通过加载该语言库,可更改FPGA内部硬件结构,实现应用程序的硬件加速。图3为系统工作流程。
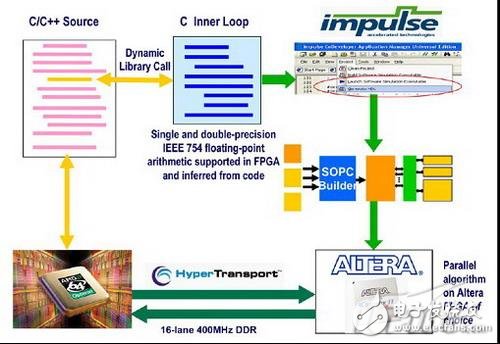
图3 协处理器配置和实现过程
在执行过程中,对于并行性较强、浮点运算需求较高的计算可以通过后HT总线丢给协处理器进行计算,并持续获取计算结果,主CPU主要负责IO处理以及程序调度工作,从而实现协处理器的加速工作。
CPU 厂商持开放态度
CPU厂商目前对协处理器的出现并没有持抵制态度,而是比较支持协处理器的开发。
AMD率先提出Torenza协处理平台,允许第三方处理器与Opteron合作,开放相关接口。之后,Intel在IDF上也提出了自己的系统架构开放计划。Intel高级副总裁Pat Gelsinger宣布,Intel将向Xilinx等第三方FPGA生产商开放前端总线(FSB)授权,以便他们的芯片能通过前端总线和内存控制器 (MCH)的直连与Intel处理器协同工作。如同AMD的HyperTransport总线,Intel的前端总线授权也能让各种加速单元加入一个高带宽、低延迟的总线,从而在Intel系统中与MCH直接相连。
至此,两个通用处理器的巨人对协处理器都抱着支持和看好的态度,大大方便了第三方厂商进行协处理器同通用处理器的接口的开发工作。
总之,从市场来看,目前IBM 的cell、美国的Cleaspeed、DRC、Mitrionics和Celoxic等公司都有相应产品提供。在目前的应用中,Sun公司在为东京理工大学制造的超级计算机就采用了ClearSpeed的协处理器卡进行了加速,Cray公司目前在超级计算机上也有应用。
不过,该技术从目前的情况来看还不是很成熟,距离大规模商业应用还有一定的距离。主要问题在于:不同的HPC领域应用算法各异。而作为可重构计算的 FPGA协处理器,对于不同的算法都需要通过硬件描述语言解释和实现,需要进行大量的算法库的工作。而目前没有公司能够提供足够多的IP核供使用,只能在少数应用上进行FPGA协处理器的加速。当然,由于Linepacke是HPC的主要测试软件,而各家公司的产品都可以加速Linpake的性能测试。
从长远看来,由于FPGA可重构的协处理器有着上文描述的种种优势,所以在将来的HPC应用中,解决的不同算法的硬件描述转化的问题后,将会得到大量的应用。
-
FPGA协处理的优势有哪些?如何去使用FPGA协处理?2023-10-21 3024
-
FPGA协处理器的优势2011-09-29 6267
-
【FPGA干货分享六】基于FPGA协处理器的算法加速的实现2015-02-02 3725
-
采用FPGA的协处理器来简化ASIC仿真2019-07-23 1565
-
举例说明FPGA作为协处理器在实时系统中有哪些应用?2021-04-08 1508
-
为什么FPGA协处理器可以实现算法加速?2021-04-13 2710
-
请问FPGA协处理器有哪些优势?2021-05-08 1832
-
简述协处理器发展历程及前景展望2010-01-02 595
-
为性能加速的空间图像处理开发FPGA协处理器2010-04-27 552
-
采用FPGA协处理的无线子系统2010-08-11 890
-
基于FPGA协处理器的汽车信息娱乐系统设计2017-12-07 2945
-
手机上的协处理器有什么作用_苹果协处理器是干什么的2018-04-24 23456
-
使用协处理器加速器的方法介绍2018-11-30 5043
-
采用FPGA协处理器实现算法加速教程2021-09-28 5133
-
基于FPGA协处理器的算法及总线连接2022-10-27 1432
全部0条评论

快来发表一下你的评论吧 !
